







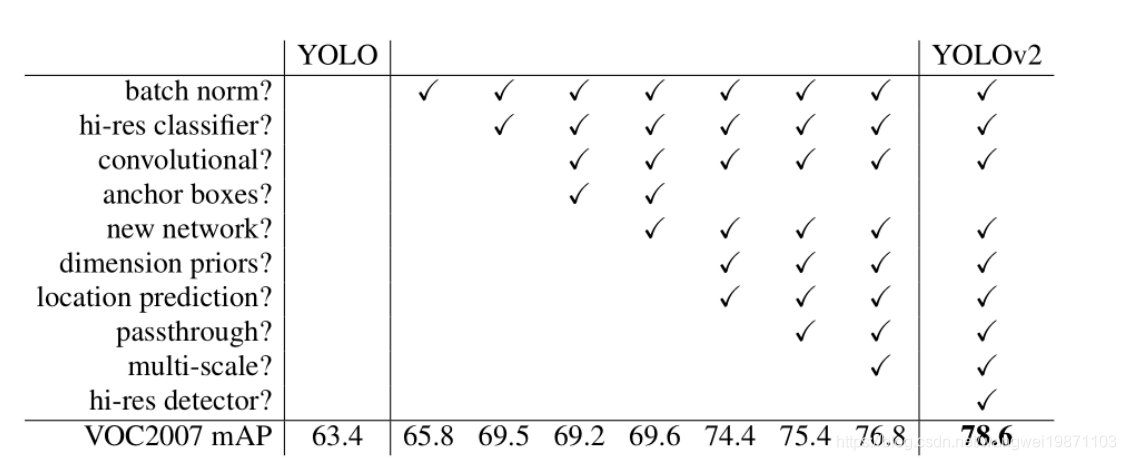
 YOLO v2通过批量归一化、高分辨率分类器、带有锚框的卷积等改进,提升了检测速度和准确性。引入维度聚类、直接位置预测、细粒度特征、多尺度训练等技术,增强小物体检测能力。
YOLO v2通过批量归一化、高分辨率分类器、带有锚框的卷积等改进,提升了检测速度和准确性。引入维度聚类、直接位置预测、细粒度特征、多尺度训练等技术,增强小物体检测能力。
目标检测学习-YOLO-v2
改进
YOLO v2相对于v1做了不少改进,使得速度和准确率都有所提升,具体的看下面的介绍,新版的口号叫做更好,更快,更强。
Batch Normalization(批量归一化)
批量归一化,其实就是一种在每个卷积层输入数据前,把数据进行归一化,希望数据分布基本相似,避免了模型总是要对于不同分布的数据进行适应,加快了训练速度,同时还能避免梯度爆炸和梯度消失的问题,且有一定的正则化作用,避免过拟合,取消了Dropout使用。
High Resolution Classifier(高分辨率分类器)
为了适应高的分辨率,在训练的最后几个epoch用448x448的分辨率进行调整,以便于适应高分辨率。
Convolutional With Anchor Boxesr(带有锚框的卷积)
用类似于RPN网络的锚框来进行预测边界框,删除了全连接层,缩小了网络,减少了参数,输入为416x416,最后卷积为13x13,为奇数,为了让中心点只属于1个格子,而不是周围的4个格子,否则要用4个格子来预测物体了,提高了效率。另外yolo v1的特征是关于1个格子里5xB+c个特征,而v2是每一个预测框都有5+c个特征,从关注格子到关注每一个框了。
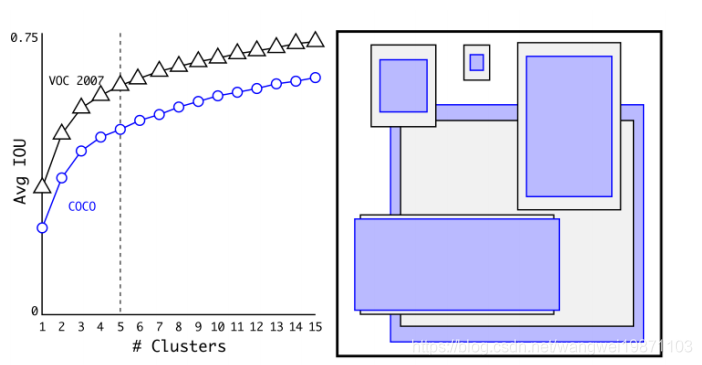
Dimension Clusters(维度聚类)
解决挑选框的问题,利用了聚类的方法来选出比较合适的框,发现k=5的时候最为合适。距离定义为:
d
(
b
o
x
,
c
e
n
t
r
o
i
d
)
=
1
−
I
O
U
(
b
o
x
,
c
e
n
t
r
o
i
d
)
d(box,centroid)=1-IOU(box,centroid)
d(box,centroid)=1−IOU(box,centroid)
box是要聚类的框,centroid的分类的中心。这样就是以交并比来作为衡量的标准,比较合适,而不是单一的欧拉距离。
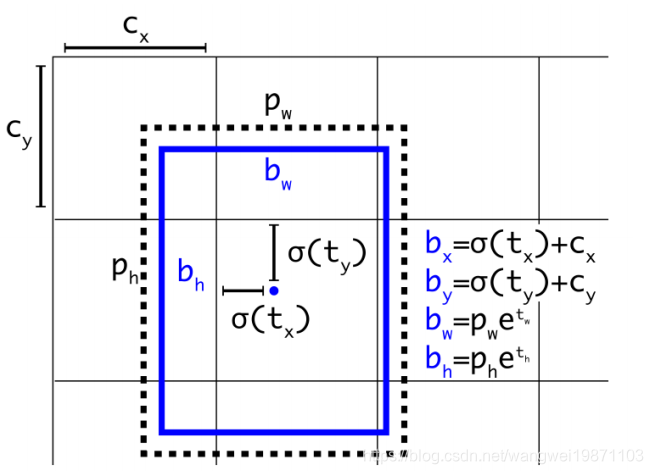
Direct location prediction(直接位置预测)
x
=
(
t
x
∗
w
a
)
−
x
a
x = (t_x ∗ w_a) - x_a
x=(tx∗wa)−xa
y
=
(
t
y
∗
h
a
)
−
y
a
y = (t_y ∗ h_a) - y_a
y=(ty∗ha)−ya
这个是先前的公式,当
t
x
t_x
tx等于正负1时,会移动锚框的宽度,比较大,而我们希望的时得到网格单元的相对位置0-1就可以。
我们给每个网格5个边界框,每个框5个维度 t x , t y , t w , t h , t o t_x,t_y,t_w,t_h,t_o tx,ty,tw,th,to,单元格距离图像左上角偏移 ( c x , c y ) (c_x,c_y) (cx,cy),边界框的先验宽度 p w , p h p_w,p_h pw,ph,预测为:
b
x
=
σ
(
t
x
)
+
c
x
b_x=\sigma (t_x)+c_x
bx=σ(tx)+cx
b
y
=
σ
(
t
y
)
+
c
y
b_y=\sigma (t_y)+c_y
by=σ(ty)+cy
b
w
=
p
w
e
t
w
b_w=p_we^{t_w}
bw=pwetw
b
h
=
p
h
e
t
h
b_h=p_he^{t_h}
bh=pheth
P
r
(
O
b
j
e
c
t
)
∗
I
O
U
(
b
,
O
b
j
e
c
t
)
=
σ
(
t
o
)
Pr(Object)*IOU(b,Object)=\sigma (t_o)
Pr(Object)∗IOU(b,Object)=σ(to)
Fine-Grained Features(细粒度特征)
为了能够检测小的物体,使用了类似残差网络的那种方式,直接将浅层的特征和深层的特征合并作为输入,使得能一定程度的保留小物体的特征。
Multi-Scale Training(多尺度训练)
为了在不同的分辨率上检测,把全连接层改成了卷继承,尝试了一系列不同的分辨率训练,每几个批次换不同的分辨率,以便于网络适应多分辨率。
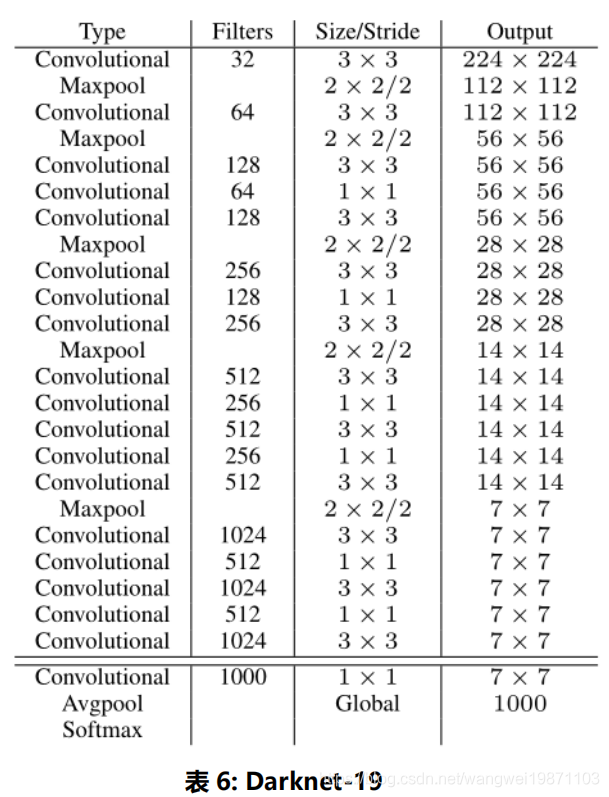
Darknet-19
提出了一种新的网络结构,更加小,更加快。参考了很多经典网络,用了较多的3x3的卷积升维,用了1x1进行降维。
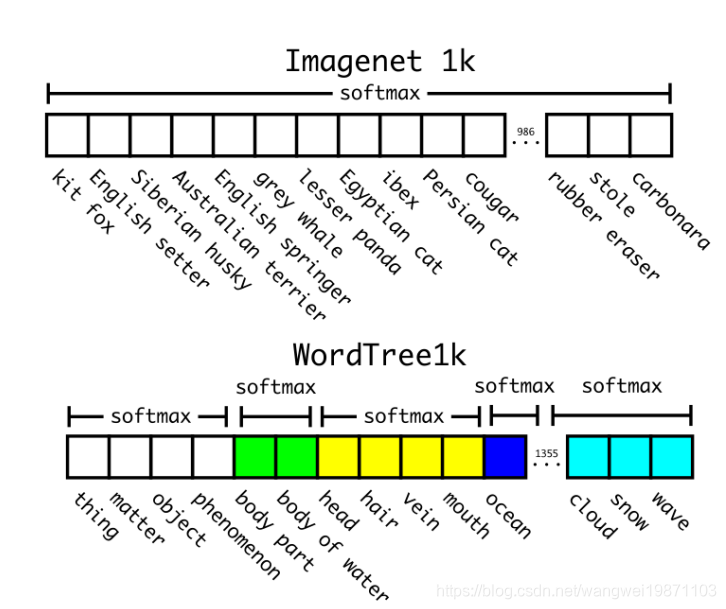
Hierarchical classification(分层分类)
为了让ImageNet和COCO的数据集融合,提出了一种分层分类的概念。即构建一棵树,让每一类都可能有的子类作为他的分支,直到没有子类为止,这样就可以融合两个数据集:
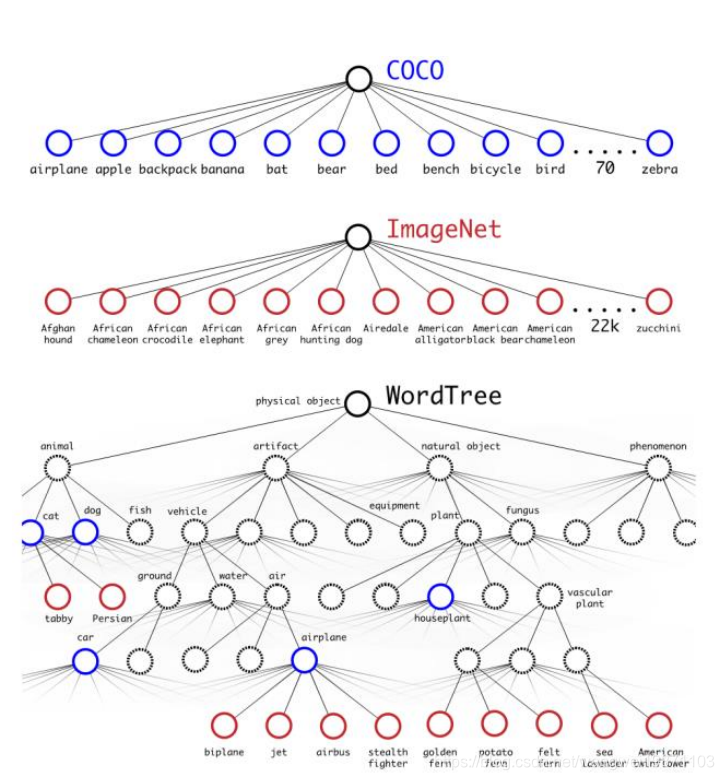
从最开始的根节点出发,选择概率最大且超过一定阈值的子树,一层层的找下去,直到概率小于阈值,说明不是该类,或者没有子类了。从概率的计算来说,就是条件概率,比如一只金毛,那他的概率应该是动物,狗,金毛这条路线,所以应该是这样:
P
r
(
金
毛
)
=
P
r
(
物
体
)
∗
P
r
(
动
物
∣
物
体
)
∗
P
r
(
狗
∣
动
物
)
∗
P
r
(
金
毛
∣
狗
)
Pr(金毛)=Pr(物体)*Pr(动物|物体)*Pr(狗|动物)*Pr(金毛|狗)
Pr(金毛)=Pr(物体)∗Pr(动物∣物体)∗Pr(狗∣动物)∗Pr(金毛∣狗)
其实就是很多个子类的softmax再softmax:
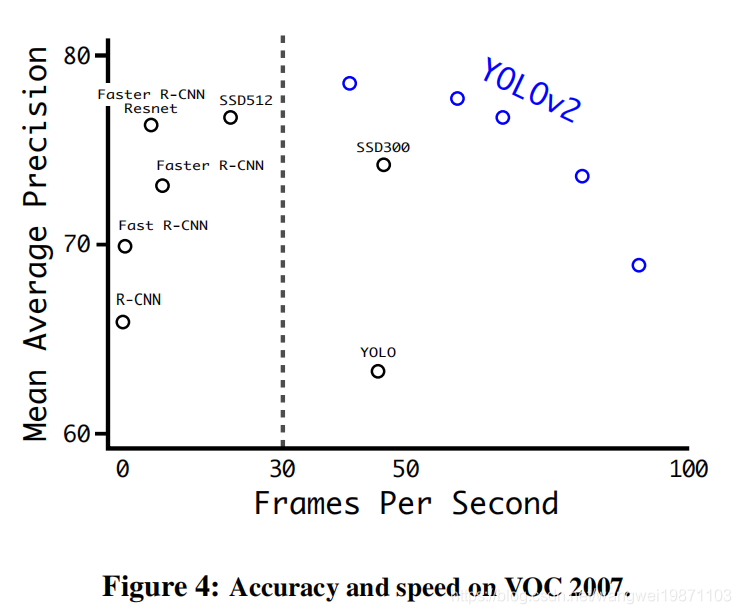
yolo v2整体来说都是不错的:
好了,今天就到这里了,希望对学习理解有帮助,大神看见勿喷,仅为自己的学习理解,能力有限,请多包涵,图片来自网络,侵删。


















 2548
2548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









