



目录
当茶艺师遇上 Coze:用这个工作流混剪视频,播放量暴涨 500% 的秘密藏不住了!
1. 前言
2. Coze工作流设计思路
2.1 整体架构规划
2.2 完整的工作流程
3. Coze工作流具体实现
3.1 开始节点:
3.2 文案创作子工作流:
3.4 文本处理节点:
3.5 文案转语音:
3.6 字幕音频对齐:
3.7 创建剪映草稿
3.8 结束节点:
3.9 剪映小助手下载预览文件
3.10代码
3.11 复盘智能体工作流流程
4. 资料领取
5. 结语
当茶艺师遇上 Coze:用这个工作流混剪视频,播放量暴涨 500% 的秘密藏不住了!
1. 前言
在短视频盛行的当下,茶艺视频以其独特的东方美学和治愈特质脱颖而出。不论是行云流水的冲泡手法,还是袅袅升腾的茶雾,每一帧画面都完美诠释了茶道的深厚底蕴。
别急!今天我们就以 Coze 工具为核心,从情感表达出发,规划完整工作流架构。素材阶段,挖掘能传递治愈感的画面;剪辑时赋予片段情感意义,借助 Coze 智能功能高效处理。视觉上,依情感基调选滤镜、设计转场与字幕;音频搭配上,用音乐、音效营造沉浸氛围。接下来,就跟着这份教程,开启一场指尖上的 “茶韵创作之旅” 吧!
效果展示:

2. Coze工作流设计思路
2.1 整体架构规划
我们设计的工作流主要包含五个核心环节:素材的准备,大模型生成文案,对文案进行拆分,基于拆分的文案进行配音,最后将素材、文案和配音通过剪映小助手工具创建剪映草稿。
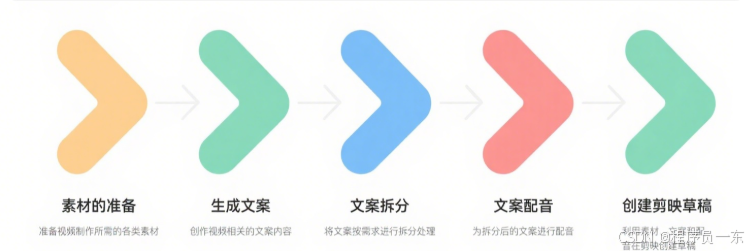
2.2 完整的工作流程

3. Coze工作流具体实现
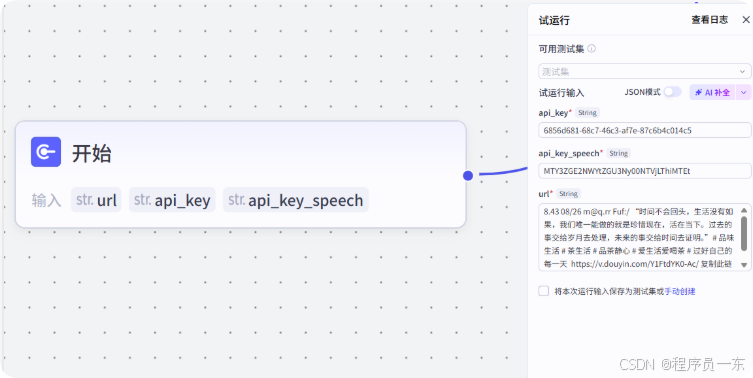
3.1 开始节点:
作为工作流的起始点,其主要作用是接收用户输入的抖音视频链接。我们设置一个名为 “share\_url” 的输入变量,数据类型为文本,且设置为必填项,以确保工作流启动时能获取到有效的抖音链接。
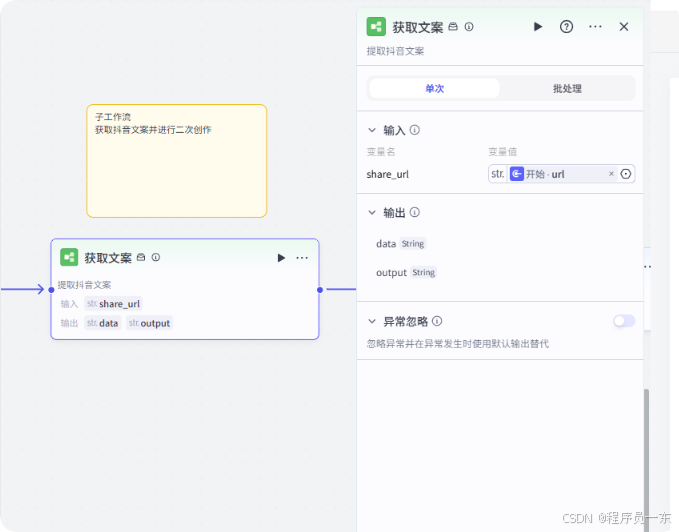
3.2 文案创作子工作流:
该节点利用另一个工作进行文案的创作,这里我们用到了之前讲的“[抖音文案提取 + 二次创作](https://mpbeta.youkuaiyun.com/mp_blog/creation/editor/148401868 "抖音文案提取 + 二次创作")”工作流。
3.4 文本处理节点:
该节点负责将获得的文案按照指定的分隔符进行拆分。
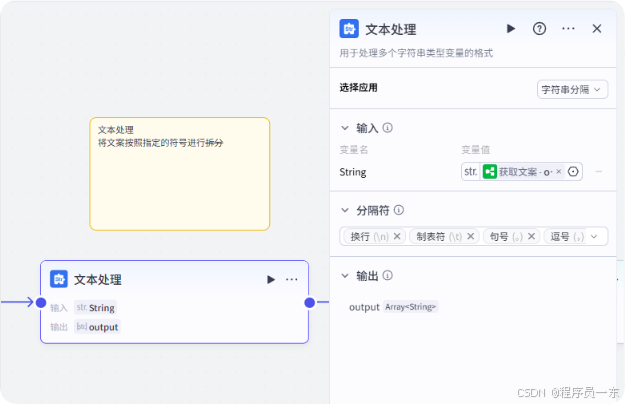
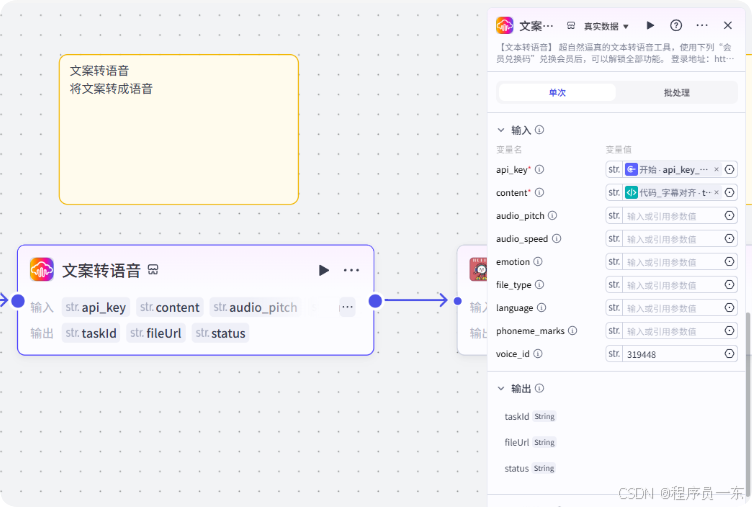
3.5 文案转语音:
这里调用了DubbingX语音合成插件,将文案转成音频配音。
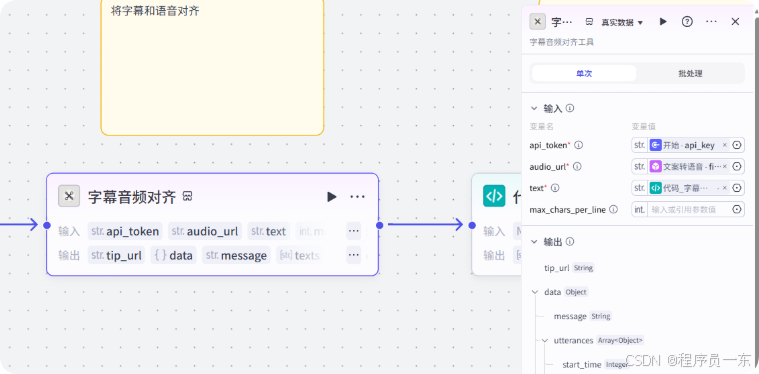
3.6 字幕音频对齐:
这里利用字幕音频对齐插件,将拆分的文案和生成配音进行时间线对齐。
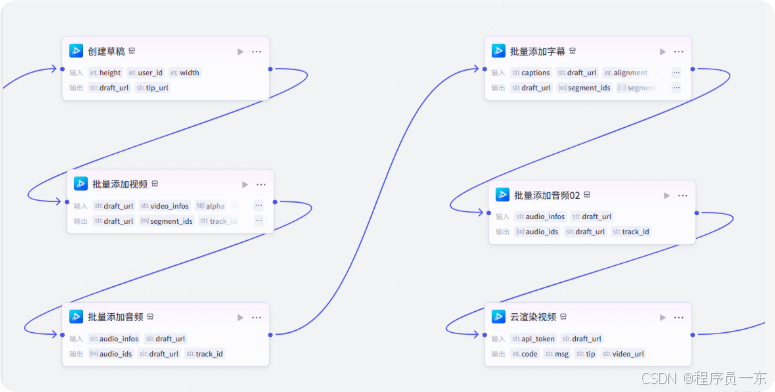
3.7 创建剪映草稿
这里调用剪映小助手工具箱创建草稿,并将视频、文案、语音按照时间线加入到草稿中。
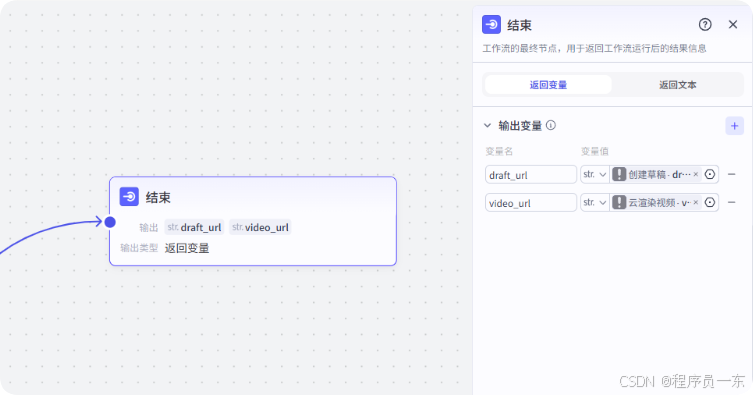
3.8 结束节点:
工作流的最终节点,用于返回草稿的链接。
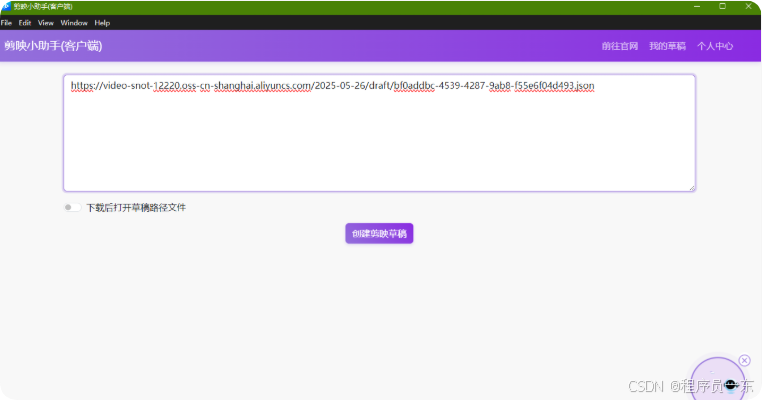
3.9 剪映小助手下载预览文件
复制draft_url链接,通过剪映小助手下载素材文件,最后打开剪映即可发布。
3.10 代码
1.字幕对齐
async def main(args: Args) -> Output:
params = args.params
texts = params['input']
# 移除数组中可能存在的空字符串元素
texts = [t for t in texts if t]
# 将数组转换为以换行符分割的字符串
text_list = '\n'.join(texts)
# 构建输出对象
ret: Output = {
'textList': text_list
}
return ret
2.选取视频片段
import math
import random
async def main(args: Args) -> Output:
params = args.params
clip_duration = 3 # 每个视频片段固定3秒
# 计算需要的片段数量(向上取整确保覆盖完整时长)
total_duration = math.ceil(params['duration'])
num_clips_needed = math.ceil(total_duration / clip_duration)
# 准备好的多个视频素材链接列表
video_materials = [
# 这里是准备好的视频,把视频地址放在此处
# 在此添加更多视频素材链接...
]
# 首先打乱视频素材顺序
shuffled_materials = video_materials.copy()
random.shuffle(shuffled_materials)
# 按打乱后的顺序选择视频片段,循环使用
video_urls = [
shuffled_materials[i % len(shuffled_materials)]
for i in range(num_clips_needed)
]
return {"video_urls": video_urls}
3.数据重组
import json
async def main(args: Args) -> Output:
params = args.params
bgm = params['bgm']
texts = params['texts']
# 视频
video_start = 0
video_end = 0
videos = []
for item in params['video_urls']:
video_end = video_start + 3*1000000
videos.append({
"video_url": item,
"duration": 3*1000000,
"start": video_start,
"end": video_end,
"width":576,
"height":1024,
"transition": "叠化",
"transition_duration": 1000000
})
if video_end >video_start:
video_start = video_end
# 背景音乐
audioBgm = [{
"audio_url": bgm,
"start": 0,
"end": video_end
}]
#配音、字幕
start = 0
end = 0
captions = []
audios = []
audios.append({
"audio_url": params['audioUrl'],
"duration": params['duration']*1000000,
"start": 0,
"end": params['duration']*1000000
})
timelines = params['timelines']
for idx,item in enumerate(timelines):
start = item['start']
end = item['end']
text = texts[idx]
captions.append({
'text': text,
'start': start,
'end': end,
"in_animation":"渐显","out_animation":"渐隐"
})
# 构建输出对象
ret = {
"captions": json.dumps(captions),
"audios": json.dumps(audios),
"videos": json.dumps(videos),
"audioBgm": json.dumps(audioBgm)
}
return ret
3.11 复盘智能体工作流流程

4. 资料领取
**在使用大模型时若感觉体验不佳,很可能是提示词撰写方式有待优化。为此,我们整理了丰富的提示词模板与 Coze系列操作教程,涉及的代码和提示词、完整工作流程已同步至 Coze 空间,感兴趣的朋友可以私信微信详细了解~**

5. 结语
当最后一帧画面定格在茶汤泛起的涟漪中,你会发现:用 Coze 创作茶艺视频的过程,早已超越了技术本身 —— 那些被精心裁剪的茶叶舒展镜头、随茶香晕染的水墨转场、与注水声共振的古琴旋律,都是你向世界传递的治愈信号。
或许生活仍在步履匆匆,但每当你打开 Coze 的素材库,指尖划过那些记录着温杯、摇香的片段,便能重新触摸到茶席前的宁静时刻。这正是茶艺视频的魔力:它让我们在剪辑台前完成的不仅是作品,更是一次与自己和解的疗愈仪式。
现在,带着这份工作流里的东方美学密码与 Coze 的便捷工具,去创作属于你的「茶语时光」吧。记得在发布时附上 #治愈系茶艺# 的标签 —— 当更多人在你的视频里看见茶叶浮沉间的禅意,听见茶具相碰的清响,这场由你发起的治愈之旅,便有了更温暖的续篇。
本文转自 https://blog.youkuaiyun.com/fanlf/article/details/148402557?spm=1001.2014.3001.5501,如有侵权,请联系删除。
这份完整版的AI智能体整合包已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 909
909

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









