




 本文详细介绍Python爬虫技术,涵盖urllib.request模块的使用,包括下载文件、发送请求及异常处理。通过实战示例,展示如何抓取网页源代码并解析天气信息。
本文详细介绍Python爬虫技术,涵盖urllib.request模块的使用,包括下载文件、发送请求及异常处理。通过实战示例,展示如何抓取网页源代码并解析天气信息。
前言
关于python爬虫目前有两个主流的库一个是urllib和requests 在python3中urllib2已经没有了,取而代之的是urllib.request。这里的话我将首先介绍urllib.request的使用。之后我再介绍request,我本人是打算做一个系列的爬虫教程不仅仅包括入门还有实战进阶所以我希望浏览我写的博客时可以按顺序浏览学习。那么废话不多说奉上名言成功没有偶然。 即便有些胜利者谦虚地说,自己的成功是偶然的缘故。—— 尼采开始正片!!!
urllib 下载
打开cmd命令输入pip install urllib3点击回车

当然有时候由于pip版本问题可能无法下载不过没关系你只需要输入python -m pip install --upgrade pip更新版本之后打开python输入:
import urllib.request
如果没有报错那么恭喜你成功了!
urllib的模块
request:基本的HTTP请求模块用于模拟发送请求
error:异常处理模块
parse:用于处理URL比如拆分,解析,合并,data参数等
robotparser:用于识别网站的robot.txt文件,判断网站是否可以爬取
urllib.request
urllib.request的方法有:
urlretrieve() 下载文件
urlcleanup() 释放缓存
urlopen() 发送请求get
这里我们实战一下
import urllib.request as u
r=u.urlopen('https://123.sogou.com/')
u.urlcleanup()
print(r.read().decode('utf-8'))
urlopen()返回了一个可读的对象之后我们将其解码为‘utf-8’
之后我们可以读取出网站的源代码。之后对其进行分析以后
我们在对其html进行详细解释
常见报错
前面我们已经说了print(r.read().decode('utf-8'))可得到网站源码
然如果没猜错的话当你运行上述代码时可能会遇到如下报错

当然如果你没有遇到那么,,看看也无妨。 具体是怎么回事呢其实很简单,出现异常报错是由于设置了decode()方法的第二个参数errors为严格(strict)形式造成的,而这个是它默认的模式所以改个模式就好啦如下:
print(r.read().decode('utf-8','ignore'))
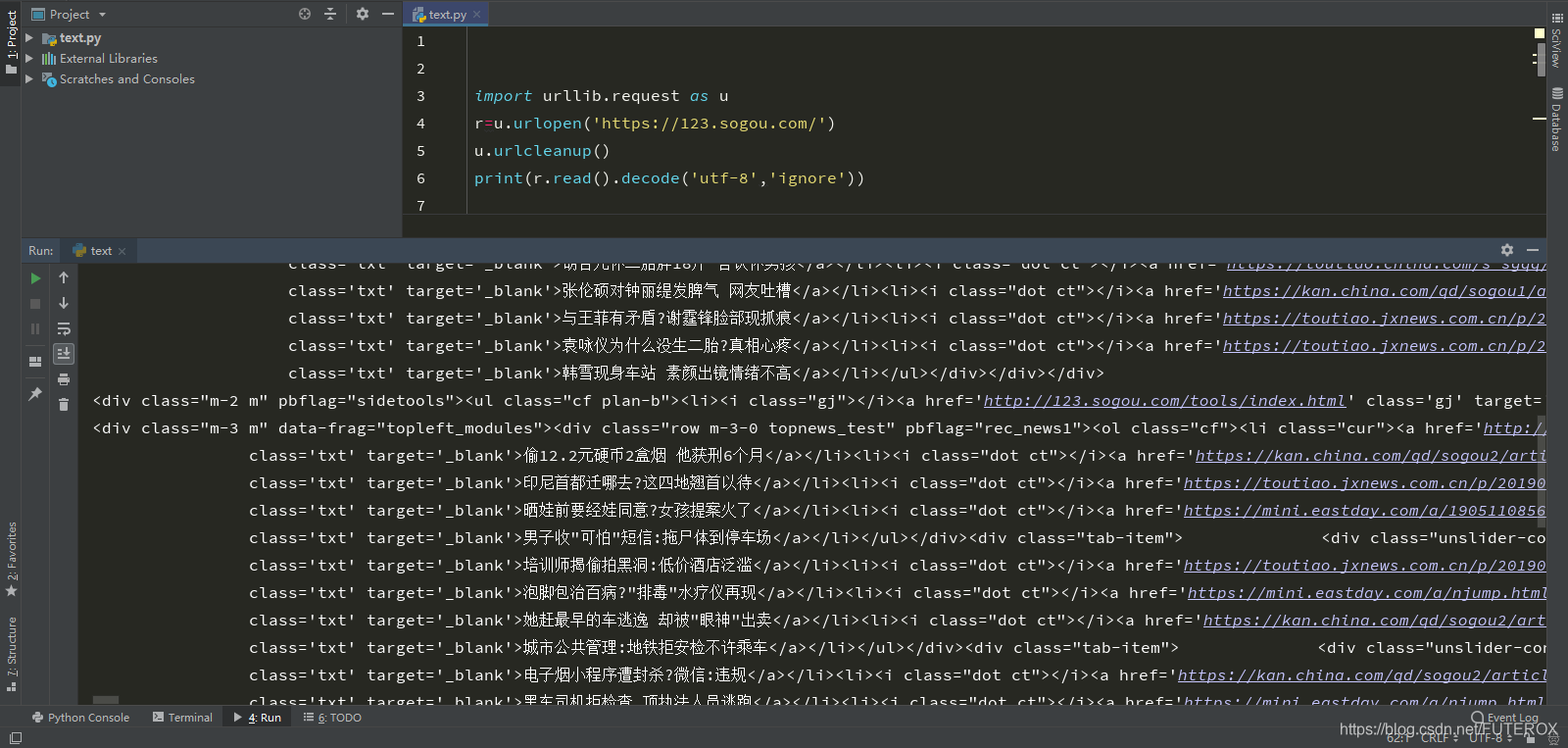
ok! 当你也这样之后恭喜你成功了!不过还没完!!!
urlopen 方法
info 获取当前内容状态
getcode 输出状态码
geturl 获取当前网址
print(r.info())
print(r.getcode())
print((r.geturl()))
效果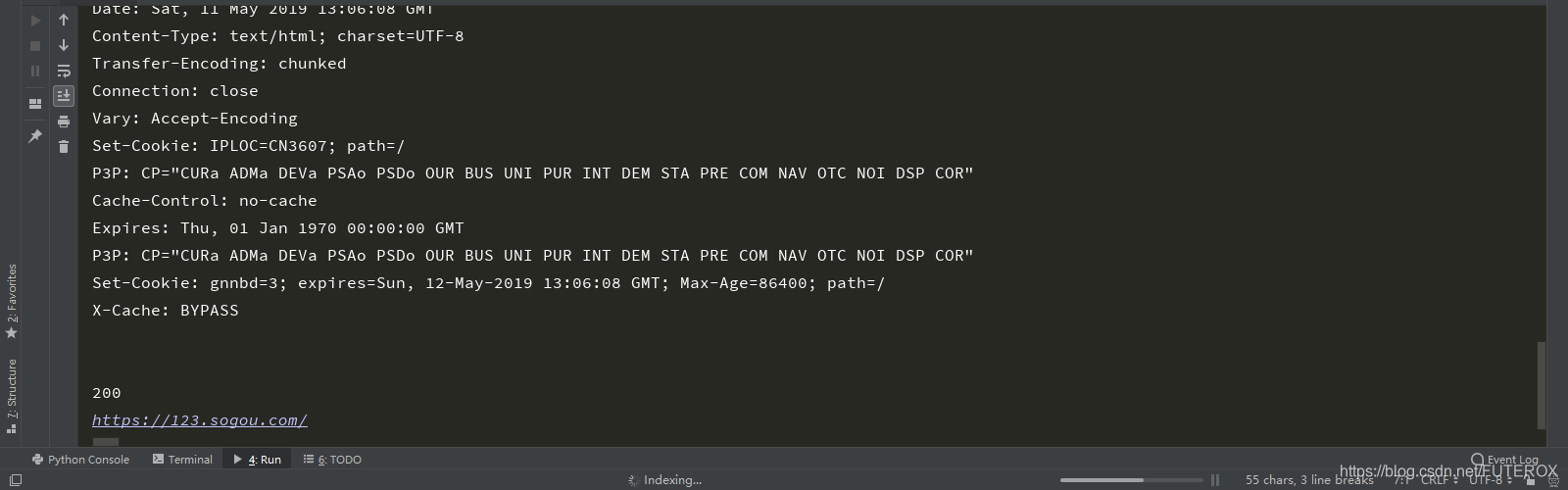
完整代码
import urllib.request as u
r=u.urlopen('https://123.sogou.com/')
u.urlcleanup()
print(r.read().decode('utf-8','ignore'))
print(r.info())
print(r.getcode())
print((r.geturl()))
那么今天就这样吧。等等来个结束福利!
实战示例(福利)
`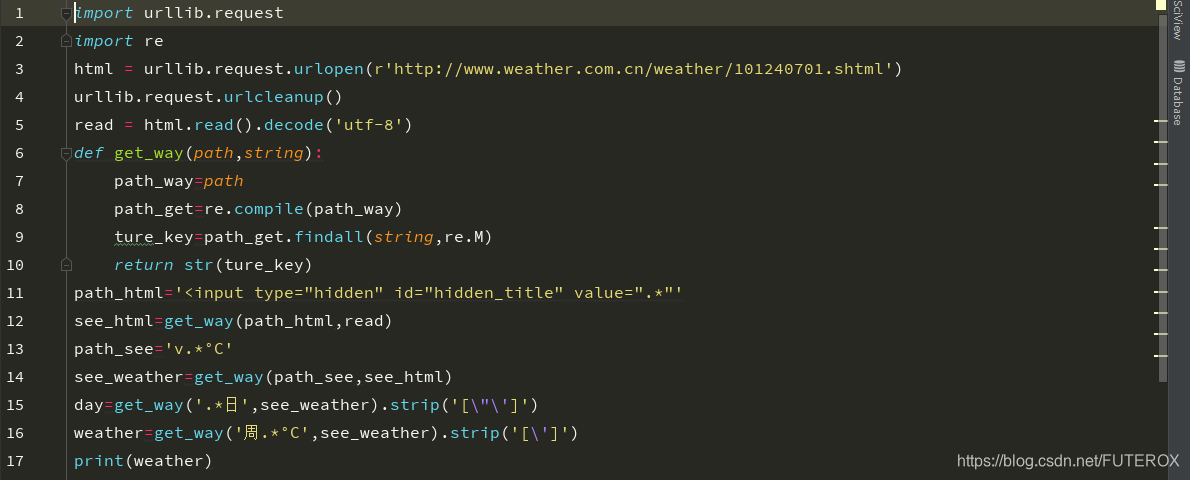
import urllib.request
import re
html = urllib.request.urlopen(r'http://www.weather.com.cn/weather/101240701.shtml')
urllib.request.urlcleanup()
read = html.read().decode('utf-8')
def get_way(path,string):
path_way=path
path_get=re.compile(path_way)
ture_key=path_get.findall(string,re.M)
return str(ture_key)
path_html='<input type="hidden" id="hidden_title" value=".*"'
see_html=get_way(path_html,read)
path_see='v.*°C'
see_weather=get_way(path_see,see_html)
day=get_way('.*日',see_weather).strip('[\"\']')
weather=get_way('周.*°C',see_weather).strip('[\']')
print(weather)
http://www.weather.com.cn/weather/101240701.shtml 天气查询网站。
得嘞 拜了个拜!下次表达式基础语法(用性命担保这个实战示例绝对没有超出今天内容)


















 9737
9737

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











