



 本文探讨了神经网络在处理多标签分类问题时的概念和方法。与单标签分类不同,多标签问题允许每个样本拥有多个正确标签。针对这种情况,可以使用sigmoid激活函数替代softmax,通过设定阈值确定分类。在数据预处理时,标签通常转化为one-hot编码,并可以选择不同的损失函数,如binary_crossentropy。
本文探讨了神经网络在处理多标签分类问题时的概念和方法。与单标签分类不同,多标签问题允许每个样本拥有多个正确标签。针对这种情况,可以使用sigmoid激活函数替代softmax,通过设定阈值确定分类。在数据预处理时,标签通常转化为one-hot编码,并可以选择不同的损失函数,如binary_crossentropy。
笔记:神经网络多标签分类问题
一、概念
多标签和多分类的概念,多标签是针对样本而言的,指的是一个样本包含多个分类标签,比如,在做猫狗分类的时候,一张图像既包含猫咪,又包含狗狗,那么他就有两个标签;与之相对的为单标签,指的是该样本只包含一个标签;

而多分类是针对神经网络模型而言的,与之相对的为二分类,多于两个分类数,我们习惯上称之为多分类;指的是神经网络的类别数有多个;
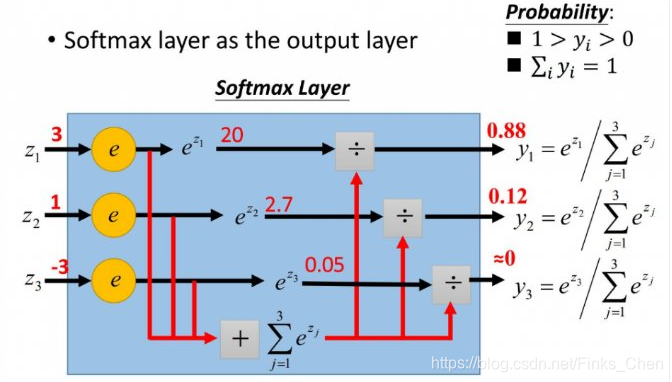
神经网络的应用当中,分类问题是最简单的,通常针对单标签问题,不管它是几分类问题,我们都可以用softmaxt来计算每一个类别的概率值;
但是,针对多标签问题,很明显这样就不妥当了;因为神经网络是一个拟合标签向量的过程,理想状态下,输出值和标签相等,误差为0; 如果是一个多标签问题,目标值为 [1,1,0];那么, 通过softmax可计算不出来这个结果,因为softmax计算方式是计算概率,确保了所有类别的和为1;
二、方法
1)激活函数
对于多分类问题,不能用softmax来计算,我们不妨把它看做一个回归过程,直接在输出层接上一个sigmoid激活函数;将输出值压缩到01之间, 如果包含该标签,那么就将输出值往1上面靠,如果不包含该标签,那么久往0上靠;
这样问题就简单化了,最终我们训练一个模型,可以使用阈值来确定最终分类类别,当他大于某一个阈值,比如0.8;我们可以认为它是靠近1的,从而包含该类,如果小于该阈值,则不包含该类别;
2)数据调整方式
训练的标签设定,转变成one-hot像是,包含该类别的索引位置上为1,不包含的为0;这个时候可以不用添加负样本标签也可以添加负样例标签;举个例子:需要识别猫,狗和其他,样本标签设置为[1,1]; 表示第一个索引为猫,包含,第二个索引为狗,包含;或者[0,1,1]增加一个其他类别;推荐第一种;
3)损失函数选择
因为需要对每一个单独的的神经元进行计算,求累加损失值;keras中通常选择 binary_crossentropy(y_true, y_pred);
实例代码:
model = Sequential()
model.add(Embedding(self.max_feature, self.embedding_dim, input_length=self.maxlen))
model.add(Dropout(0.2))
model.add(Conv1D(filters=256, kernel_size=3, padding='valid', activation='relu', strides=1))
model.add(GlobalMaxPooling1D())
model.add(Dense(units=256))
model.add(Dropout(0.2))
model.add(Activation(activation='relu'))
model.add(Dense(units=self.numclass, activation="sigmoid"))
🍅

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









