




import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score, confusion_matrix
import xgboost as xgb
import matplotlib.pyplot as plt
import seaborn as sns
# 设置图片清晰度
plt.rcParams['figure.dpi'] = 300
# 设置中文字体
# 修改此处,更换为 Windows 系统已有的中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 读取数据
train_data = pd.read_csv('train.csv')
test_data = pd.read_csv('test.csv')
# 从姓名中提取头衔的函数
def extract_title(data):
data['Title'] = data['Name'].str.extract(' ([A-Za-z]+)\.', expand=False)
data['Title'] = data['Title'].replace(['Lady', 'Countess', 'Capt', 'Col', 'Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')
data['Title'] = data['Title'].replace('Mlle', 'Miss')
data['Title'] = data['Title'].replace('Ms', 'Miss')
data['Title'] = data['Title'].replace('Mme', 'Mrs')
title_dummies = pd.get_dummies(data['Title'], prefix='Title')
data = pd.concat([data, title_dummies], axis=1)
return data
# 处理年龄缺失值的函数
def handle_age(data):
# 使用 transform 方法确保返回结果的索引与原始数据框一致
data['Age'] = data.groupby(['Pclass', 'Sex'])['Age'].transform(lambda x: x.fillna(x.median()))
return data
# 处理票价异常值的函数
def handle_fare(data):
fare_mean_by_class = data.groupby('Pclass')['Fare'].mean()
# 修改此处,使用 map 方法避免索引不匹配
data['Fare'] = data.apply(lambda row: fare_mean_by_class[row['Pclass']] if row['Fare'] == 0 else row['Fare'], axis=1)
data['Fare'] = np.log1p(data['Fare'])
return data
# 处理船舱号的函数
def handle_cabin(data):
data['Cabin'] = data['Cabin'].str[0]
data['Cabin'] = data['Cabin'].fillna('U')
cabin_dummies = pd.get_dummies(data['Cabin'], prefix='Cabin')
data = pd.concat([data, cabin_dummies], axis=1)
return data
# 处理登船港口缺失值的函数
def handle_embarked(data):
most_frequent_embarked = data['Embarked'].mode()[0]
# 修改此处,避免 inplace 警告
data['Embarked'] = data['Embarked'].fillna(most_frequent_embarked)
embarked_dummies = pd.get_dummies(data['Embarked'], prefix='Embarked')
data = pd.concat([data, embarked_dummies], axis=1)
return data
# 对训练集进行处理
train_data = extract_title(train_data)
train_data = handle_age(train_data)
train_data = handle_fare(train_data)
train_data = handle_cabin(train_data)
train_data = handle_embarked(train_data)
train_data['Sex'] = train_data['Sex'].map({'female': 0, 'male': 1})
train_data['family_size'] = train_data['SibSp'] + train_data['Parch'] + 1
train_data['is_alone'] = train_data['family_size'].apply(lambda x: 1 if x == 1 else 0)
train_data['Sex_Pclass'] = train_data['Sex'] * train_data['Pclass']
# 对测试集进行处理
test_data = extract_title(test_data)
test_data = handle_age(test_data)
test_data = handle_fare(test_data)
test_data = handle_cabin(test_data)
test_data = handle_embarked(test_data)
test_data['Sex'] = test_data['Sex'].map({'female': 0, 'male': 1})
test_data['family_size'] = test_data['SibSp'] + test_data['Parch'] + 1
test_data['is_alone'] = test_data['family_size'].apply(lambda x: 1 if x == 1 else 0)
test_data['Sex_Pclass'] = test_data['Sex'] * test_data['Pclass']
# 选择特征和目标变量
features = ['Pclass', 'Age', 'Fare', 'Sex', 'Title_Mr', 'Title_Mrs', 'Title_Miss', 'Title_Rare',
'Cabin_A', 'Cabin_B', 'Cabin_C', 'Cabin_D', 'Cabin_E', 'Cabin_F', 'Cabin_G', 'Cabin_T', 'Cabin_U',
'Embarked_C', 'Embarked_Q', 'Embarked_S', 'family_size', 'is_alone', 'Sex_Pclass']
# 动态处理测试数据中的特征
available_features = [col for col in features if col in test_data.columns]
X = train_data[available_features]
y = train_data['Survived']
# 划分训练集和验证集
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
# 数据标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_val_scaled = scaler.transform(X_val)
# 定义 XGBoost 模型并进行超参数调优
param_grid = {
'n_estimators': [50, 100, 150],
'max_depth': [3, 5, 7],
'learning_rate': [0.1, 0.01, 0.001]
}
xgb_model = xgb.XGBClassifier()
grid_search = GridSearchCV(xgb_model, param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train_scaled, y_train)
best_model = grid_search.best_estimator_
# 模型评估
y_pred = best_model.predict(X_val_scaled)
accuracy = accuracy_score(y_val, y_pred)
print(f"模型在验证集上的准确率: {accuracy}")
# 对测试集进行预测
X_test = test_data[available_features]
X_test_scaled = scaler.transform(X_test)
# 确保预测结果的索引和 test_data 的索引一致
test_predictions = pd.Series(best_model.predict(X_test_scaled), index=test_data.index)
test_data['Survived'] = test_predictions
# 输出预测结果到文件
test_data[['PassengerId', 'Survived']].to_csv('submission_optimized.csv', index=False)
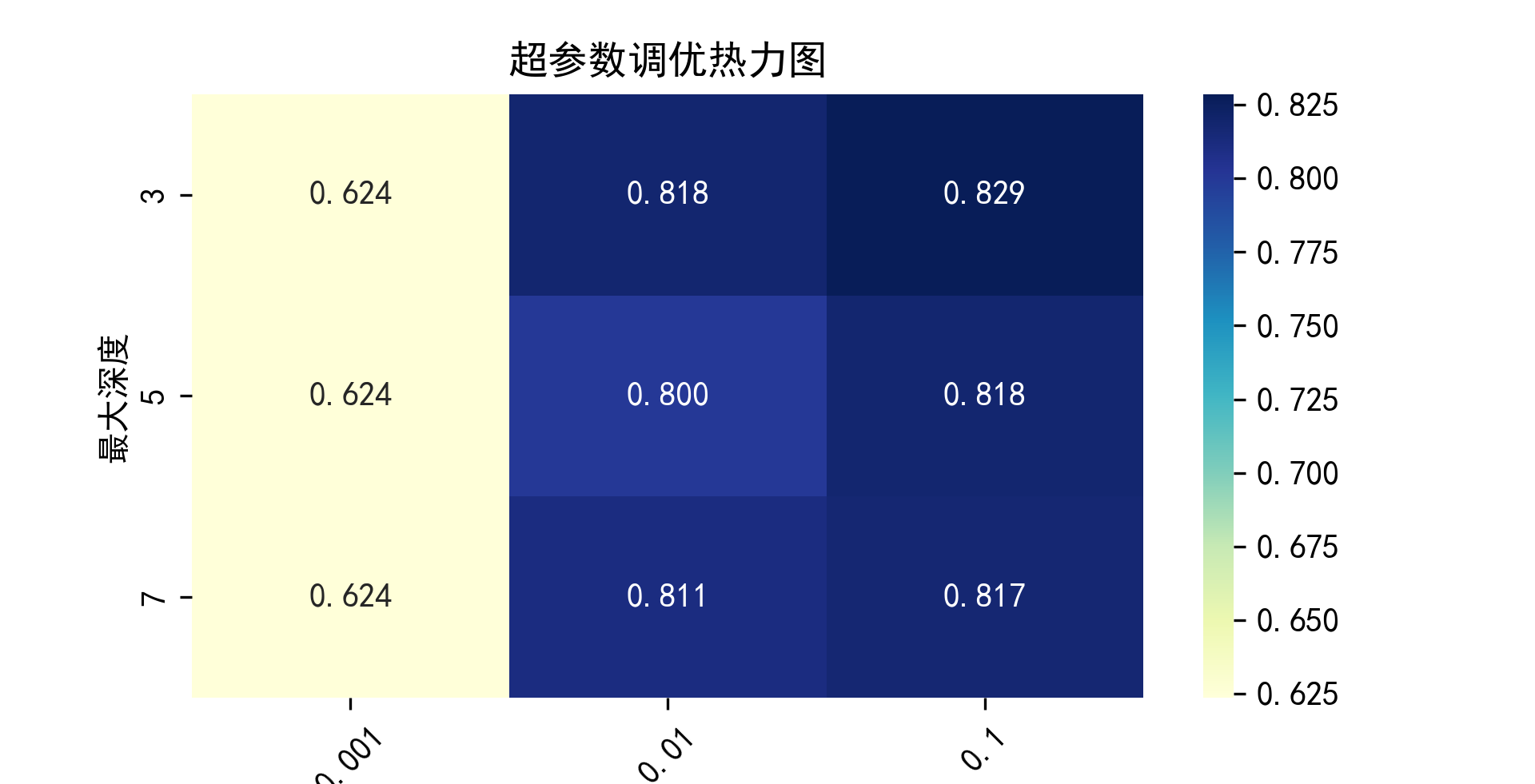
# 绘制超参数调优热力图
results = pd.DataFrame(grid_search.cv_results_)
pivot_table = results.pivot_table(index='param_max_depth', columns='param_learning_rate', values='mean_test_score')
plt.figure(figsize=(10, 6))
sns.heatmap(pivot_table, annot=True, fmt=".3f", cmap="YlGnBu")
plt.title('超参数调优热力图')
plt.xlabel('学习率')
plt.xticks(rotation=45)
plt.ylabel('最大深度')
plt.show()
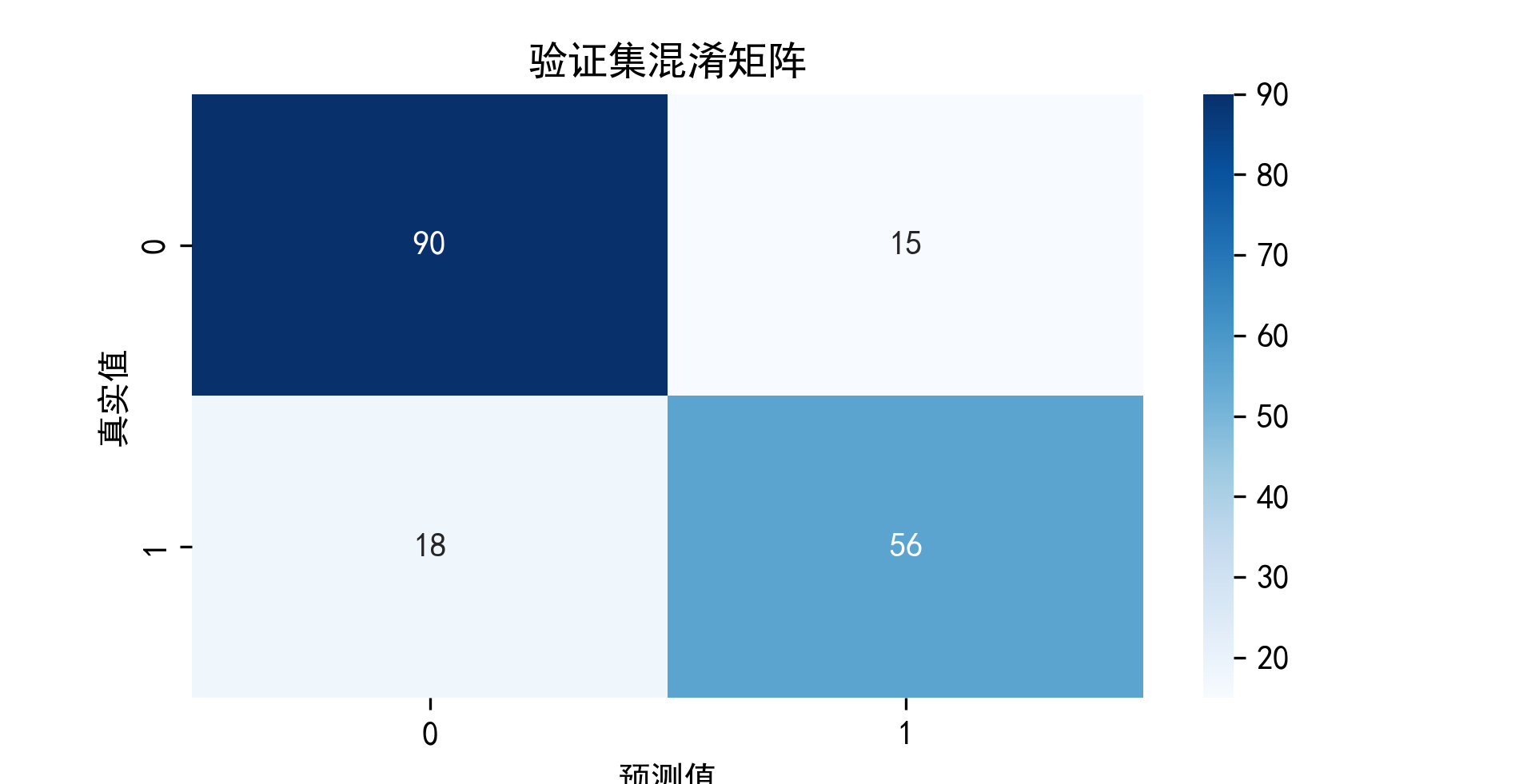
# 绘制混淆矩阵
cm = confusion_matrix(y_val, y_pred)
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.title('验证集混淆矩阵')
plt.xlabel('预测值')
plt.ylabel('真实值')
plt.show()
# 计算测试集准确率
import pandas as pd
from sklearn.metrics import accuracy_score
# 读取预测结果文件
predicted_data = pd.read_csv('submission_optimized.csv')
# 读取正确答案文件
true_data = pd.read_csv('gender_submission.csv')
# 确保两个数据集中乘客ID顺序一致
predicted_data = predicted_data.sort_values(by='PassengerId')
true_data = true_data.sort_values(by='PassengerId')
# 计算准确率
accuracy = accuracy_score(true_data['Survived'], predicted_data['Survived'])
print(f"模型在测试集上的准确率为: {accuracy * 100:.2f}%")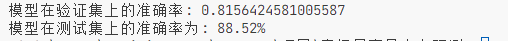

















 1479
1479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









