




这里只简要介绍一下YOLOv2,谈谈想法。
关于YOLOv2,下面的这篇介绍的已经很详尽了:
https://www.jianshu.com/p/032b1eecb335
首先罗列一些它做了什么:

从上往下数:
1.BN,在所有的卷积层后面添加BN层,移除dropout
2.high resolution classifier,在高分辨图像上对分类网络finetune
3.convolutional、anchor boxes和dimension priors:
使用anchor box,所以输出的和faster rcnn或者是和SSD一样,对于每一个anchor都有一组输出。通过使用average pooling可以实现全卷积网络,最后的anchor box输出用卷积来实现,在20个类别上,最后的输出有125层,是5(Anchor数量)*25(5(b-box)+20(类别))。最后附加一个NMS。但因为效果不好,文中使用了k-means对GT-box聚类,得到了几个中心的大小,然后最终选取了5个Anchor,这个就是dimension priors。
4.location prediction
对于Anchor,还做了一点修正,采用的是YOLOv1中的方法,也就是划分grid,b-box中心在grid里头这么一个限制,而不是一般的无约束Anchor方法,同时,也对需要预测的值进行了一些变换,如下:

其中,cx,cy指的是anchor的中心,pw,ph是anchor的宽高,预测的值是tx,ty这些带t的,等式左边是从预测值得到的反映在图像上的b-box形状和位置。
5.pass through,指的就是其中的一个跨层连接
6.multi-scale,由于是全卷积,所以使用了和SPP-Net中一样的多尺度训练。
7.hi-res dector和new-network,指的是去除掉分类网络的最后一层,添加上1024的3*3卷积,最后使用1*1卷积得到指定的输出。
另外还有:
8.层次结构的分类器,也就是有大类(狗)和小类(哈士奇)标签,利用了ImageNet的结构,方法还是统一输出,但是对于每一个阶段都有一个预测,如下图演示:
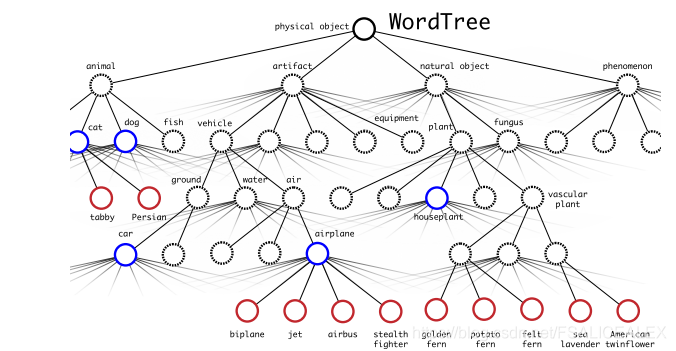
然后我们先找到对于大类中最大的概率,再在其子类中递归寻找,最终得到预测结果。由于是同一输出,网络的结构也不用改变
9.joint classification and detection。说的就是如果是单纯的分类任务,我们就只计算分类的损失,而定位部分只用来给出IOU的预测。
损失函数以及训练方法:
损失函数的设计与之前相似,但是训练方法与YOLOv1不一样。由于是采用了Anchor的方法,训练方法采用了SSD的方式,这一点在文中竟然没有说,看了上面的那篇博文才知道。
总结:
感觉没有特别大的亮点吧,总体结构上差不多,使用了很多种技巧,每一种技巧都有改善,这一点是很不错的。


















 2691
2691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









