




论文链接: 2308.09905
一. 简介
DBT 和 JDT 多目标跟踪面临问题:1)全局与局部不一致;2)鲁棒性和模型复杂性之间的权衡不佳;3)同一视频不同场景缺乏灵活性;
方法:本文提出一个简单的模型 DiffusionTrack,采用扩散模型对目标检测和关联共同构建为从成对噪声框到成对真值框的一致去噪扩散过程;
![]()
三. 方法
3.1. 回顾
扩散模型 扩散模型通常使用两条马尔可夫链:一条正向链,用于扰动图像到噪声,另一条反向链用于将噪声优化回图像。给定数据分布 ,时间 t 的前向噪声扰动过程定义为
。它逐渐向数据中添加高斯噪声
:
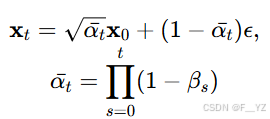
给定 ,可以通过对高斯向量
进行采样并应用变换 -来轻松获得
的样本:
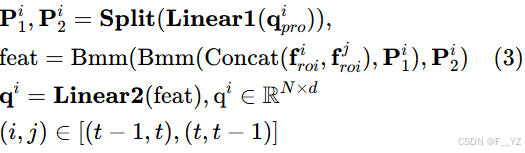
在训练过程中,神经网络会根据 预测不同
的
。在推理中,我们从随机噪声
开始,迭代应用反向链以获得
。
3.2. DiffusionTrack
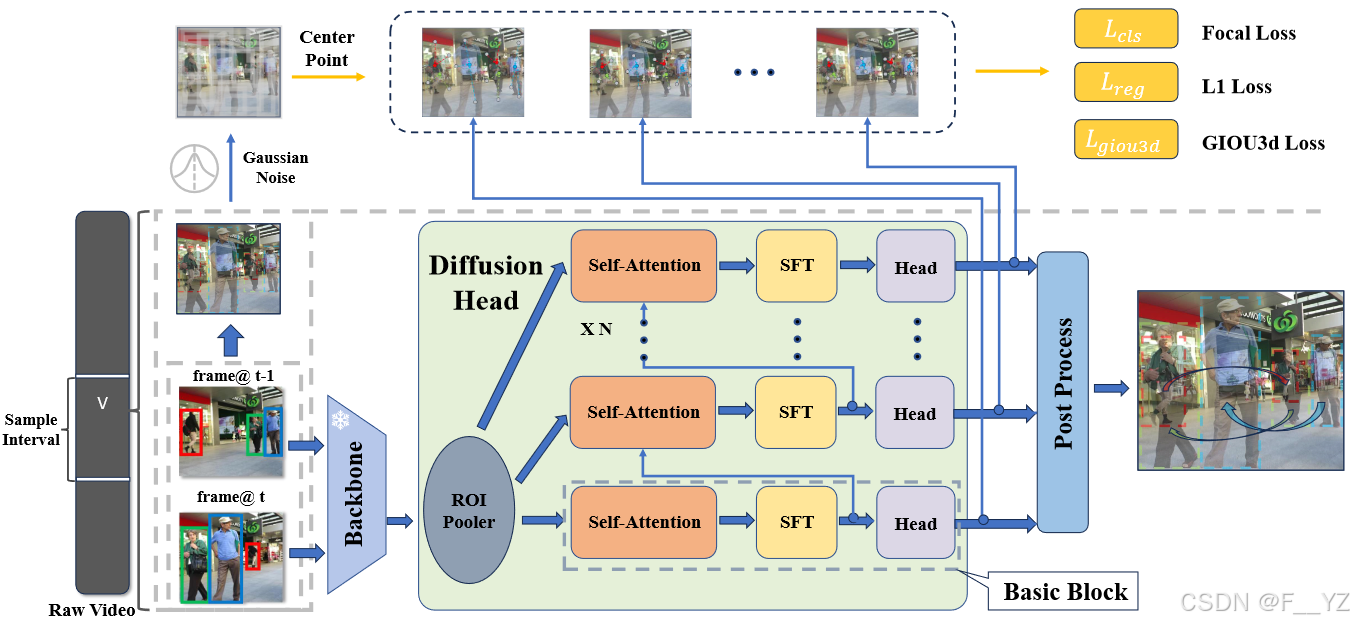
DiffusionTrack 由两个主要部分组成:特征提取主干和数据关联降噪头(扩散头),其中前者只运行一次,从两个相邻的输入图像 中提取深度特征表示,后者将此深度特征作为条件,以逐步从成对噪声框中优化配对关联框预测。在我们的设置中,数据样本是一组成对的边界框
,其中
。神经网络
经过训练,以相应的两个相邻图像
为条件,从成对的噪声框
中预测
。相应地生成相应的类别标签
和关联置信度分数
。如果
,则多目标跟踪任务退化为目标检测问题。一致的设计使 DiffusionTrack 能够同时解决这两项任务。
-
Backbone:YOLOX;backbone 使用 FPN 提取两个相邻帧的高级特征,然后将其馈送至下一个扩散头进行条件数据关联去噪;
-
Diffusion head:diffusion head 以一组提议框作为输入,从 backbone 生成的特征图中裁剪 RoI 特征,并将这些 RoI 特征发送到不同的块,分别获得框回归、分类结果和关联置信度分数。为了解决对象跟踪问题,作者为扩散头的每个块添加了一个时空融合模块 (STF) 和一个关联评分头。
-
Spatial-temporal fusion module(STF):时空融合模块使同一个配对的 bbox 可以相互交换时间信息,以确保能够完成两个连续帧的数据关联。给定 ROI 特征
,以及当前块的自注意力输出查询
,我们进行线性处理和批量矩阵乘法,得到目标查询
为:
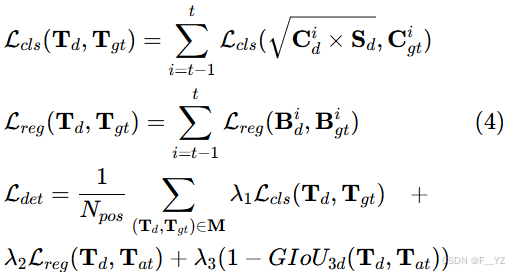
-
Association score head:除了 box head 和 class head 之外,作者还添加了一个额外的关联分数 head,通过将两个配对框的融合特征馈送到线性层中来获得数据关联的置信度分数。该头用于确定成对的框输出是否属于后续非最大抑制 (NMS) 后处理过程中的同一目标。
3.3. 模型训练和推理
在训练阶段,作者的方法采用从训练集中的序列中随机采样的一对帧作为输入,间隔为 5。首先将一些额外的框填充到出现在两个帧中,以便所有框都求和为一个固定数字 。然后,将高斯噪声添加到填充的真实框中,其中
在时间步 t 中呈单调递减的余弦时间序列。最后,作者进行一个去噪过程,从这些构建的噪声框中获得关联结果。作者还设计了一个基线,该基线仅破坏帧 t 中的真实框,并根据帧 t − 1 中的先前框有条件地对损坏的框进行降噪,以验证 DiffusionTrack 中两个帧的损坏设计的必要性。
-
损失函数:对于匈牙利算法获得的匹配集 M 中的每对
,我们将其类分数、预测框结果和关联分数表示为
和
。损失函数如下(其中:
为 focal 损失,
为 L1 损失,
为正例数):
-
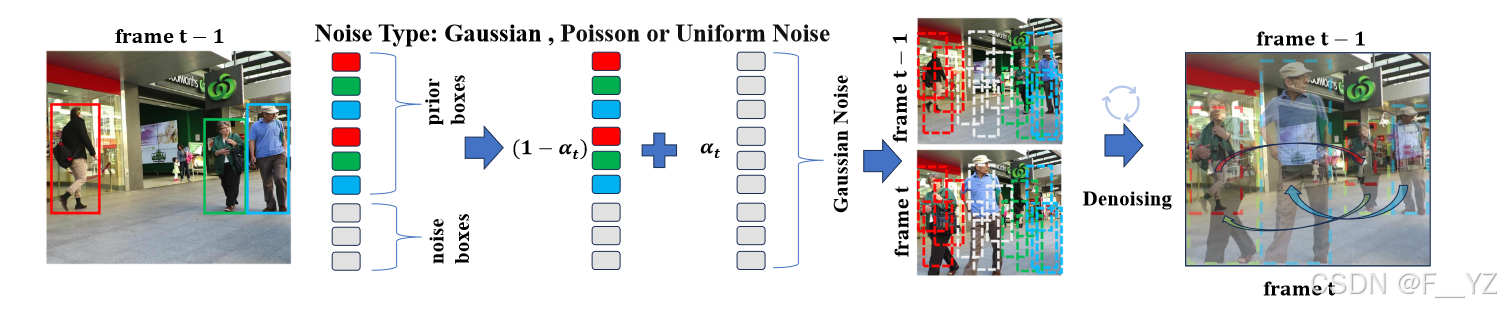
推理:如图所示,DiffusionTrack 的推理管道是一个从成对噪声框到关联结果的去噪采样过程。与从高斯分布中选择随机框的检测任务不同,跟踪任务具有帧 t − 1 中目标的先验信息,因此我们可以像在训练阶段一样,使用先验框生成具有固定数量 Ntest 的初始化噪声框,以利于数据关联。与 DiffusionTrack 相比,只需重复先验框而不填充额外的随机框,并且仅在基线模型中的 t 处向先验框添加高斯噪声。派生关联结果后,IoU 将用作相似性量度来连接对象 tracklet。为了解决潜在的遮挡问题,我们实现了一个简单的卡尔曼滤波器来重新关联丢失的对象,附录中有更多细节。
(在训练期间,噪声框是通过将高斯噪声添加到同一对象的成对真值框来构建的。在推理中,噪声框是通过将高斯噪声添加到前一帧中填充的先验对象框来构建的。)
四. 实验
4.1. 设置
4.2. 有趣的特性
-
动态框和渐进式细化
-
对检测扰动的鲁棒性
4.3. 消融实验
-
先验信息的比例
-
边界框填充策略
-
扰动调度
-
效率比较
4.4. 与SOTA比较
五. 附录
A. 局限性与更广泛的影响
-
局限性:1)在 MOT20 上对于小目标跟踪效果不佳;2)去噪步骤太多,训练时间较长;
-
更广泛的影响: 从 DiffusionTrack 呈现的结果来看,我们认为扩散模型由于其简单的训练和推理管道以及一致的模型设计,是一种新的解决多目标追踪问题的可能方案,显示出对物体进行高层语义关联的巨大潜力。
B. 3D GIoU计算
C. 可视化
D. 推理细节



















 7669
7669



 到【灌水乐园】发言
到【灌水乐园】发言








