






小红书和小绿书平台的图文二次创作近期热度飙升!今天就手把手教你如何用Coze AI一键生成爆款笔记。
实操方案:先收集同领域的爆款笔记作为素材,然后交给AI进行二次创作,自动生成吸睛标题、优质文案和精美配图。
图文二创工作流拆分:提取笔记内容-文案重写-文案配图-内容发布。
1.内容提取: 浏览小红书,寻找热门笔记。提取笔记中的文本信息,包括标题、正文等。
2.文案二创: 基于小红书笔记的原始文本,进行文案的创意构思和重写。保留原文的核心内容,同时引入新的元素和创意,优化标题以吸引目标读者。
3.文案配图: 根据创新后的文案内容,选择合适的图片和视觉设计元素。
4.内容发布: 在发布前进行测试,确保内容在平台上的展示效果。将调整后的图文内容发布至小红书平台。
1:创建工作流
登陆Coze官网:https://www.coze.cn/
点击“工作空间”-“工作空间”-“资源”,点击到新建“工作流”选项。

创建工作流的名称和工作流描述。工作流名称只允许字母、数字和下划线,并以字母开头。

填写好工作流名称与描述后,点击确定,进入到如下图的工作流搭建的界面。

这里可以看到工作流必须要有的两个模块,“开始“和”结束”两个模块。
我们现在需要再中间加入我们需要工作流中需要用的其他模块。
2.提取文案
我们想要提取文案,首先需要有文案的链接。
点击“开始”模块,在其中加入变量“URL”,变量类型“String”,描述“小红书链接”。
用户在开始的对话中输入小红书链接就可以给到工作流了。

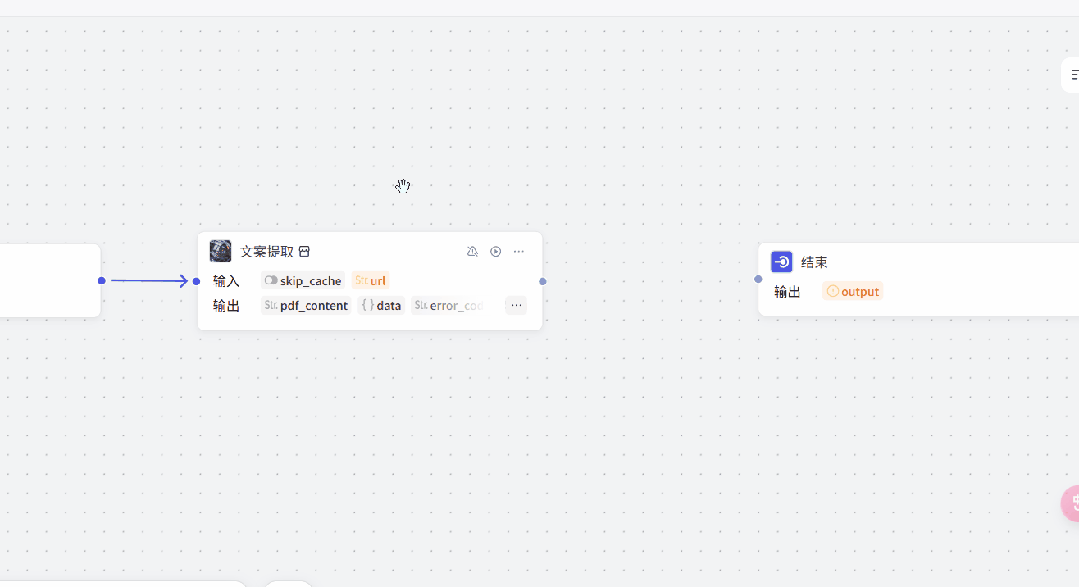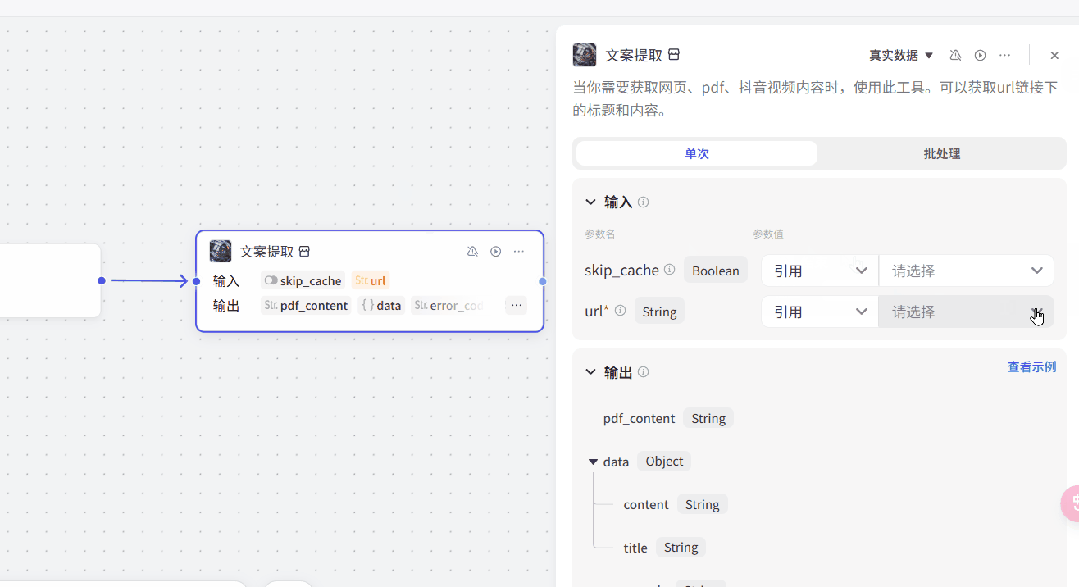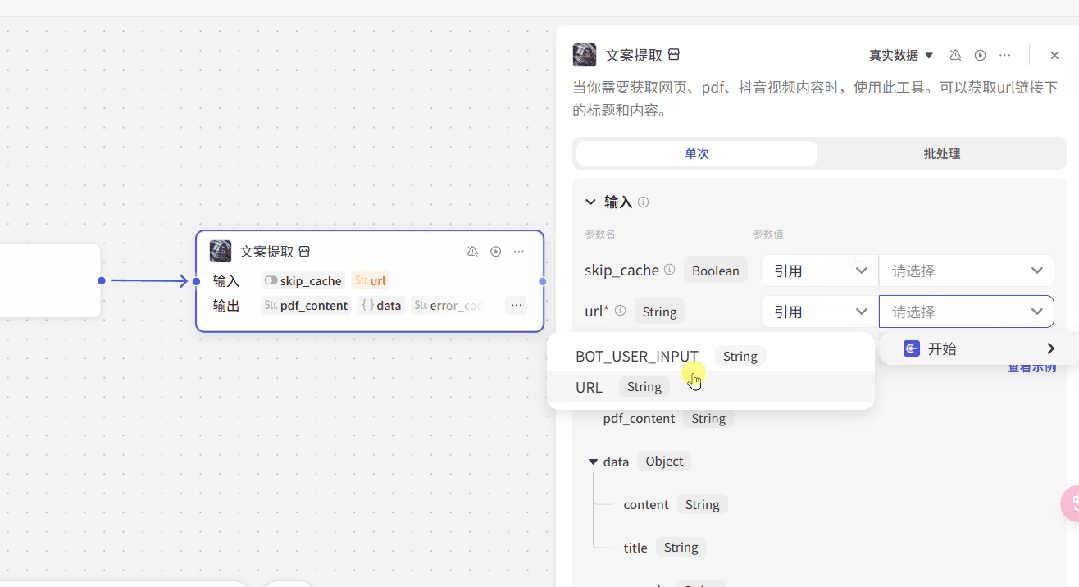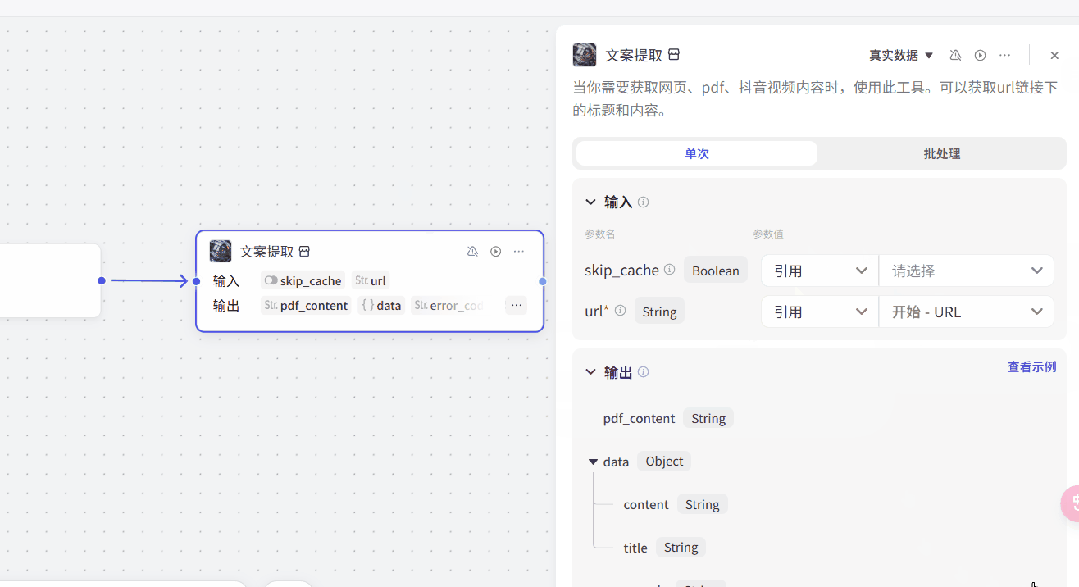
收到用户给到的链接之后小红书链接之后,我们需要获取小红书的文案内容,包括标题、正文等内容,这里需要用到“链接读取”插件。
点击“插件”。

在搜索框中输入“链接读取”,找到Coze提供的这个插件,然后选择下方的"LinkReaderPlugin"插件。
当你需要获取网页、pdf、抖音视频内容时,使用此工具。可以获取url链接下的标题和内容。
点击右侧的“添加”。

将“开始”与"LinkReaderPlugin"插件链接到一起。
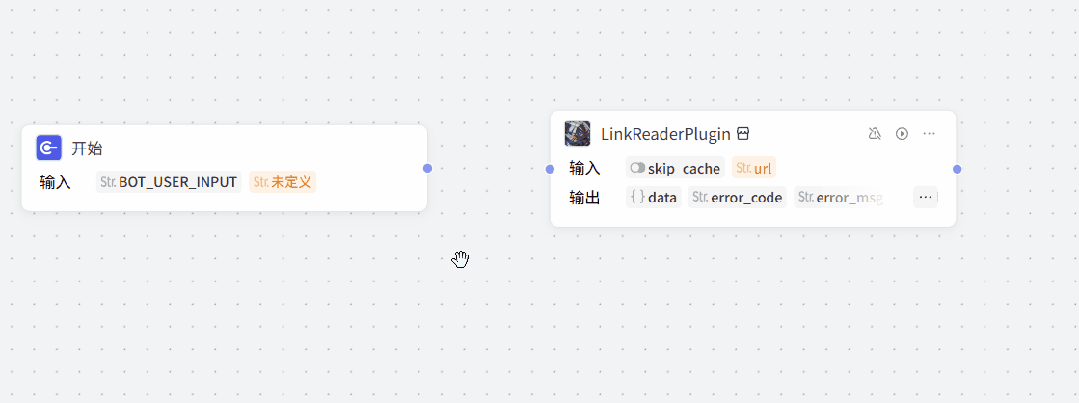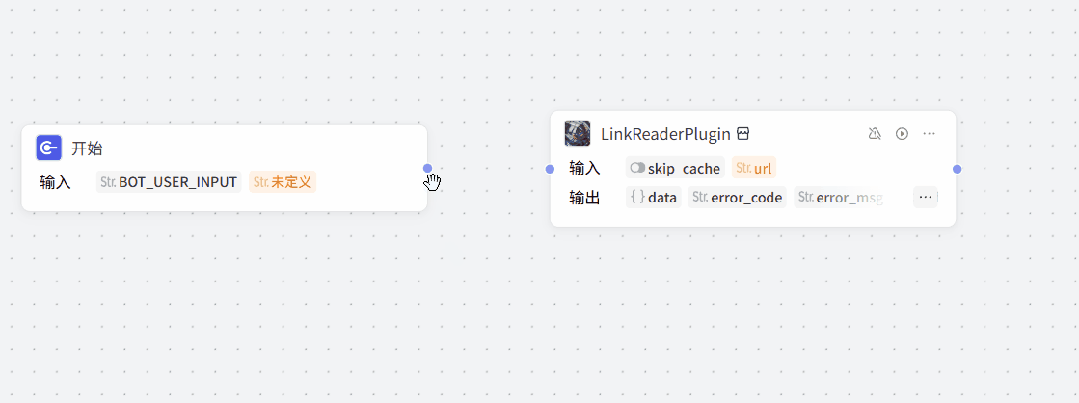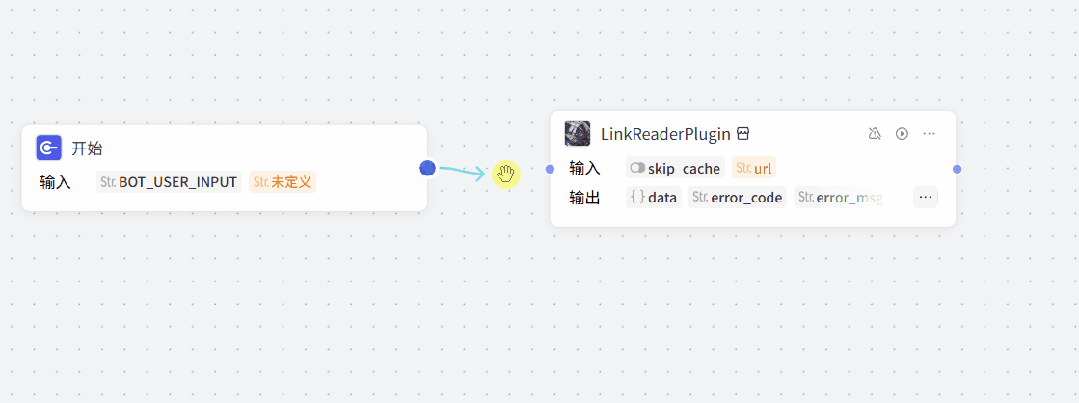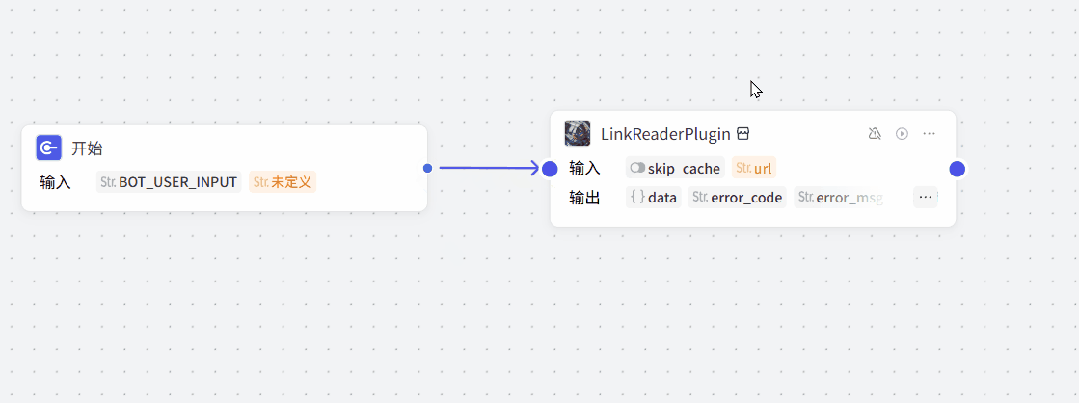
然后给插件改一个名字“文案提取”,方便我们来使用。
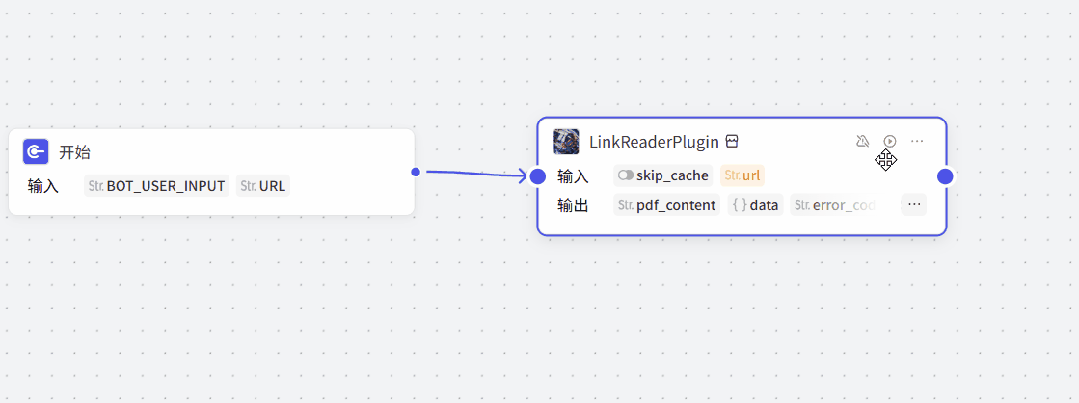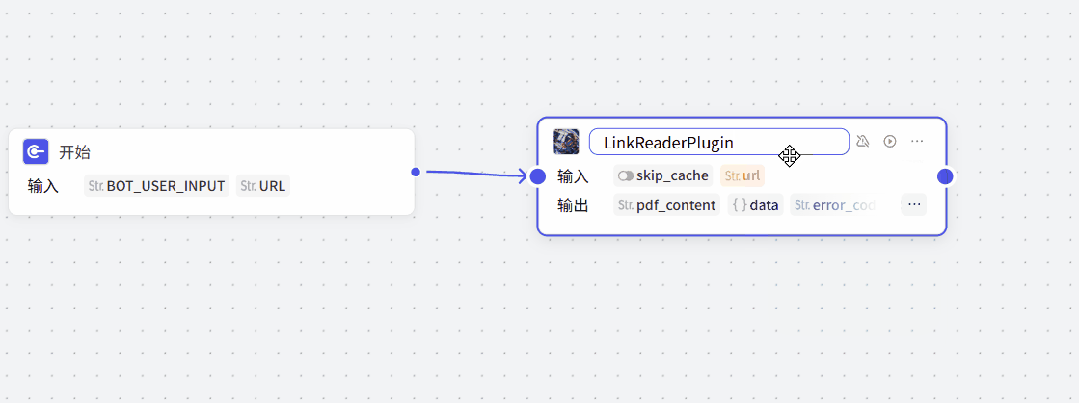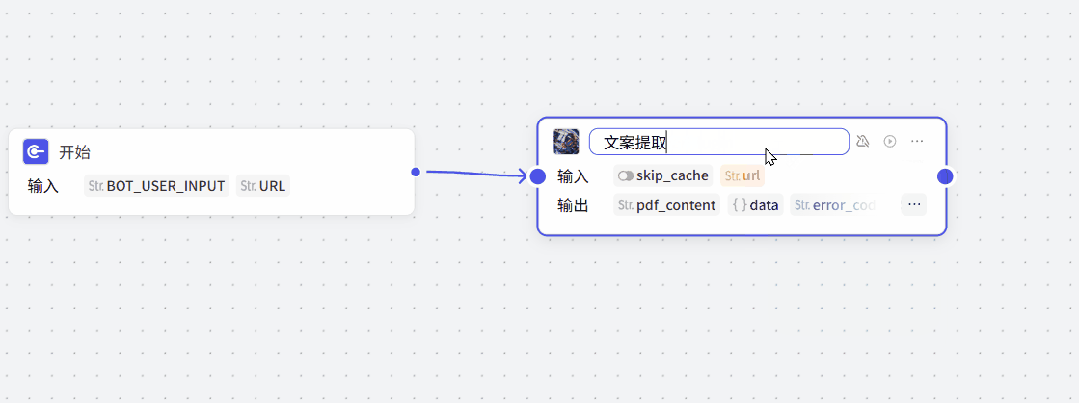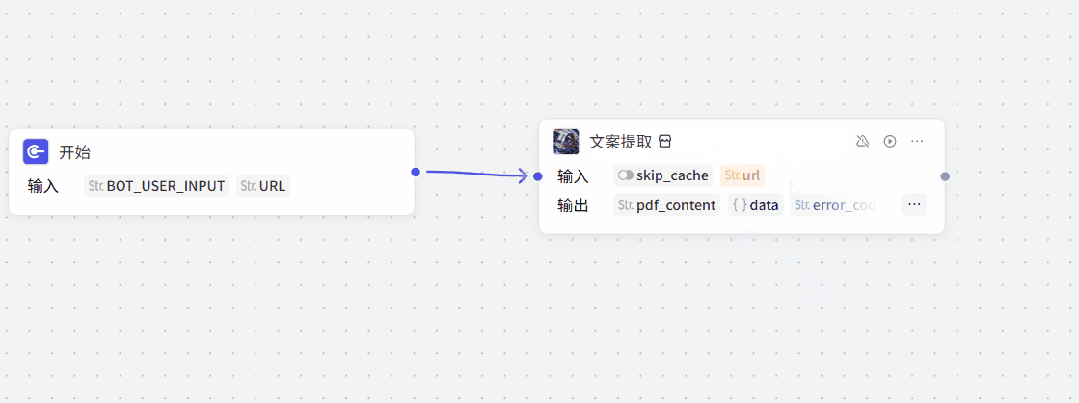
把用书输入的链接给到“文案提取”插件。
点击“文案提取”插件,在url参数中引用“开始”模块的“URL”参数(如下图所示)。
3.文案改写
OK,文案内容有了,现在就需要让AI来帮我改写一下这个文案。
点击“大模型”,添加大模型模块,修改名称为“文案改写”。
连接“文案提取”和“文案改写”模块。

“文案改写”模块中我们需要使用到“文案提取”中的“”和“”参数。
我们在“文案改写”中添加这两个参数,并且设置对应的引用参数。

再往下可以看到有两个写提示词的部分:系统提示词和用户提示词。
系统提示词不填,然后复制下面这段内容到用户提示词中。
Shell
你是一个小红书文案专家,请详细阅读并遵循以下原则,帮我进行小红书笔记二次创作。 #标题创作原则##增加标题吸引力-使用标点:通过标点符号,尤其是叹号,增强语气,创造紧迫或惊喜的感觉!-挑战与悬念:提出引人入胜的问题或情境,激发好奇心。-结合正负刺激:平衡使用正面和负面的刺激,吸引注意力。-紧跟热点:融入当前流行的热梗、话题和实用信息。-明确成果:具体描述产品或方法带来的实际效果。-表情符号:适当使用emoji,增加活力和趣味性。-口语化表达:使用贴近日常交流的语言,增强亲和力。-字数控制:保持标题在20字以内,简洁明了。##标题公式标题需要顺应人类天性,追求便捷与快乐,避免痛苦。-正面吸引:展示产品或方法的惊人效果,强调快速获得的益处。比如:产品或方法+只需1秒(短期)+便可开挂(逆天效果)。-负面警示:指出不采取行动可能带来的遗憾和损失,增加紧迫感。比如:你不xxx+绝对会后悔(天大损失)+(紧迫感) ##标题关键词从下面选择1-2个关键词:我宣布、我不允许、请大数据把我推荐给、真的好用到哭、真的可以改变阶级、真的不输、永远可以相信、吹爆、搞钱必看、狠狠搞钱、一招拯救、正确姿势、正确打开方式、摸鱼暂停、停止摆烂、救命!、啊啊啊啊啊啊啊!、以前的...vs现在的...、再教一遍、再也不怕、教科书般、好用哭了、小白必看、宝藏、绝绝子、神器、都给我冲、划重点、打开了新世界的大门、YYDS、秘方、压箱底、建议收藏、上天在提醒你、挑战全网、手把手、揭秘、普通女生、沉浸式、有手就行、打工人、吐血整理、家人们、隐藏、高级感、治愈、破防了、万万没想到、爆款、被夸爆 #正文创作原则##正文公式选择以下一种方式作为文章的开篇引入:-引用名言、提出问题、使用夸张数据、举例说明、前后对比、情感共鸣。 ##正文要求-字数要求:100-500字之间,不宜过长-风格要求:真诚友好、鼓励建议、幽默轻松;口语化的表达风格,有共情力-多用叹号:增加感染力-格式要求:多分段、多用短句-重点在前:遵循倒金字塔原则,把最重要的事情放在开头说明-逻辑清晰:遵循总分总原则,第一段和结尾段总结,中间段分点说明 接下来,我给你一个主题{{title}},示范文案{{content}},你帮我生成相对应的小红书文案,。输出:-标题数量:每次准备10个标题。-正文创作:撰写与标题相匹配的正文内容,具有强烈的浓人风格
这里需要注意,下图中圈起来的部分,是我们上面设置的参数名称。必须显示是蓝色才对。如果不是蓝色字体可能是参数名填写错误。

现在这个工作流就可以帮我帮写对应的文案,并帮我起10个爆款标题了。
我们试运行一下来看下效果 ,随便找了一个小红书的文案。

点击右上角“试运行”,把小红书的链接放到“URL”参数中,点击下方按钮开始试运行。
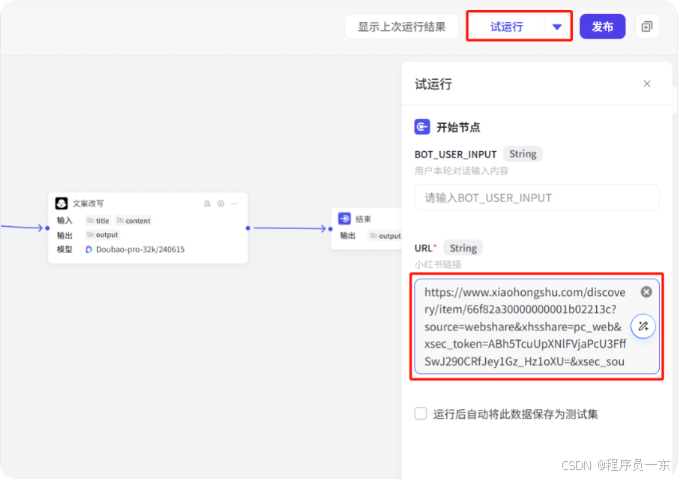
在工作流运行的时候可以点击模块右上方的查看“展开结果”来查看模块运行的结果。

运行完毕,我们可以看到成功提取到了原文案(黄色部分),并且成功改写了10个爆款标题和文案。
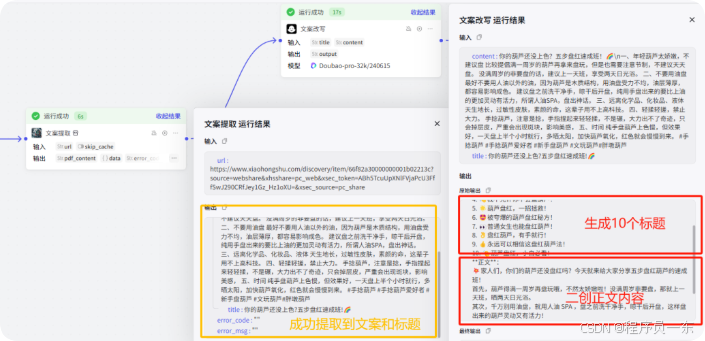
OK,今天的内容先到这里。
下篇继续来完成这个工作流,用AI来解决文案的配图问题。
这份完整版的AI智能体整合包已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 1125
1125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









