




 本文探讨了数据分析中异常值的几种类型,包括单值异常、相关性异常和突发异常,并通过实例解释如何识别和处理这些异常值。提到了盖帽法作为处理异常值的一种常见策略,根据置信区间的标准差来决定删除范围。同时,区分了异常值与强影响点,并介绍了回归模型中判断强影响点的方法。最后,讨论了对异常值敏感的模型,如聚类分析和时间序列。
本文探讨了数据分析中异常值的几种类型,包括单值异常、相关性异常和突发异常,并通过实例解释如何识别和处理这些异常值。提到了盖帽法作为处理异常值的一种常见策略,根据置信区间的标准差来决定删除范围。同时,区分了异常值与强影响点,并介绍了回归模型中判断强影响点的方法。最后,讨论了对异常值敏感的模型,如聚类分析和时间序列。
异常值的几种情况
数据分析中,异常值是比较难于界定的,一般数据异常值会有几种情况:
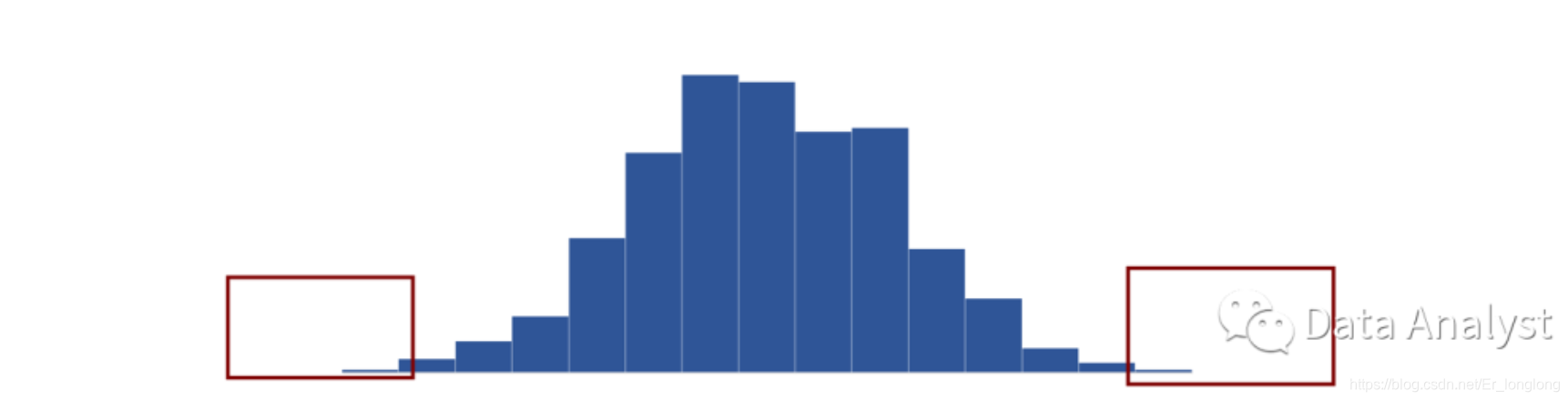
- 单值异常
如下图所示,某市场产品客群的样本分布中,年龄为0-5岁与150-200岁即可判定为异常,一般单值异常需结合实际的业务进行判断。

-
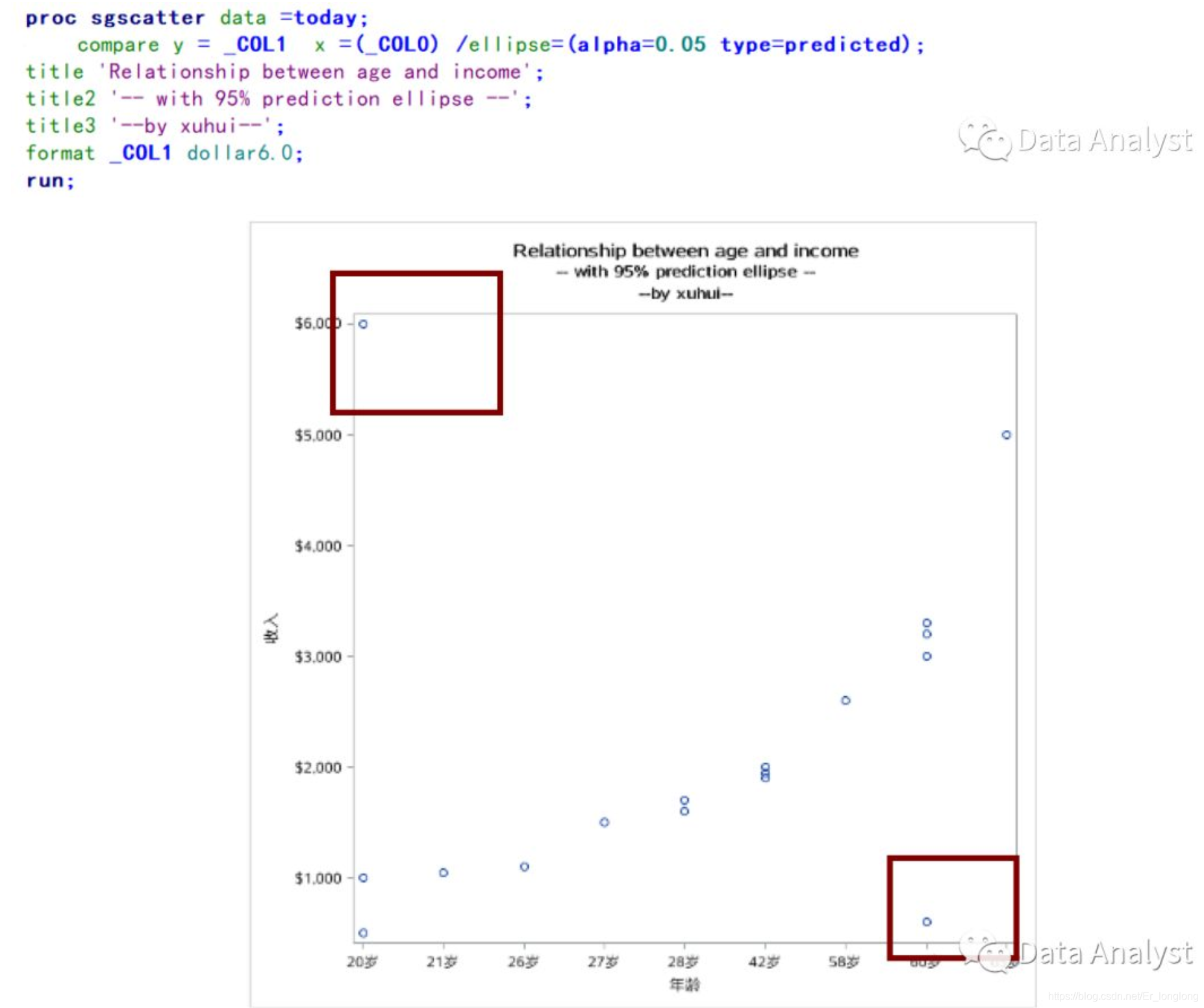
相关性异常
一般收入随年龄的增长呈现类线性趋势,如果出现下图情况,即低龄高收入者(如思聪)、高龄低收入者(如流浪老人),虽也可能属于正常情况,但还是要将其排除在建模样本外。如下为实现该散点图的SAS代码:
-
突发异常
如果出现下图情况,首先需要思考为什么会出现异常值,针对这种激增的异常,我一般会添加一个哑变量,用哑变量去表示该点发生了异常情况。
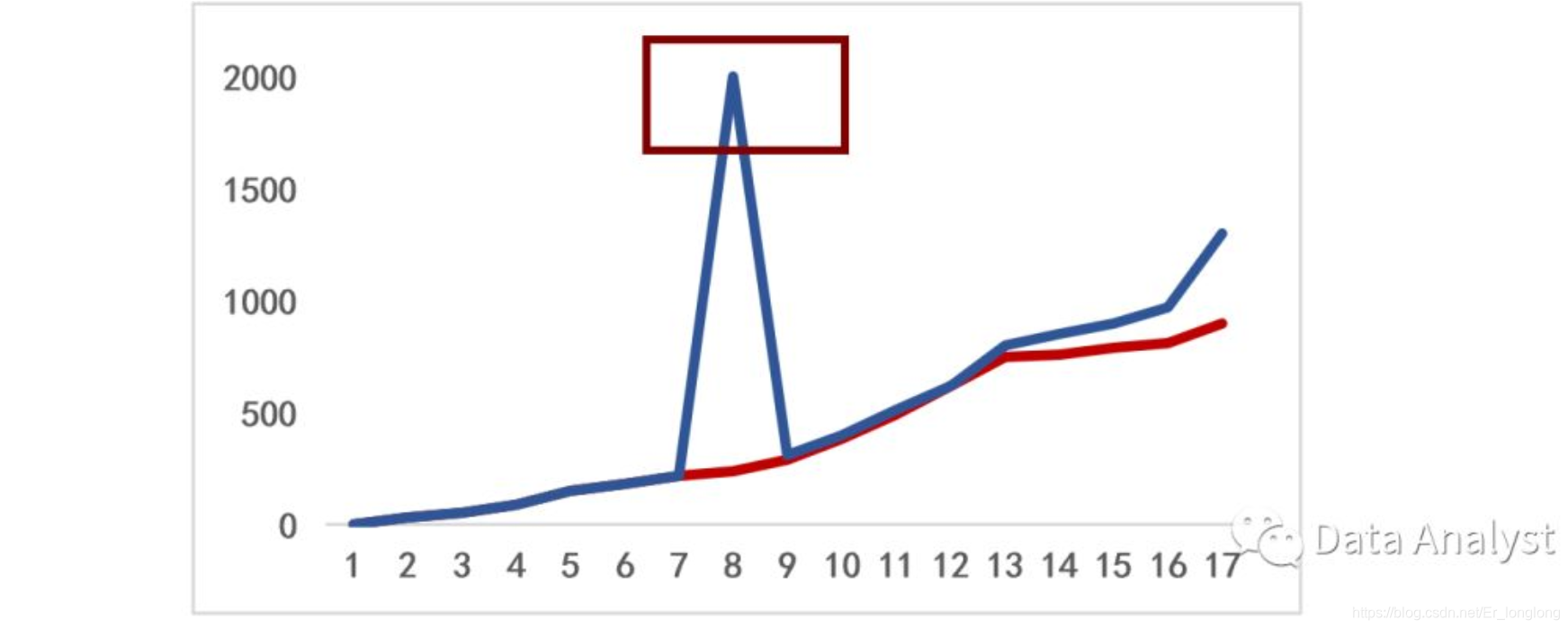
一般,如果判断了该点确实为异常值,我会标记出该点并禁止其入模,这里还需要注意区分强影响点与异常值的区别,如何判断某点是异常值还是强影响点?如果模型中,排除某点后模型并无变动,则该点确实为异常值,如果排除某点后模型被完全改变了,则该点可能为强影响点。
回归中的强影响点
通常,回归模型可以用如下方法判断强影响点:
- 剔出残差
- 杠杆值
- COOK距离
- 协方差比
异常值怎么处理
一般,我习惯用盖帽法去处理数据中的异常值,即:
如果一个置信区间左右两边各有三个标准差,即区间置信度为99%时,一般建议三倍标准差以外删除;而如果一个置信区间左右两边各有两个标准差,即区间置信度为95%,此时到底取两个还是三个标准差则取决于模型对于异常的敏感程度。
通常,回归模型对于异常的敏感程度还算可以,有异常值放在那里也问题不大,但对于对异常值非常敏感的模型,一般需要删除掉两倍标准差以外的异常值了,例如聚类分析。
我认为,比较害怕异常值的两个模型除聚类分析外,另外一个应该就属时间序列了。
我的公众号:Data Analyst
个人网站:https://www.datanalyst.net/



















 1827
1827

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









