



来源:基于深度学习的跨摄像机目标车辆跟踪方法研究 - 中国知网
一.研究问题
单摄像机的目标跟踪虽已经取得了较为丰富的研究成果,单存在视域范围较窄、无法对目标开展连续跟踪的局限性。相比之下,跨摄像机的目标跟踪在车辆跟踪等持续运动跟踪场景有着重要的学术意义,但跨摄像机目标跟踪面临着如:背景遮挡、光照变化、摄像机视角差异、时间跨度长等干扰因素,带来了巨大挑战。
二.研究现状
2.1 车辆检测
-
传统的目标检测方法:选择候选区域通过训练好的分类器判别背景或目标;
-
基于深度学习的目标检测方法
1.两阶段目标检测算法:R-CNN、Fast-RCNN、Faster-RCNN、Mask-RCNN等。——精度较高,但推理速度较慢;
2.基于回归思想的一阶段目标检测算法:SSD、Yolo等。——精度较低,但推理速度快;
2.2 车辆重识别
-
基于传感器的方法 ——简单,但易受到信号强弱、天气变化、交通状况等因素影响,复现难度高,识别率低;
-
基于手工特征提取的重识别方法 ——易受到视角、分辨率、光照变化等因素影响;
-
基于深度学习的重识别方法;
2.3搜索路径规划
跨摄像机车辆跟踪问题可以转化为多摄像机下的目标检索问题,需要构建摄像机间的拓扑关系并选取合适的预测方法。拓扑关系常用时空关系来描述:
-
空间关系:描述摄像机的位置信息集摄像机之间的转移路径;
-
时间关系:描述摄像机之间的转移时间;
三.相关理论知识
3.1 特征提取方法
3.1.1 基于手工特征提取的方法
-
颜色直方图:反映图像像素颜色分布情况,但不能提供像素空间位置信息
-
一般颜色直方图:各颜色占比
-
全局累加直方图:对颜色小于或等于某个值的颜色占比进行累加,把一般颜色直方图类比概率密度,则全局累加直方图为概率分布;
-
主色调直方图:计算颜色频率,获取频率最高的几种作为主色调;
-
-
尺度不变特征变换
-
3.1.2 尺度不变特征变换(SIFT)
-
尺度空间极值检测:高斯差分金字塔检测图像中的极值点;
-
关键点定位:使用DoG算子寻找极值点,使用二阶泰勒展开式进行精确定位;
-
方向确定:计算关键点周围像素点的梯度幅值和方向确定关键点主方向;
-
局部特征描述:使用128维向量来描述关键点的局部特征;
3.1.3 方向梯度直方图
计算和串联图像各个区域的梯度直方图来表征图像结构和形状,局域平移和选择很好的不变性;
3.2 基于卷积神经网络的方法
-
AlexNet:引入ReLU、Dropout、有重叠的最大池化、局部响应归一化层(LRN);
-
VGGNet:堆叠XCNN;
-
GooLeNet:以组合的方式将不同尺度的卷积核按照序列的形式堆叠起来;
-
ResNet:残差网络,防止网络层数加深导致的网络退化现象;
3.3 注意力机制
-
SENet(Squeeze and Excitation Networks):计算通道维的注意力权重;
-
CBAM(Convolution Block Attention Module):计算通道注意力和空间注意力,并对两个维度分别赋予权值加权计算;
-
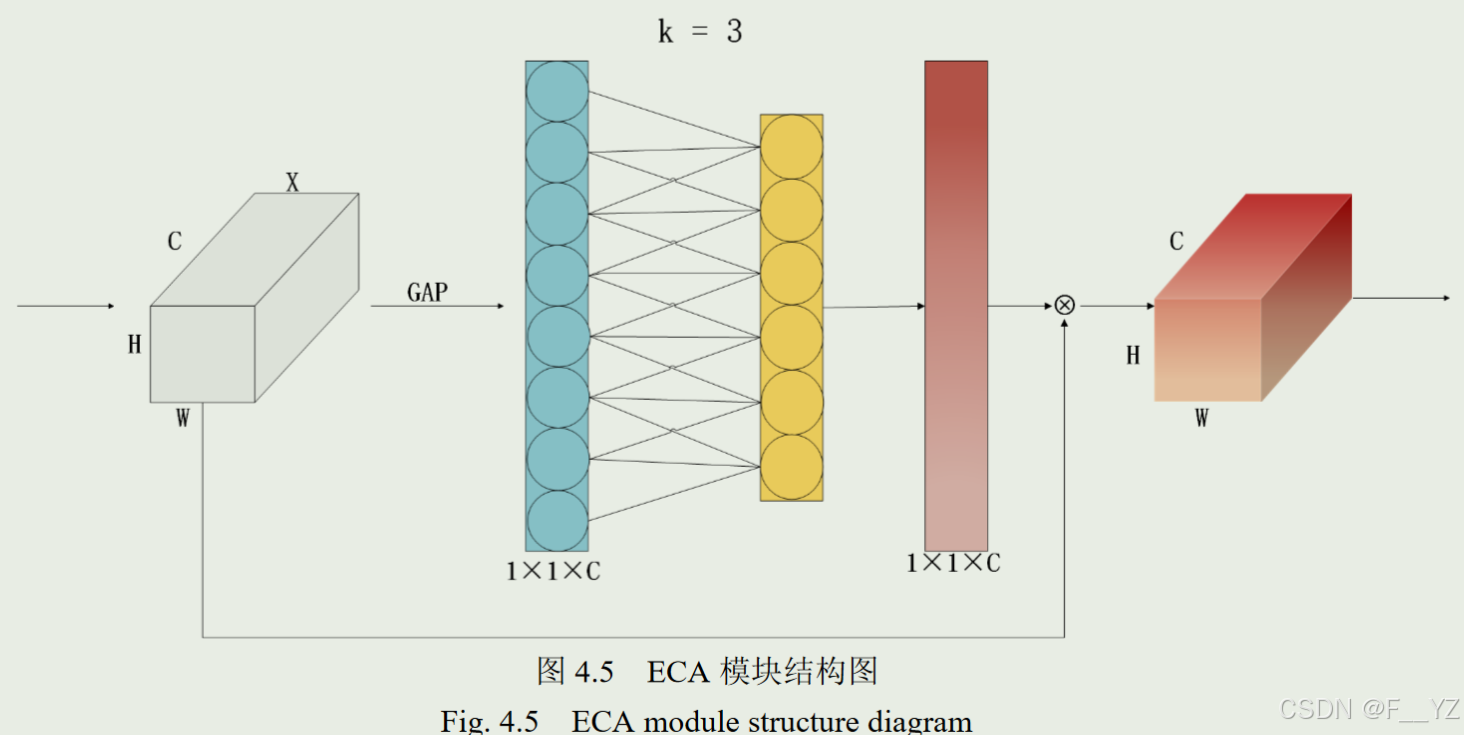
ECA(Efficient Channel Attention):提出一种自适应卷积核的一维卷积,来计算通道维的注意力权重;
3.4 图搜索算法
-
深度优先遍历算法(DFS):易实现,节省空间,但容易无限制沿着某方向搜索;
-
广度优先遍历算法(BFS):能够找到最短路径,但需要大量的状态信息;
四.基于改进Yolov5s的车辆检测算法
4.1 Yolov5s模型改进
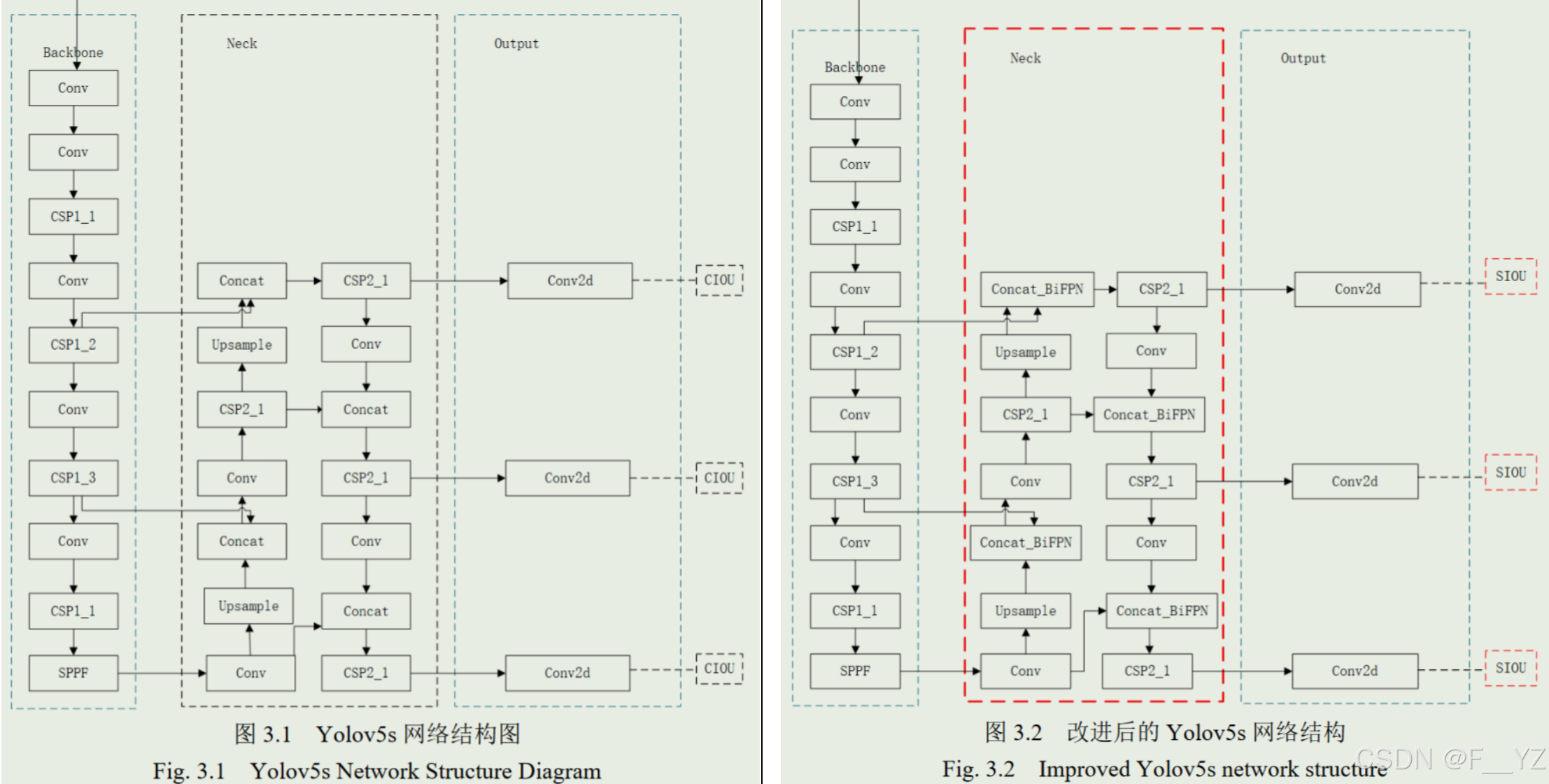
4.1.1. 特征融合网络改进
卷积神经网络中,浅层特征图分辨率较高,目标位置信息丰富,适合区分简单的目标;深层特征图分辨率低,特征图语义信息丰富,适合区分复杂目标。二者的特征图进行融合则适合区分多类目标。
-
特征金字塔(FPN):通过在底层特征图进行上采样操作,将其与高层特征图进行融合。
-
PAN:在FPN基础上,在FPN的自顶向下的路径之后又添加了一个自底向上的路径,更进一步提取特征进行融合。
-
-
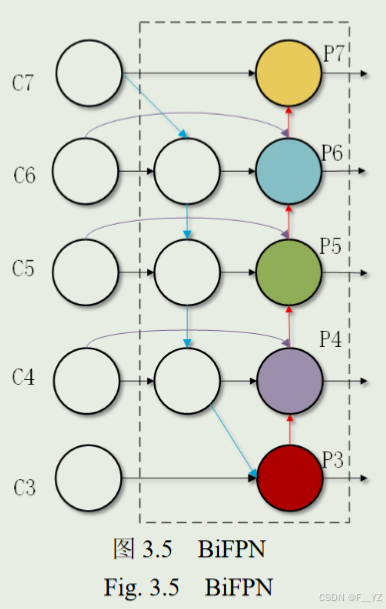
BiFPN:作者将YOLOv5s的Concat模块替换成Concat_BiFPN模块。PANet的特征融合策略是平等的对待不同尺度的特征,而BiFPN引入了一个权重因子,能够更好地平衡不同尺度的特征信息。权重分配方式如下:
4.1.2. 损失函数优化
-
YOLOv5s损失函数:
- 分类损失:分类损失采用交叉熵损失函数,计算锚框与对应的标定分类是否正确。tij和oij分别表示预测框i中是否存在对应的j类目标(bool)以及对应的概率。
2. 置信度损失:根据特征点和正负样本是否包含目标来评估预测结果是否正确。fi和ki分别表示 预测框i中是否存在目标(bool)以及对应的概率。
3. 边框损失(CIOU):针对每个anchor框,计算其预测框与真实框之间的误差,采用 CIOU_Loss计算。
其中,IOU指的是真实框与预测框的交并比,ρ为两框中心点的欧氏距离,c为包含两框的最小外接矩形的对角线长度,α为权重稀系数,v是衡量两框的长宽比是否一致;
-
改进损失函数:SIOU:
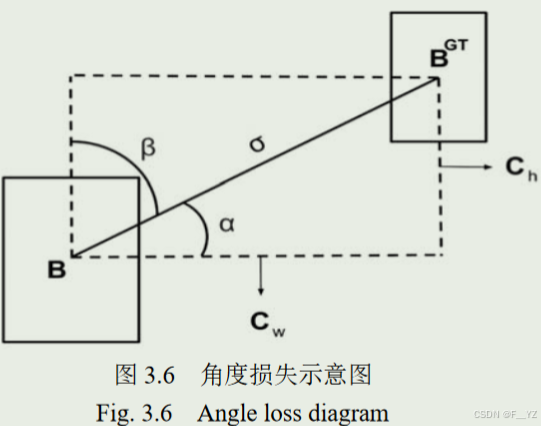
CIOU损失函数没有考虑到真实框与预测框之间可能存在的角度不匹配问题。
-
角度损失(Λ)
-
距离损失(∆)
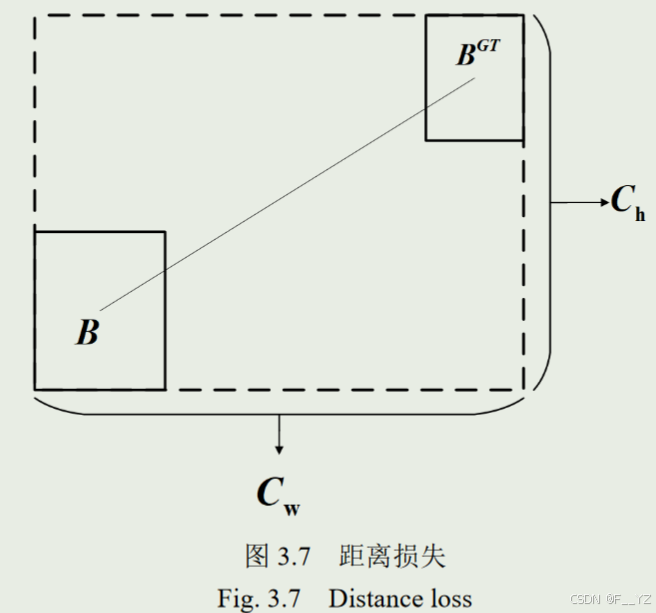
-
形状损失:
-
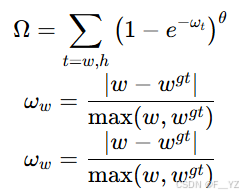
4. SIOU_Loss回归损失函数:
-
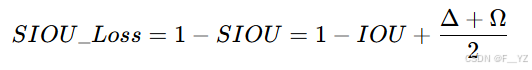
4.2 基于改进Reid的目标车辆重识别算法
4.2.1 ReID基本原理
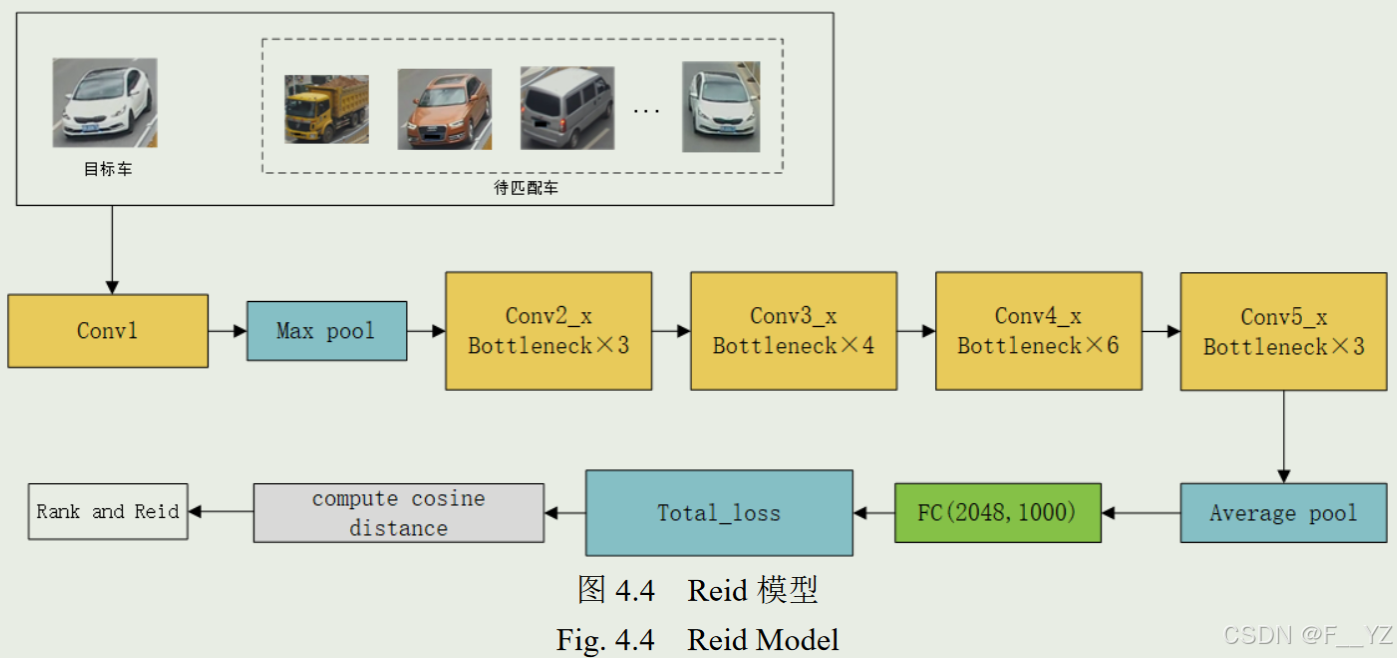
ReID模型一般使用卷积神经网络作为特征提取器,将输入图像映射为高位特征向量,通过比较不同图像的特征向量,计算其相似度实现目标重识别。作者引入车辆颜色特征、车型特征以及在特征提取网络中加入ECA注意力机制(深层特征),对Reid模型进行改进。
ReID模型的损失函数由交叉熵损失与三元组损失组合而成。
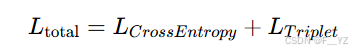
三元组损失函数:缩短正样本在特征空间里的距离,并且增加负样本在特征空间里的距离。
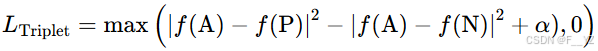
A代表Anchor,为目标车辆图片,P代表与目标车辆图片是同一辆车,N代表与目标车辆图片不是同一辆车。
4.2.2 网络结构设计
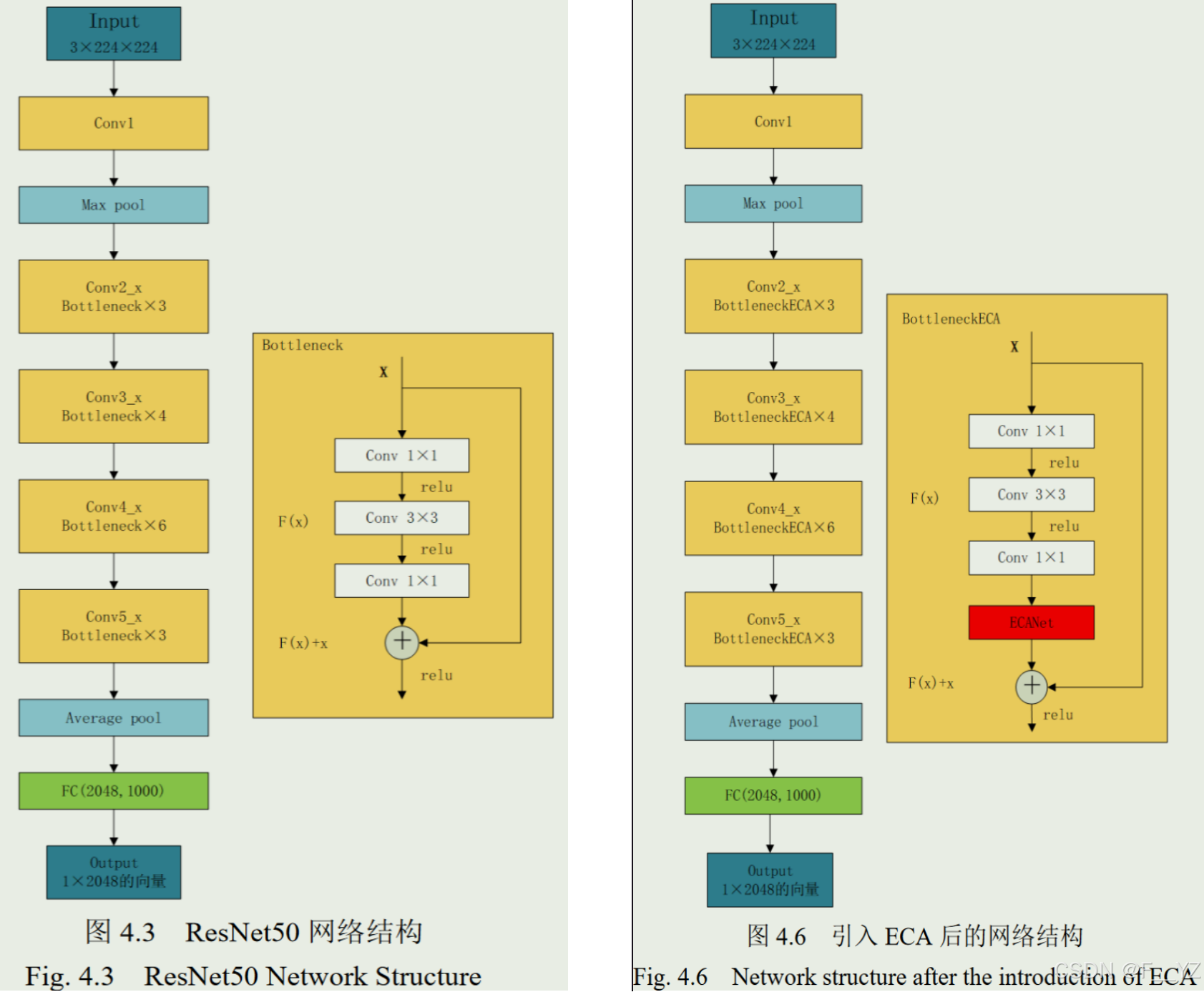
作者在ResNet50基础上进行改良,在每一个残差块上都加入了ECA注意力机制,以提高深度特征提取的效果。
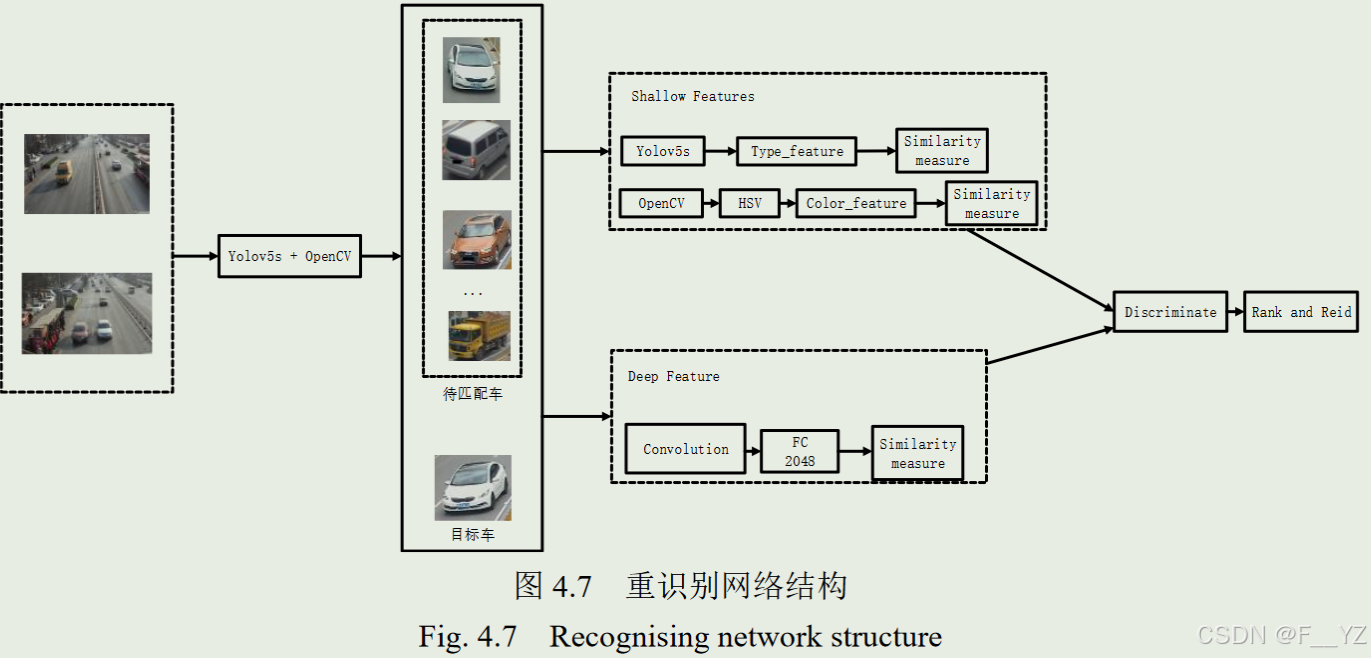
4.2.3 相似度度量方法
-
颜色特征相似度度量:巴氏距离公式
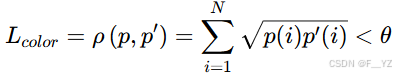
-
p为目标图像直方图数据,p’为候选图像的直方图数据,θ为颜色直方图距离的阈值。
-
车型相似度度量:
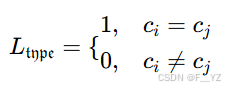
-
深度特征相似度度量:余弦距离公式
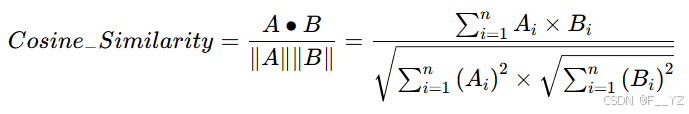
4.3 实验分析
-
数据集选择:VeRi-776数据集——用于重识别任务的公共数据集;
-
评价指标选取:
-
Rank:Rank-n的值表示在前n个搜索结果中,正确结果出现的概率;若查询多个目标,则Rank-n为多个目标查询结构均值;
-
ROC:ROC曲线各点代表了对同一信息或刺激的感受性值。每一个点都代表的是不同阈值下对应的FP(错误率)和TP(正确率)之间的关联。ROC曲线下方的面积被称为AUC,AUC值越高,分类器性能越好。
-
五.基于时空约束的跨摄像机目标车辆搜索算法
5.1. 构建时空关系模型
作者提出一种基于摄像机的时空约束网络。该时空约束网络为采用数据字典表示的时空关系图模型。
-
在空间关系上,假设模型为加权无向图,以路段分叉口作为图的节点,路段作为图的边。
-
在时间关系上,以通过路段的经验时间表示边的权重,使用百度地图中的路径规划接口(API)来获取各路段通行时间。
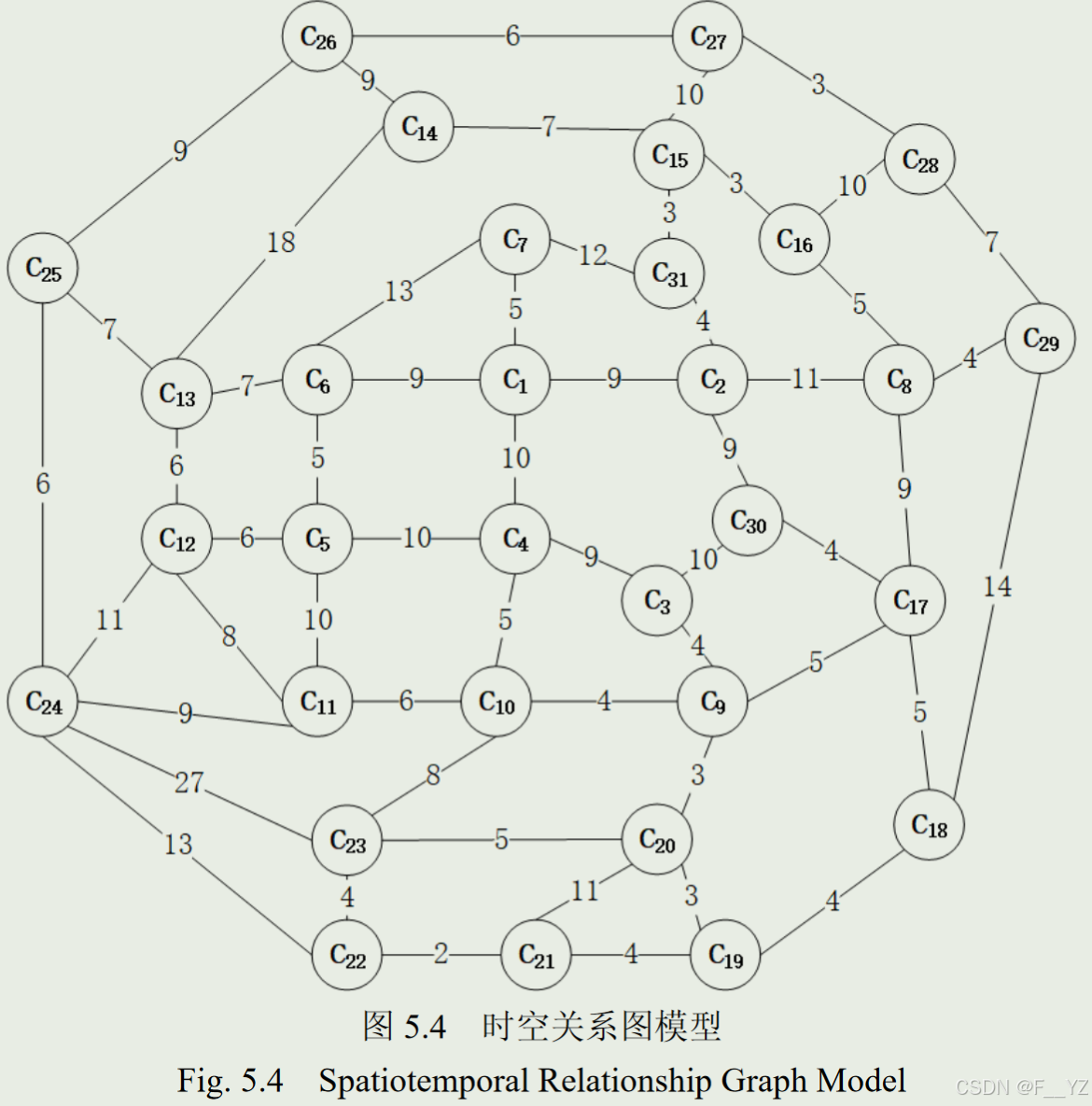
5.2. 跨摄像机目标搜索算法
作者采用广度优先遍历算法进行搜索。
“如果当前节点已经被访问过,则跳过该节点,否则检查路径长度是否超过阈值,如果超过阈值则跳过该节点,否则查询该节 点所对应的重识别结果,查看是否有目标车辆,如果有,则将该节点加入到路径中和 Visited 表中,并更新路径长度。重复上述过程直到达到时间阈值或 Unvisited 表为空; 最后,输出目标车辆的行驶路径和路径中每个节点的搜索时长” (吴继萌, 2023, p. 57)
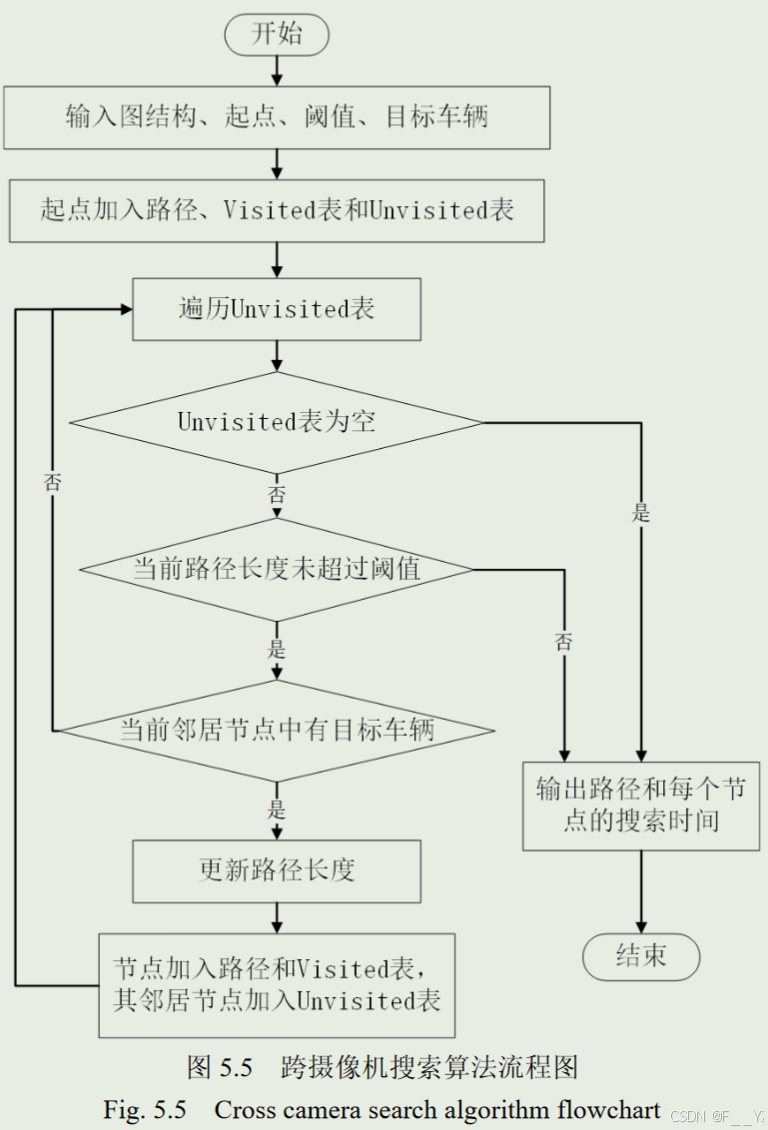
实验结果表明采用本文的搜索算法在车辆路径搜索上检索的摄像机个数更少。可以有效过滤不和条件的摄像机,缩小检索范围,大幅提升跟踪效率。



















 541
541

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









