



作业:
- 尝试在cifar10对比如下其他的预训练模型,观察差异,尽可能和他人选择的不同
- 尝试通过ctrl进入resnet的内部,观察残差究竟是什么
1.数据预处理
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms, models
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import os
# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# 1. 数据预处理(训练集增强,测试集标准化)
train_transform = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),
transforms.RandomRotation(15),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(
root='./data',
train=True,
download=True,
transform=train_transform
)
test_dataset = datasets.CIFAR10(
root='./data',
train=False,
transform=test_transform
)
# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)2.定义ResNet50模型
def create_resnet50(pretrained=True, num_classes=10):
model = models.resnet50(pretrained=pretrained)
# 修改最后一层全连接层
in_features = model.fc.in_features
model.fc = nn.Linear(in_features, num_classes)
# 调整第一层卷积以适应CIFAR-10的32x32图像
#model.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
#nn.init.kaiming_normal_(model.conv1.weight, mode='fan_out', nonlinearity='relu')
return model.to(device)3.冻结/解冻模型层的函数
冻结层的作用
-
迁移学习效率:预训练模型(如 ImageNet 上训练的 ResNet)的卷积层已经学习到了通用的图像特征(边缘、纹理、形状等)。在处理新任务(如 CIFAR-10 分类)时,可以利用这些已有知识,只训练最后的全连接层来适应新的分类标签,从而显著减少训练时间和数据需求。
-
防止过拟合:对于小数据集,如果从头开始训练整个模型,很容易过拟合。冻结底层卷积层可以避免这些已经学习到的特征被破坏。
-
分阶段训练:实现了两阶段训练策略:
- 第一阶段(前 5 个 epoch):冻结卷积层,只训练全连接层。这允许模型先适应新的分类任务。
- 第二阶段(5 个 epoch 后):解冻所有层,微调整个模型。此时使用较低的学习率,防止破坏已经学习到的特征。
def freeze_model(model, freeze=True):
"""冻结或解冻模型的卷积层参数"""
# 冻结/解冻除fc层外的所有参数
for name, param in model.named_parameters():
if 'fc' not in name:
param.requires_grad = not freeze
# 打印冻结状态
frozen_params = sum(p.numel() for p in model.parameters() if not p.requires_grad)
total_params = sum(p.numel() for p in model.parameters())
if freeze:
print(f"已冻结模型卷积层参数 ({frozen_params}/{total_params} 参数)")
else:
print(f"已解冻模型所有参数 ({total_params}/{total_params} 参数可训练)")
return model4.训练函数定义
设置早停策略
# 6. 训练函数(支持阶段式训练和早停)
def train_with_freeze_schedule(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs, freeze_epochs=5, early_stop_patience=5):
"""
前freeze_epochs轮冻结卷积层,之后解冻所有层进行训练
当测试集准确率连续early_stop_patience轮未提升时触发早停
"""
train_loss_history = []
test_loss_history = []
train_acc_history = []
test_acc_history = []
all_iter_losses = []
iter_indices = []
# 早停相关变量
best_accuracy = 0.0
best_epoch = 0
early_stop_counter = 0
should_stop_early = False
# 初始冻结卷积层
if freeze_epochs > 0:
model = freeze_model(model, freeze=True)
for epoch in range(epochs):
# 早停检查
if should_stop_early:
print(f"触发早停: 在第 {best_epoch} 轮后测试准确率没有提升")
break
# 解冻控制:在指定轮次后解冻所有层
if epoch == freeze_epochs:
model = freeze_model(model, freeze=False)
# 解冻后调整优化器(可选)
optimizer.param_groups[0]['lr'] = 1e-4 # 降低学习率防止过拟合
model.train() # 设置为训练模式
running_loss = 0.0
correct_train = 0
total_train = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
# 记录Iteration损失
iter_loss = loss.item()
all_iter_losses.append(iter_loss)
iter_indices.append(epoch * len(train_loader) + batch_idx + 1)
# 统计训练指标
running_loss += iter_loss
_, predicted = output.max(1)
total_train += target.size(0)
correct_train += predicted.eq(target).sum().item()
# 每100批次打印进度
if (batch_idx + 1) % 100 == 0:
print(f"Epoch {epoch+1}/{epochs} | Batch {batch_idx+1}/{len(train_loader)} "
f"| 单Batch损失: {iter_loss:.4f}")
# 计算 epoch 级指标
epoch_train_loss = running_loss / len(train_loader)
epoch_train_acc = 100. * correct_train / total_train
# 测试阶段
model.eval()
correct_test = 0
total_test = 0
test_loss = 0.0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item()
_, predicted = output.max(1)
total_test += target.size(0)
correct_test += predicted.eq(target).sum().item()
epoch_test_loss = test_loss / len(test_loader)
epoch_test_acc = 100. * correct_test / total_test
# 记录历史数据
train_loss_history.append(epoch_train_loss)
test_loss_history.append(epoch_test_loss)
train_acc_history.append(epoch_train_acc)
test_acc_history.append(epoch_test_acc)
# 更新学习率调度器
if scheduler is not None:
scheduler.step(epoch_test_loss)
# 早停逻辑
if epoch_test_acc > best_accuracy:
best_accuracy = epoch_test_acc
best_epoch = epoch + 1
early_stop_counter = 0
print(f"保存最佳模型: 第 {best_epoch} 轮, 准确率 {best_accuracy:.2f}%")
else:
early_stop_counter += 1
print(f"早停计数器: {early_stop_counter}/{early_stop_patience}")
if early_stop_counter >= early_stop_patience:
should_stop_early = True
# 打印 epoch 结果
print(f"Epoch {epoch+1} 完成 | 训练损失: {epoch_train_loss:.4f} "
f"| 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%")
# 绘制损失和准确率曲线
plot_iter_losses(all_iter_losses, iter_indices)
plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)
return best_accuracy, best_epoch # 返回最佳测试准确率和对应的轮次5.绘图函数定义
# 7. 绘制Iteration损失曲线
def plot_iter_losses(losses, indices):
plt.figure(figsize=(10, 4))
plt.plot(indices, losses, 'b-', alpha=0.7)
plt.xlabel('Iteration(Batch序号)')
plt.ylabel('损失值')
plt.title('训练过程中的Iteration损失变化')
plt.grid(True)
plt.show()
# 8. 绘制Epoch级指标曲线
def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss):
epochs = range(1, len(train_acc) + 1)
plt.figure(figsize=(12, 5))
# 准确率曲线
plt.subplot(1, 2, 1)
plt.plot(epochs, train_acc, 'b-', label='训练准确率')
plt.plot(epochs, test_acc, 'r-', label='测试准确率')
plt.axvline(x=5, color='g', linestyle='--', label='解冻卷积层')
plt.xlabel('Epoch')
plt.ylabel('准确率 (%)')
plt.title('准确率随Epoch变化')
plt.legend()
plt.grid(True)
# 损失曲线
plt.subplot(1, 2, 2)
plt.plot(epochs, train_loss, 'b-', label='训练损失')
plt.plot(epochs, test_loss, 'r-', label='测试损失')
plt.axvline(x=5, color='g', linestyle='--', label='解冻卷积层')
plt.xlabel('Epoch')
plt.ylabel('损失值')
plt.title('损失值随Epoch变化')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()6.主函数
# 主函数:训练模型
def main():
# 参数设置
epochs = 40 # 总训练轮次
freeze_epochs = 5 # 冻结卷积层的轮次
learning_rate = 1e-3 # 初始学习率
weight_decay = 1e-4 # 权重衰减
early_stop_patience = 3 # 早停耐心值(测试准确率未改善的轮数)
# 创建ResNet50模型(加载预训练权重)
model = create_resnet50(pretrained=True, num_classes=10)
# 定义优化器和损失函数
optimizer = optim.Adam(model.parameters(), lr=learning_rate, weight_decay=weight_decay)
criterion = nn.CrossEntropyLoss()
# 定义学习率调度器
scheduler = optim.lr_scheduler.ReduceLROnPlateau(
optimizer, mode='min', factor=0.5, patience=2
)
# 开始训练(前5轮冻结卷积层,之后解冻)
final_accuracy, best_epoch = train_with_freeze_schedule(
model=model,
train_loader=train_loader,
test_loader=test_loader,
criterion=criterion,
optimizer=optimizer,
scheduler=scheduler,
device=device,
epochs=epochs,
freeze_epochs=freeze_epochs,
early_stop_patience=early_stop_patience
)
print(f"训练完成!最佳测试准确率: {final_accuracy:.2f}% (第 {best_epoch} 轮)")
# 保存最佳模型
torch.save(model.state_dict(), 'resnet50_cifar10_finetuned.pth')
print("模型已保存至: resnet50_cifar10_finetuned.pth")
if __name__ == "__main__":
main() 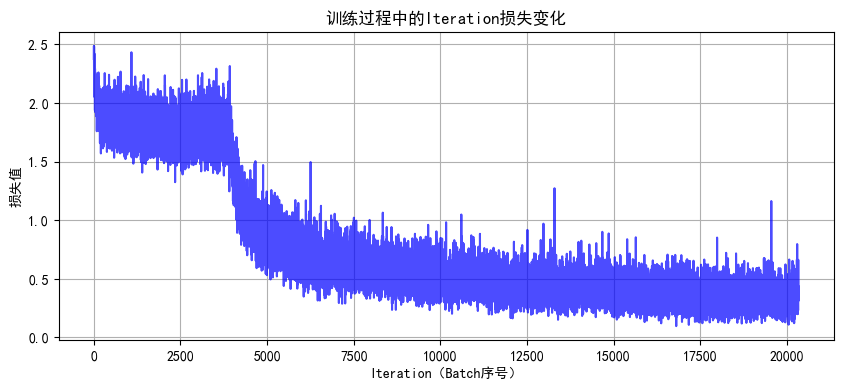
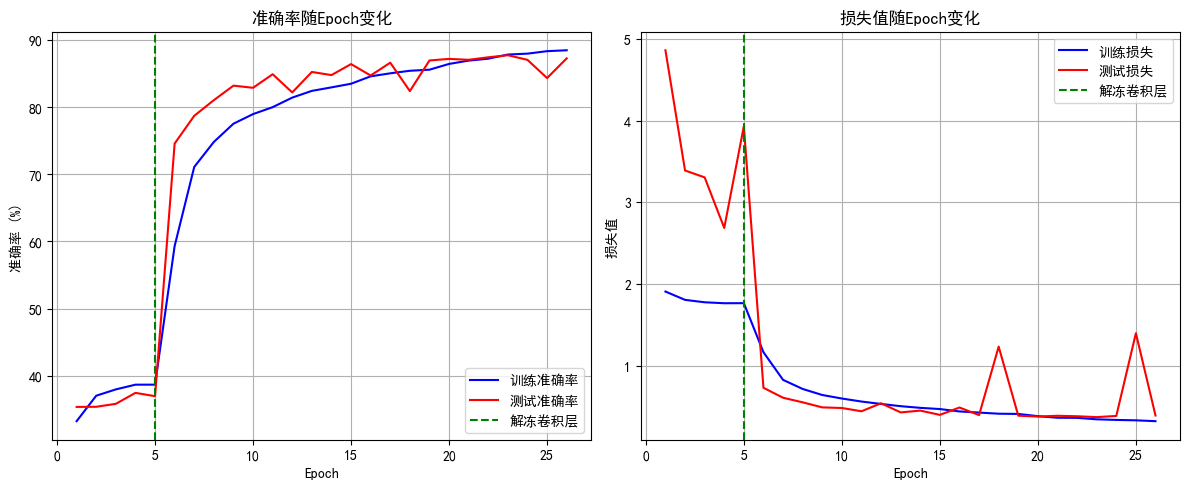
训练完成!最佳测试准确率: 87.71% (第 23 轮)
模型已保存至: resnet50_cifar10_finetuned.pth


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









