



第二次作业 数据库创建和SQL查询语句
- 安装IDE
上次实验是在终端启动MySQL实现的,这次我们可以先下载IDE,得到可视化操作,这里我们下载MySQL Workbench
首先,点击下载地址https://dev.mysql.com/downloads/workbench/
点击下载后直接根据安装向导下载即可,下载完成后
我们需要在终端以管理员身份先运行MySQL: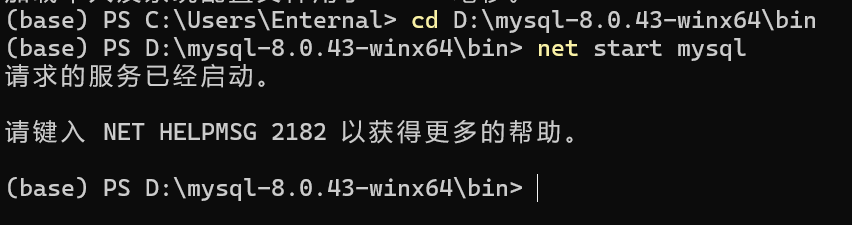
这里不用管理员好像运行不了(
(base) PS D:\mysql-8.0.43-winx64\bin> net start mysql发生系统错误 5。
拒绝访问。)
系统错误 5就是说明我们需要管理员权限
之后运行MySQL Workbench点击Database,选择Connect to Database
配置如下,连接我们本地的MySQL,选择本地IP,端口号3306
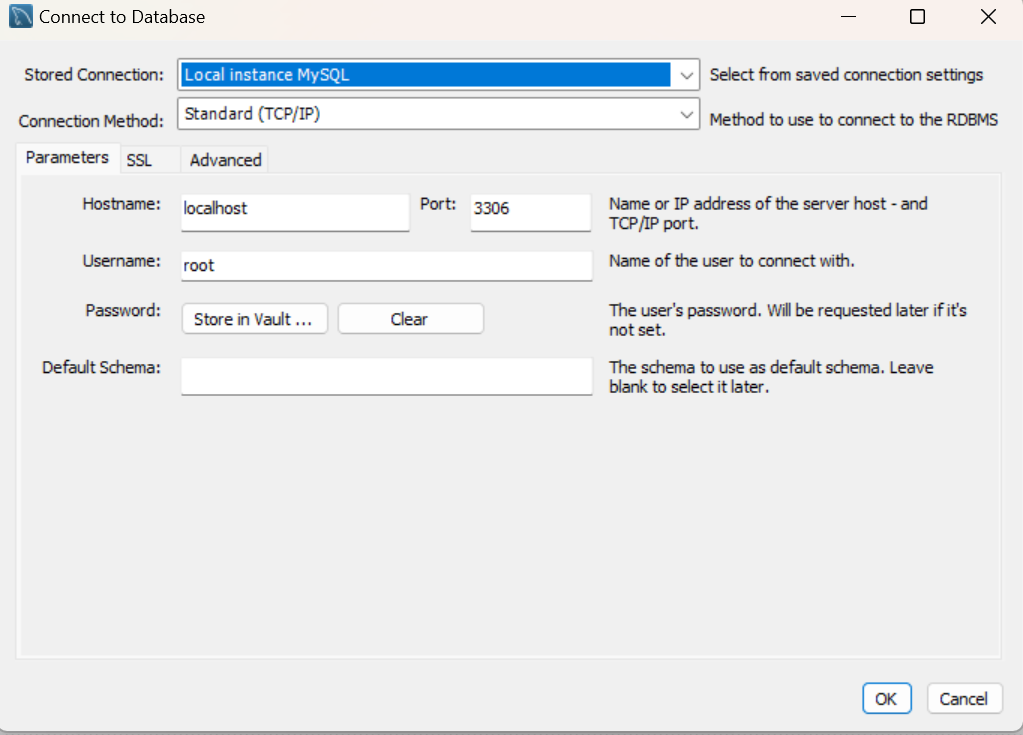
这里注意密码是之前我们设置的,不要输错
成功输入密码后即可进入数据库页面
- 创建数据库
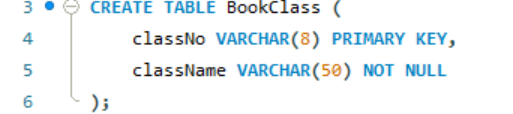
- 根据两个文档的内容,我们可以得到5张核心表:
图书分类表(BookClass):存储图书分类信息
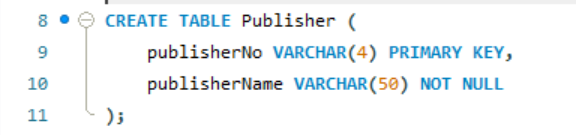
出版社表(Publisher):存储出版社编号与名称
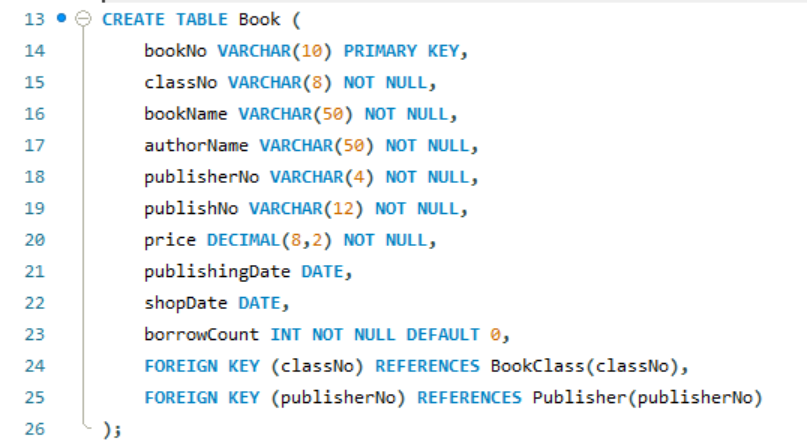
图书表(Book):存储图书详细信息,关联分类表与出版社表
读者表(Reader):存储读者个人信息
借阅表(Borrow):存储借阅记录,关联读者表与图书表
- 接着在MySQL Workbench中左侧的Navigator页面下方切换至Schemas界面,右键空白区,选择Create schema
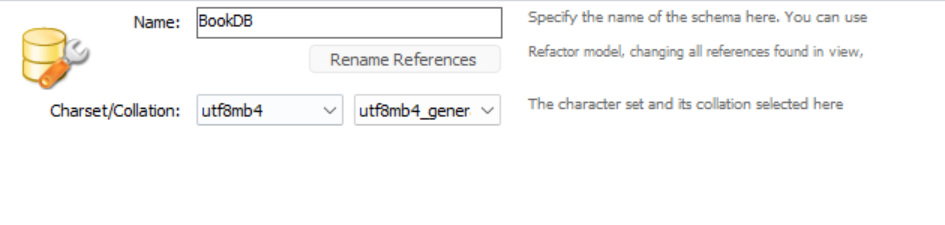
创建BookDB数据库:


- 导入数据
- 数据预处理
由于数据库中的日期是YYYY-MM-DD,参考数据是月/日/年格式,需要先进行预处理
打开excel之后将数据格式调为YYYY-MM-DD
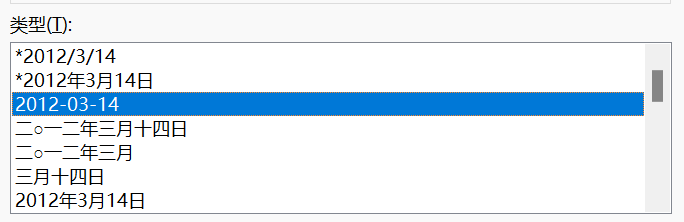
之后要将其转为csv格式
- 导入数据(以bookclass表为例)
右键bookclass表,选择Table Data Import Wizard
之后选择我们准备好的文件

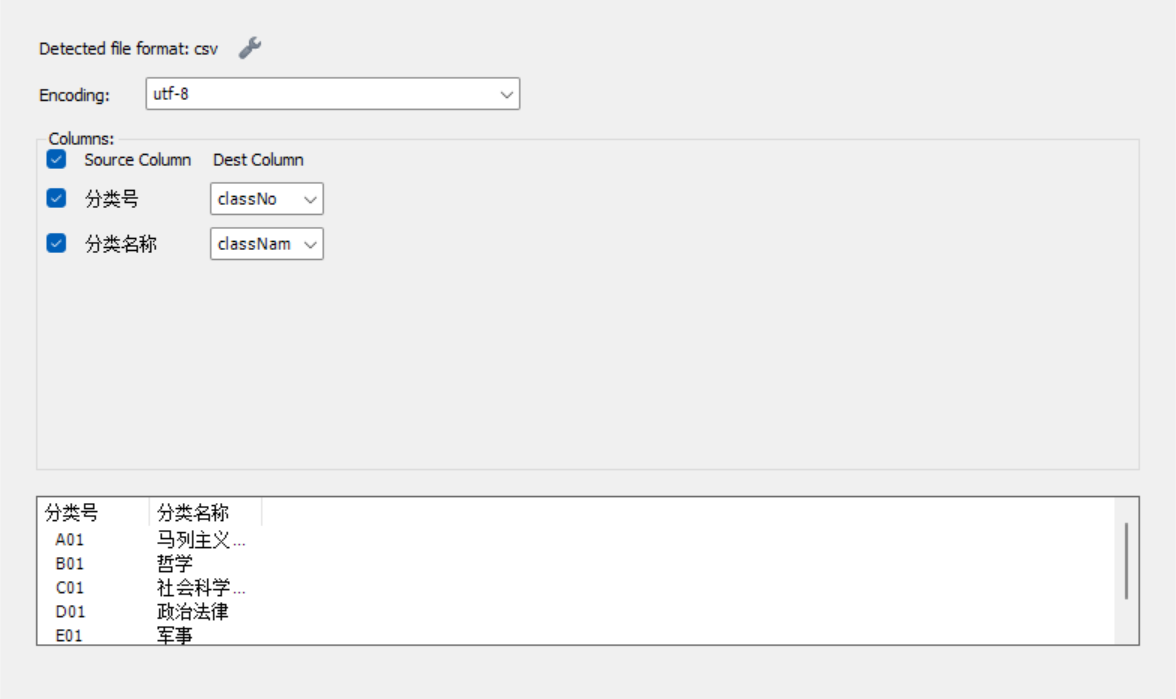
核对列映射,之后完成导入。
重复上述操作可以完成剩余的表
- 完成查询操作
- 查询1991年出生的读者姓名、工作单位和身份证号。
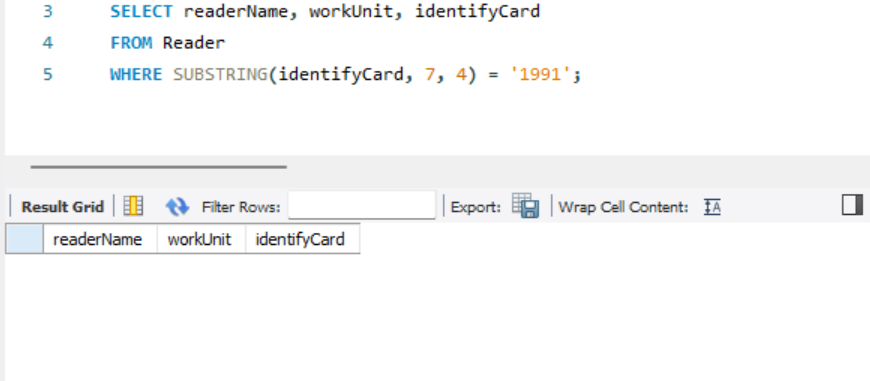
可以发现没有查询到结果(excel表格里面发现确实没有1991年出生的读者)
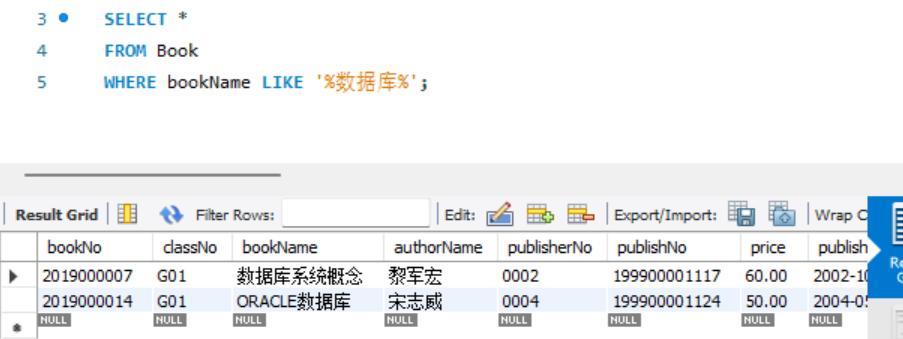
- 查询图书名中含有"数据库"的图书的详细信息。
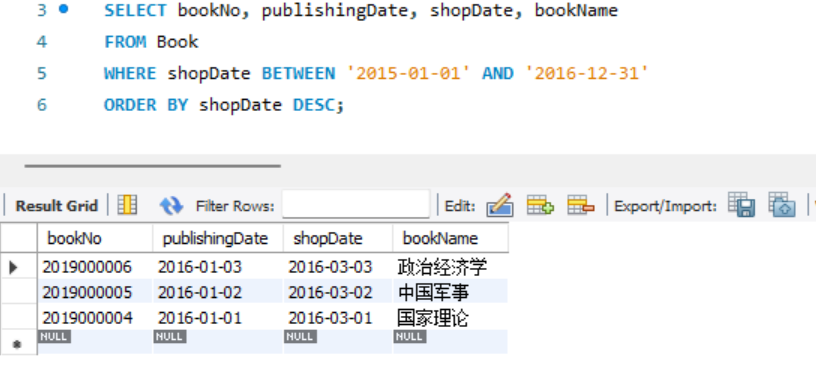
- 查询在2015-2016年之间入库的图书编号、出版时间、入库时间和图书名称,并按入库时间的降序排序输出。
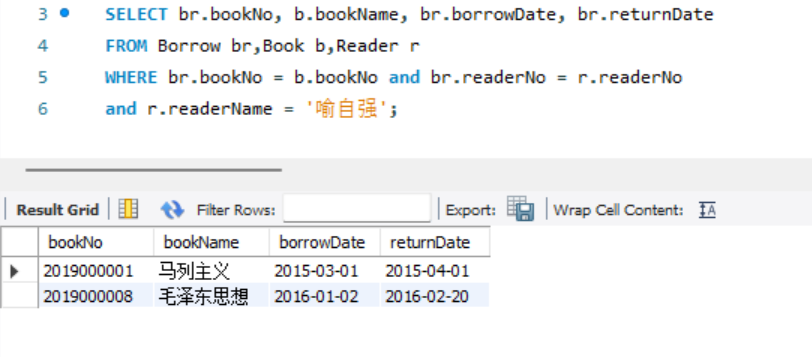
- 查询读者"喻自强"借阅的图书编号、图书名称、借书日期和归还日期。
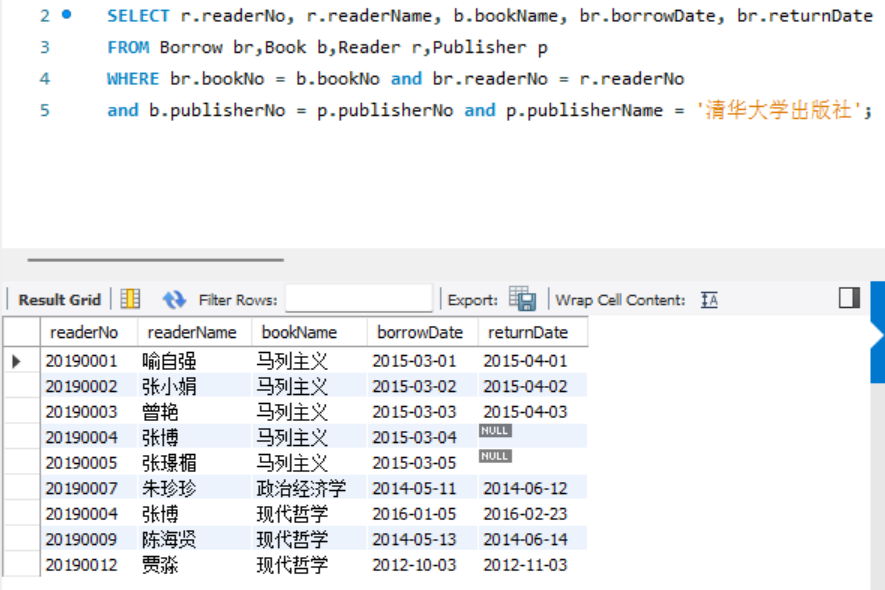
- 查询借阅了清华大学出版社出版的图书的读者编号、读者姓名、图书名称、借书日期和归还日期。
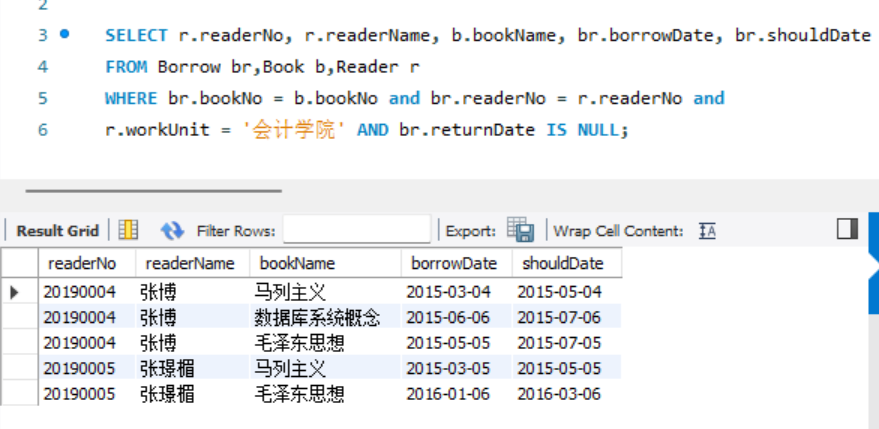
- 查询会计学院没有归还所借图书的读者编号、读者姓名、图书名称、借书日期和应归还日期。
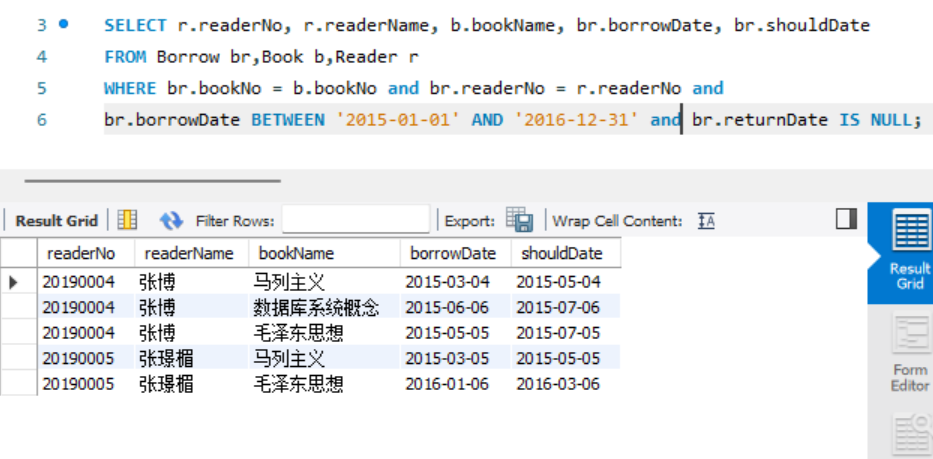
- 查询在2015-2016年之间借阅但还未归还图书的读者编号、读者姓名以及这些借阅未归还图书的图书编号、图书名称和借书日期。
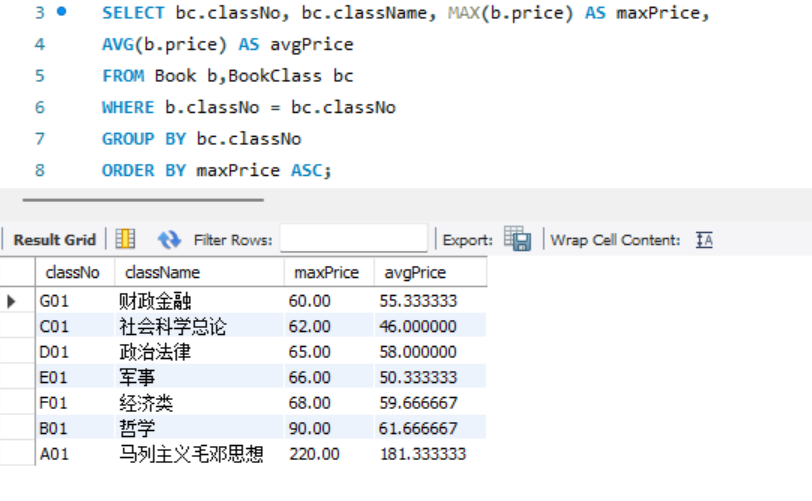
- 查询每种类别图书的分类号、分类名称、最高价格和平均价格,并按最高价格的升序输出。
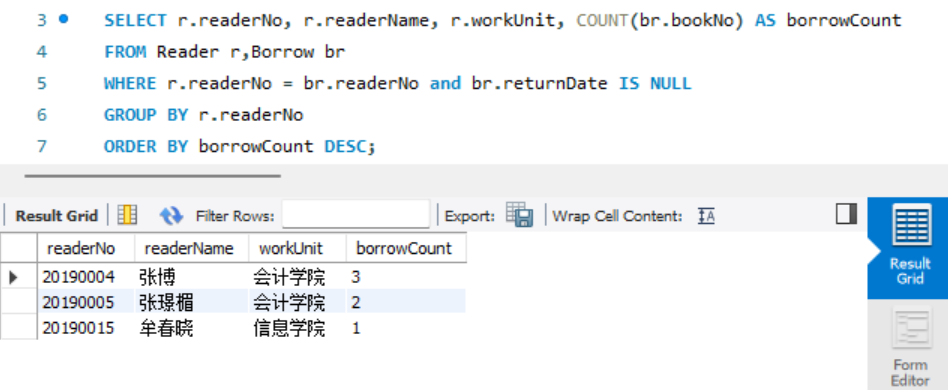
- 查询每个读者在借(即借阅未归还)的图书数量、读者编号、读者姓名和工作单位, 并按借书数量的降序排序输出。
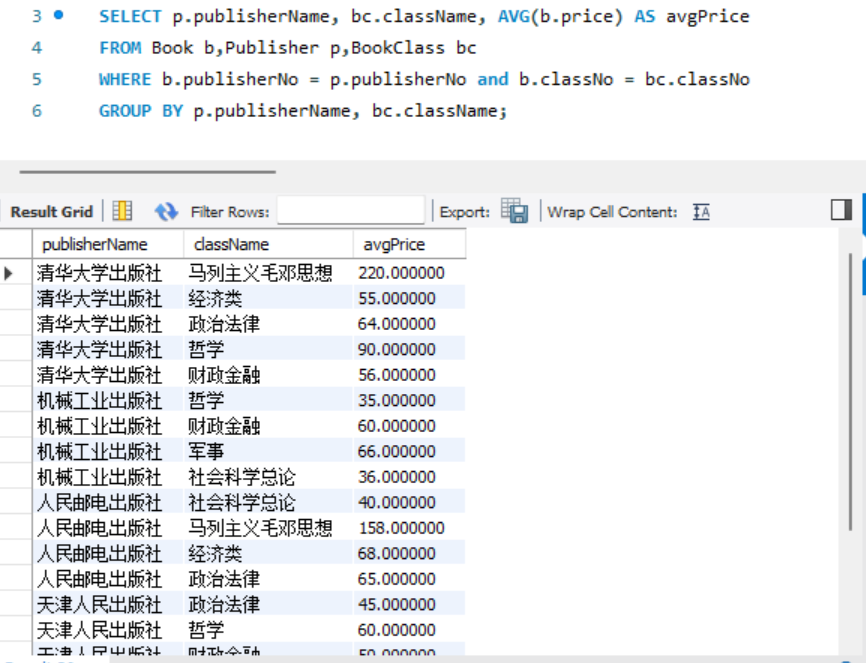
- 查询每个出版社出版的每种类别的图书平均价格,要求显示出版社名称、图书类 别名称和平均价格。
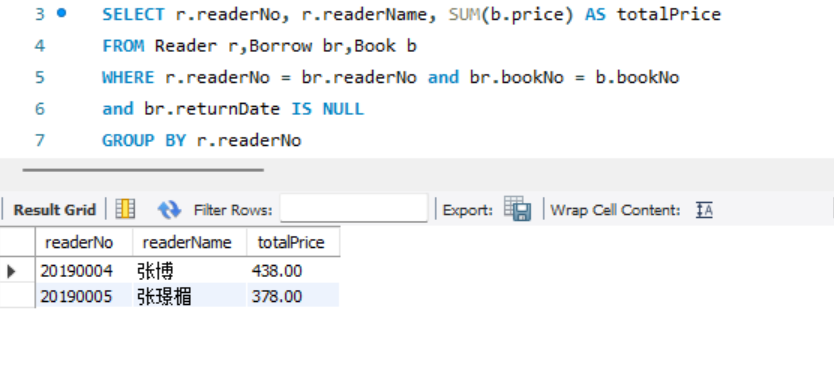
- 查询在借图书的总价不低于200元的读者编号、读者姓名和在借图书总价。
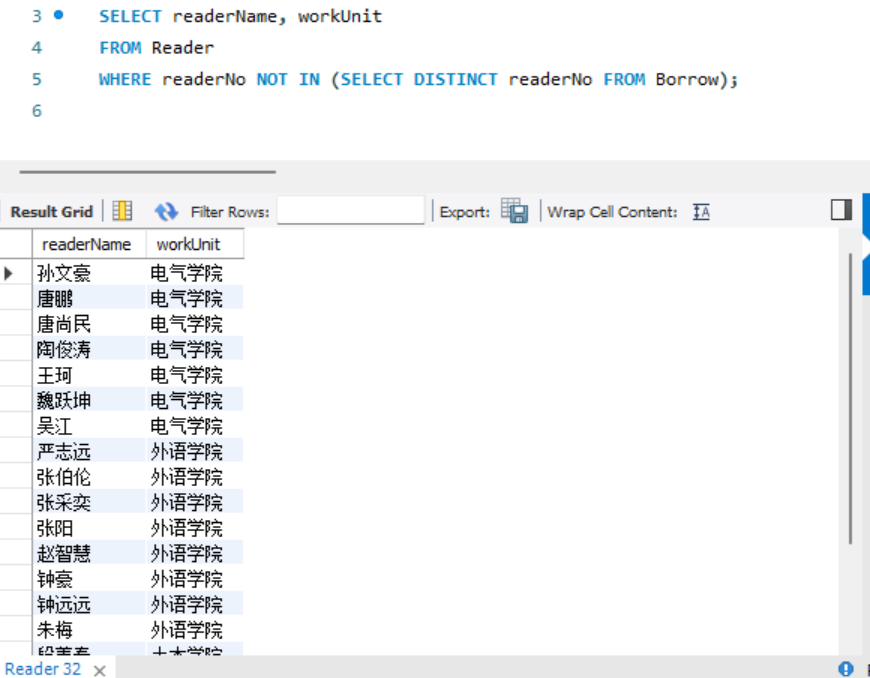
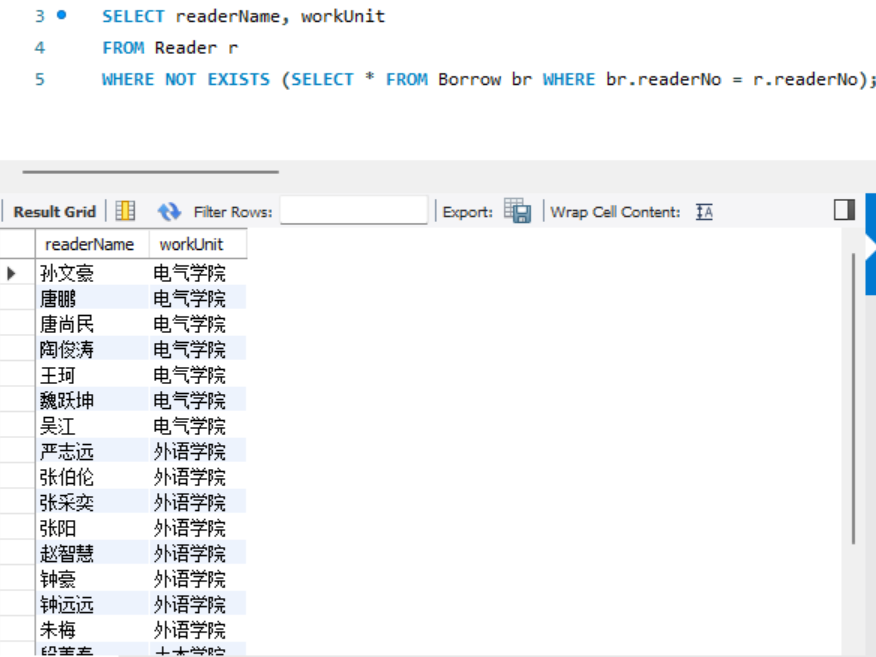
- 查询从来没有借过书的读者姓名和工作单位(分别使用IN子查询和存在量词子查询表达)。
IN子查询:
存在量词子查询:
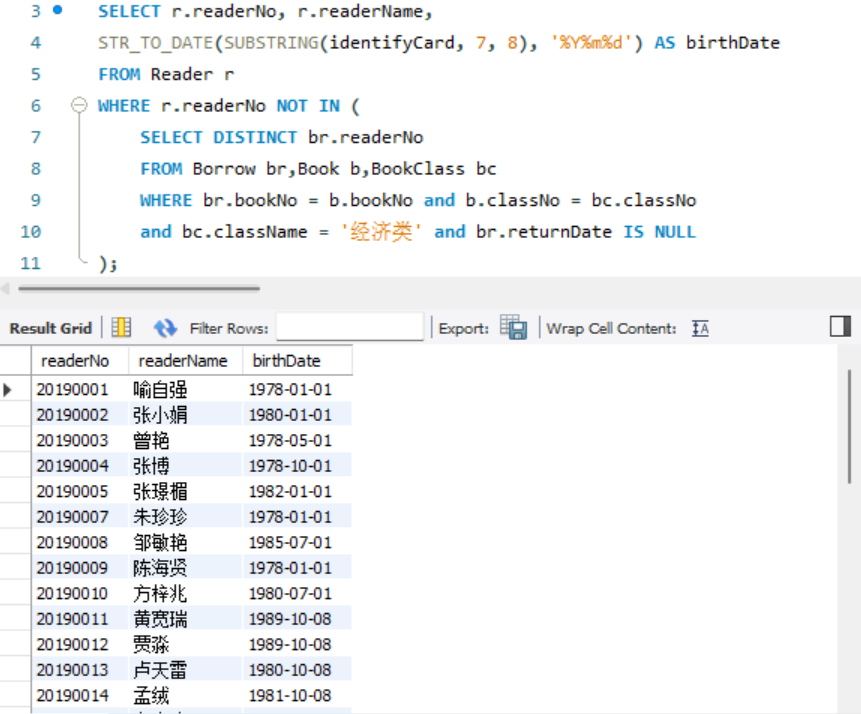
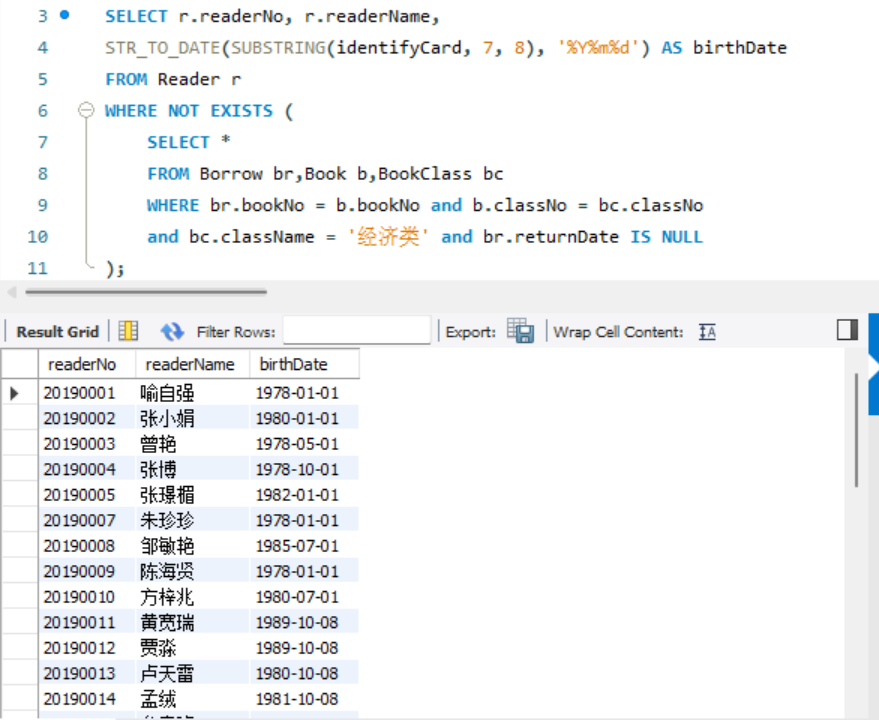
- 查询目前没有在借"经济类"图书的读者编号、读者姓名和出生日期(分别使用IN 子查询和存在量词子查询表达)。
IN子查询:
存在量词子查询:
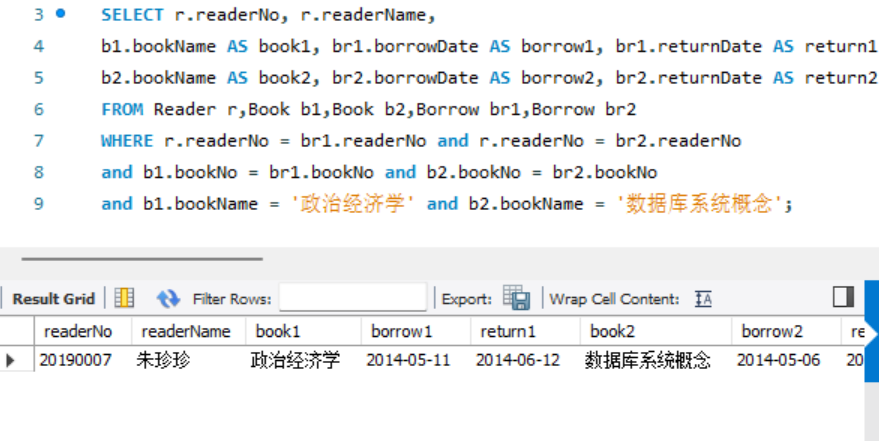
- 查询既借阅过"政治经济学"图书又借阅过"数据库系统概念"图书的读者编号、读者姓名以及这两种图书的图书名称、借书日期和归还日期。
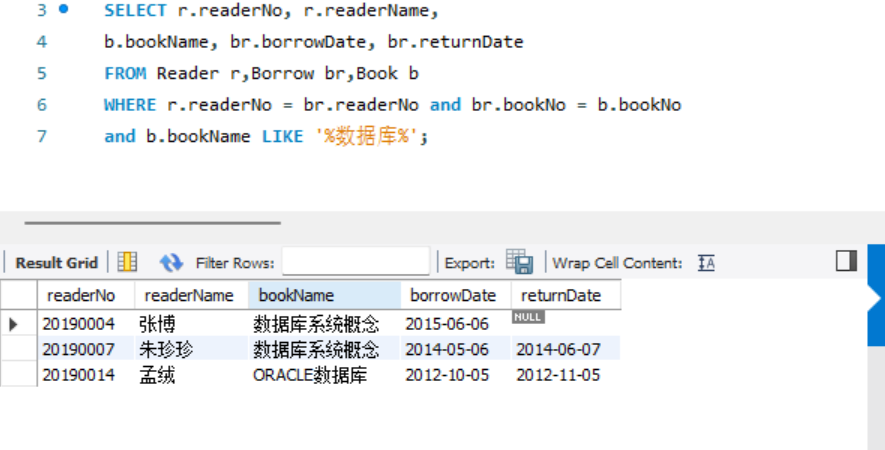
- 查询借阅过图书名称中包含"数据库"的所有图书的读者编号、读者姓名以及他们所借阅的这些图书的图书名称、借阅日期和归还日期。

















 1117
1117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









