








📝个人主页🌹:Eternity._
🌹🌹期待您的关注 🌹🌹


概述
FCOS提出了一个全卷积的单阶段目标检测器,以逐像素预测的方式解决目标检测,类似于语义分割。FCOS通过消除预先定义的锚框集合,完全避免了训练过程中与锚框相关的复杂计算,例如与锚框相关的所有超参数,而这些参数通常对最终的检测性能非常敏感。
本文所涉及的所有资源的获取方式:这里
模型架构
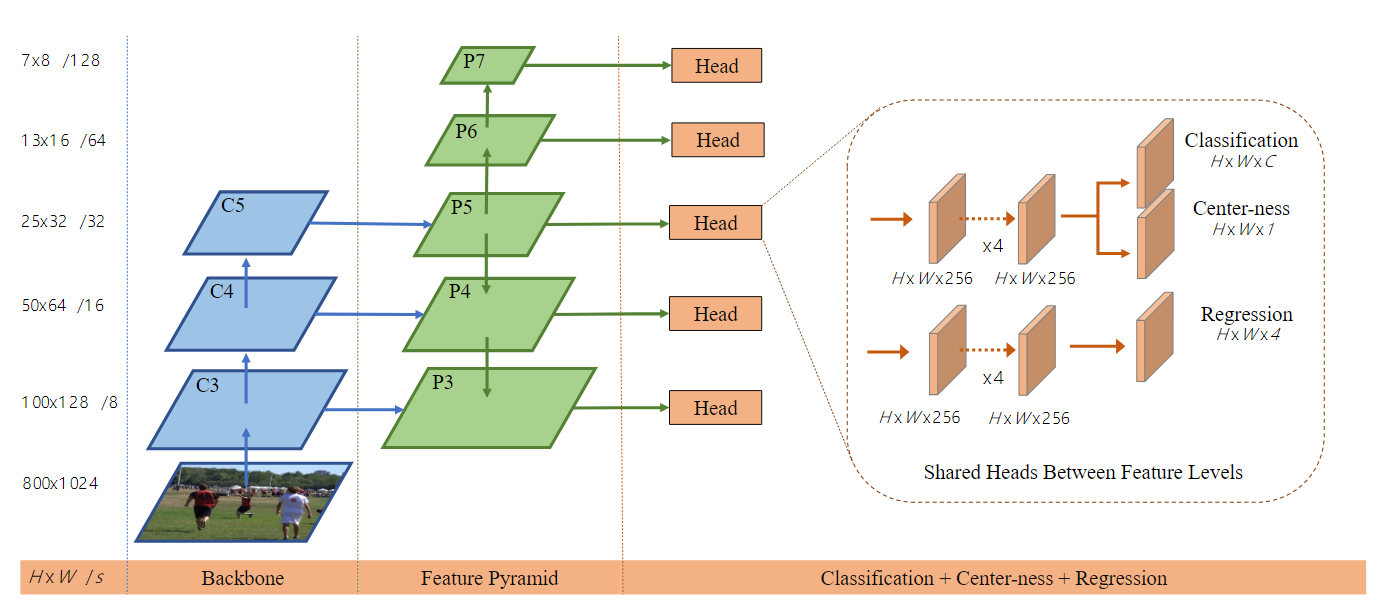
如图是FCOS的网络架构,其中C3、C4、C5表示骨干网络的特征图,P3到P7是用于最终预测的特征级别,H×W是特征图的高度和宽度。
网络输出
对应于训练目标,FCOS网络的最后一层预测分类标签得80D向量p(此时是COCO数据集,总共有90类)和4D边界框坐标向量t=(l,t,r,b)。FCOS网络不是训练一个多类分类器,而是训练C个二元分类器。和Focal Loss相同,FCOS网络分别在主干网络的特征图之后添加四个卷积层进行分类和回归分支。此外,由于回归目标总是正的,FCOS网络使用exp(x)将任何实数映射到回归分支顶部的(0,+∞)。值得注意的是FCOS的网络输出变量比流行的基于锚的检测器少九倍,因为流行的基于锚框的检测器每个位置由9个锚框。
损失函数
FCOS网络将训练损失定义如下

核心逻辑
返回特征图上每个像素点对应的bbox
def prepare_targets(self, points, targets):
object_sizes_of_interest = [
[-1, 64], # 不同的FPN层每层需要规定检测目标的大小
[64, 128],
[128, 256],
[256, 512],
[512, INF],
]
# 扩展感兴趣区域的事情
expanded_object_sizes_of_interest = []
# points指代的是坐标,针对每一个坐标都应该有一个bbox
for l, points_per_level in enumerate(points):
object_sizes_of_interest_per_level = \
points_per_level.new_tensor(object_sizes_of_interest[l])
expanded_object_sizes_of_interest.append(
object_sizes_of_interest_per_level[None].expand(len(points_per_level), -1)
)
# [22400,2]
expanded_object_sizes_of_interest = torch.cat(expanded_object_sizes_of_interest, dim=0)
# [num_points_per_level] 获取不同特征图上具有的点的个数
num_points_per_level = [len(points_per_level) for points_per_level in points]
self.num_points_per_level = num_points_per_level
# 确定5个FPN结构上有多少个点,此时的个数和上述的Iou一致,对于每个点都需要规定一个回归大小的数值
points_all_level = torch.cat(points, dim=0)
# 为每个特征图上的点预定义label的bbox的情况
labels, reg_targets = self.compute_targets_for_locations(
points_all_level, targets, expanded_object_sizes_of_interest
)
# 针对于batch_size个图片,经过backbone,每个图片具有n个点
for i in range(len(labels)):
# 按照FPN结构的网格生成相应地结构
labels[i] = torch.split(labels[i], num_points_per_level, dim=0)
reg_targets[i] = torch.split(reg_targets[i], num_points_per_level, dim=0)
labels_level_first = []
reg_targets_level_first = []
# points表示不同的特征图
for level in range(len(points)):
# 是将不同的batch_size,但是一个层上面的所有点进行拼接
labels_level_first.append(
torch.cat([labels_per_im[level] for labels_per_im in labels], dim=0)
)
reg_targets_per_level = torch.cat([
reg_targets_per_im[level]
for reg_targets_per_im in reg_targets
], dim=0)
if self.norm_reg_targets:
reg_targets_per_level = reg_targets_per_level / self.fpn_strides[level]
reg_targets_level_first.append(reg_targets_per_level)
# 返回一个batch_size中不同特征层上所有的点的拼接,也就是返回五层特征图结构
return labels_level_first, reg_targets_level_first
其中将不同大小的特征图规定回归特定大小的目标,对于仍有多个的情况时选取最小的一个进行回归。
# 为每个位置生成一个target bbox的情况
def compute_targets_for_locations(self, locations, targets, object_sizes_of_interest):
labels = []
reg_targets = []
xs, ys = locations[:, 0], locations[:, 1] # 分别获得每个x,y的取值
for im_i in range(len(targets)):
targets_per_im = targets[im_i] # 获取每张图片上的真实bbox有多少个
# 此时确定的是真值框的模式
assert targets_per_im.mode == "xyxy"
bboxes = targets_per_im.bbox # 获得bbox的坐标形式
labels_per_im = targets_per_im.get_field("labels") # 获取标签
area = targets_per_im.area() # 获取面积,这里应该都是COCO数据集自带的
# 预测的是ltrb,来进行计算,此时取值为正
l = xs[:, None] - bboxes[:, 0][None]
t = ys[:, None] - bboxes[:, 1][None]
r = bboxes[:, 2][None] - xs[:, None]
b = bboxes[:, 3][None] - ys[:, None]
# [20267,17,4] 17表示此时有多少个bbox,针对于20267个像素,每个像素上可能有17个bbox
reg_targets_per_im = torch.stack([l, t, r, b], dim=2)
if self.center_sampling_radius > 0:
is_in_boxes = self.get_sample_region(
bboxes,
self.fpn_strides,
self.num_points_per_level,
xs, ys,
radius=self.center_sampling_radius
)
else:
# ltrb本身每个取值都应该是正的,min选取它们的最小值,dim=2表明是在坐标的维度上进行选择
is_in_boxes = reg_targets_per_im.min(dim=2)[0] > 0
# 获取四个坐标中最大的一个,其中要保证最大的一个坐标处于确定的坐标范围内
max_reg_targets_per_im = reg_targets_per_im.max(dim=2)[0]
# limit the regression range for each location
is_cared_in_the_level = \
(max_reg_targets_per_im >= object_sizes_of_interest[:, [0]]) & \
(max_reg_targets_per_im <= object_sizes_of_interest[:, [1]])
# 针对于每一个坐标都规定需要回归的面积有area个
locations_to_gt_area = area[None].repeat(len(locations), 1)
# 对于不符合要求的将其定义为INF,也就是背景区域
locations_to_gt_area[is_in_boxes == 0] = INF
locations_to_gt_area[is_cared_in_the_level == 0] = INF
# if there are still more than one objects for a location,
# we choose the one with minimal area
locations_to_min_area, locations_to_gt_inds = locations_to_gt_area.min(dim=1)
# 如果还有多个bbox的时候,选取bbox数值最小的一个来进行回归
reg_targets_per_im = reg_targets_per_im[range(len(locations)), locations_to_gt_inds]
labels_per_im = labels_per_im[locations_to_gt_inds] # 选择数值最小的标签
labels_per_im[locations_to_min_area == INF] = 0 # 对不存在的区域设置为背景区域
labels.append(labels_per_im)
reg_targets.append(reg_targets_per_im)
# 此时返回的是所有位置上需要回归的bbox和cls
return labels, reg_targets
演示效果
运行fcos_demo.py



部署方式
conda create --name FCOS
conda activate FCOS
# this installs the right pip and dependencies for the fresh python
conda install ipython
# FCOS and coco api dependencies
pip install ninja yacs cython matplotlib tqdm
# follow PyTorch installation in https://pytorch.org/get-started/locally/
# we give the instructions for CUDA 10.2
conda install pytorch torchvision cudatoolkit=10.2 -c pytorch
export INSTALL_DIR=$PWD
# install pycocotools. Please make sure you have installed cython.
cd $INSTALL_DIR
git clone https://github.com/cocodataset/cocoapi.git
cd cocoapi/PythonAPI
python setup.py build_ext install
# install PyTorch Detection
cd $INSTALL_DIR
git clone https://github.com/tianzhi0549/FCOS.git
cd FCOS
# the following will install the lib with
# symbolic links, so that you can modify
# the files if you want and won't need to
# re-build it
python setup.py build develop --no-deps
unset INSTALL_DIR
参考文献
编程未来,从这里启航!解锁无限创意,让每一行代码都成为你通往成功的阶梯,帮助更多人欣赏与学习!
更多内容详见:这里

















 3186
3186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









