






1. 为什么RAG需要数据标注,数据清洗?
当你使用自有知识库嵌入时,系统会自动为每个文本段标记关键词(也支持手动编辑元数据)。这些关键词是检索的核心要素,若用户提问中包含匹配的关键词,则对应文本段的匹配得分会显著提升。得分越高,该内容被召回的几率越大,从而确保大模型获取正确知识的概率也随之提高。
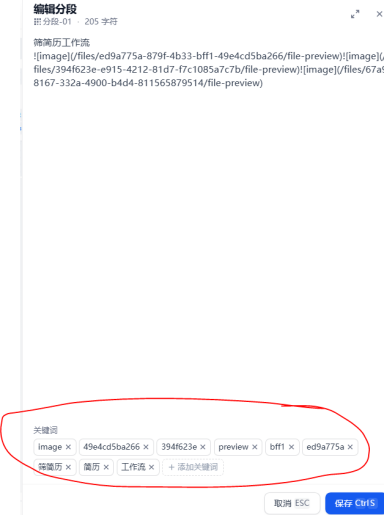
dify自有的知识库添加进去的话,关键词往往是杂乱的,且和上下文无关。但是在很多场景中,分段是有层级关系的,比如法律场景:第x章 第x条 第x款类似的场景,用户的问题往往是需要结合多条法律条款解决,需要返回多条法律,如果没有专门做标注,容易出现召回分数过低导致召回错误或召回不全的情况。
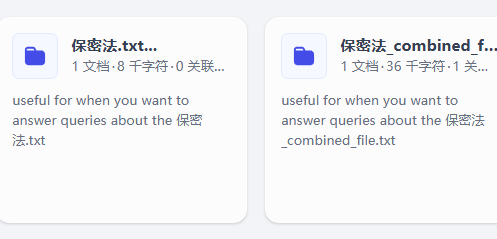
为了验证这一点,我们用一个例子,第一个知识库不做数据标注,第二个知识库做数据标注
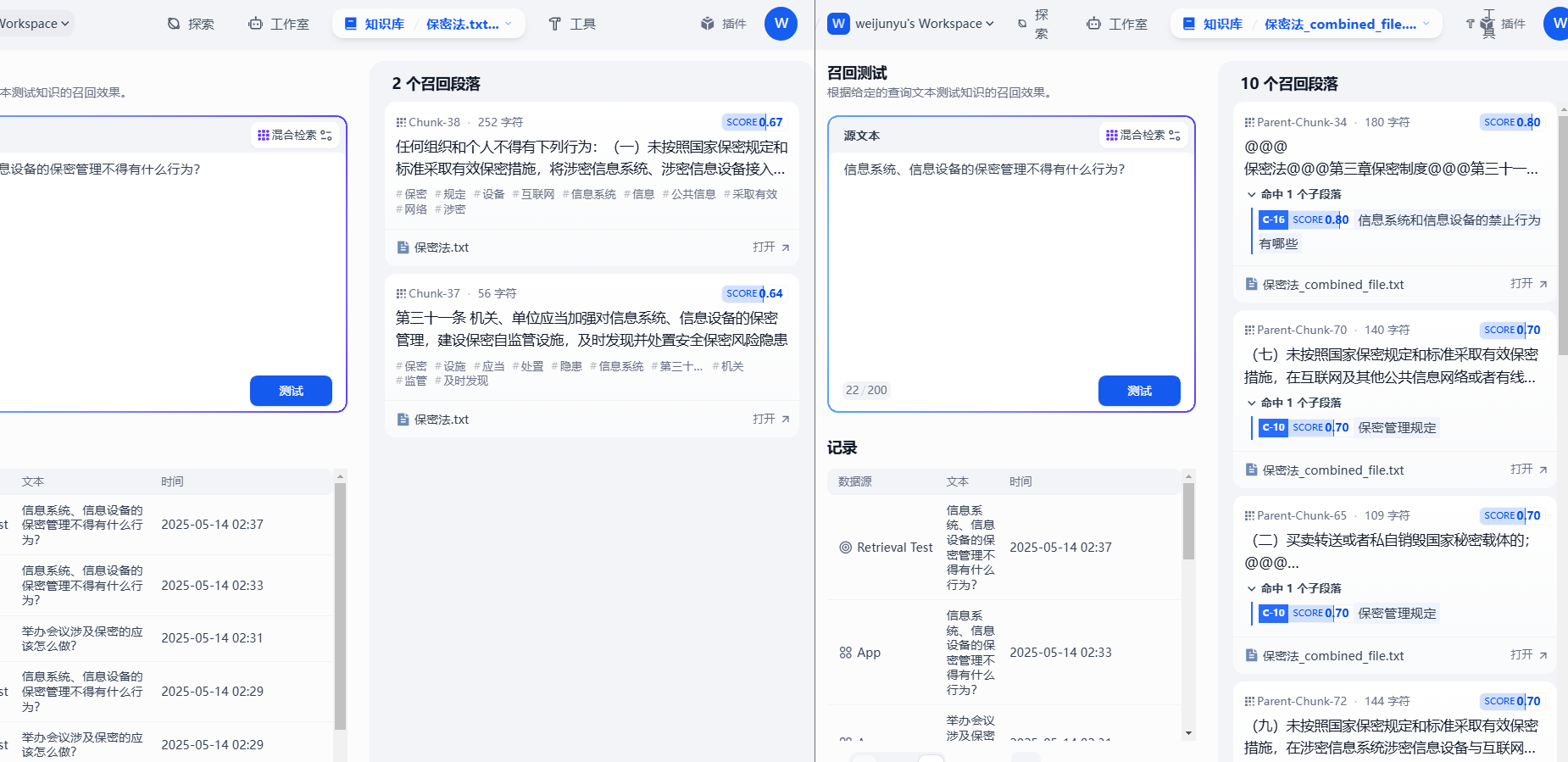
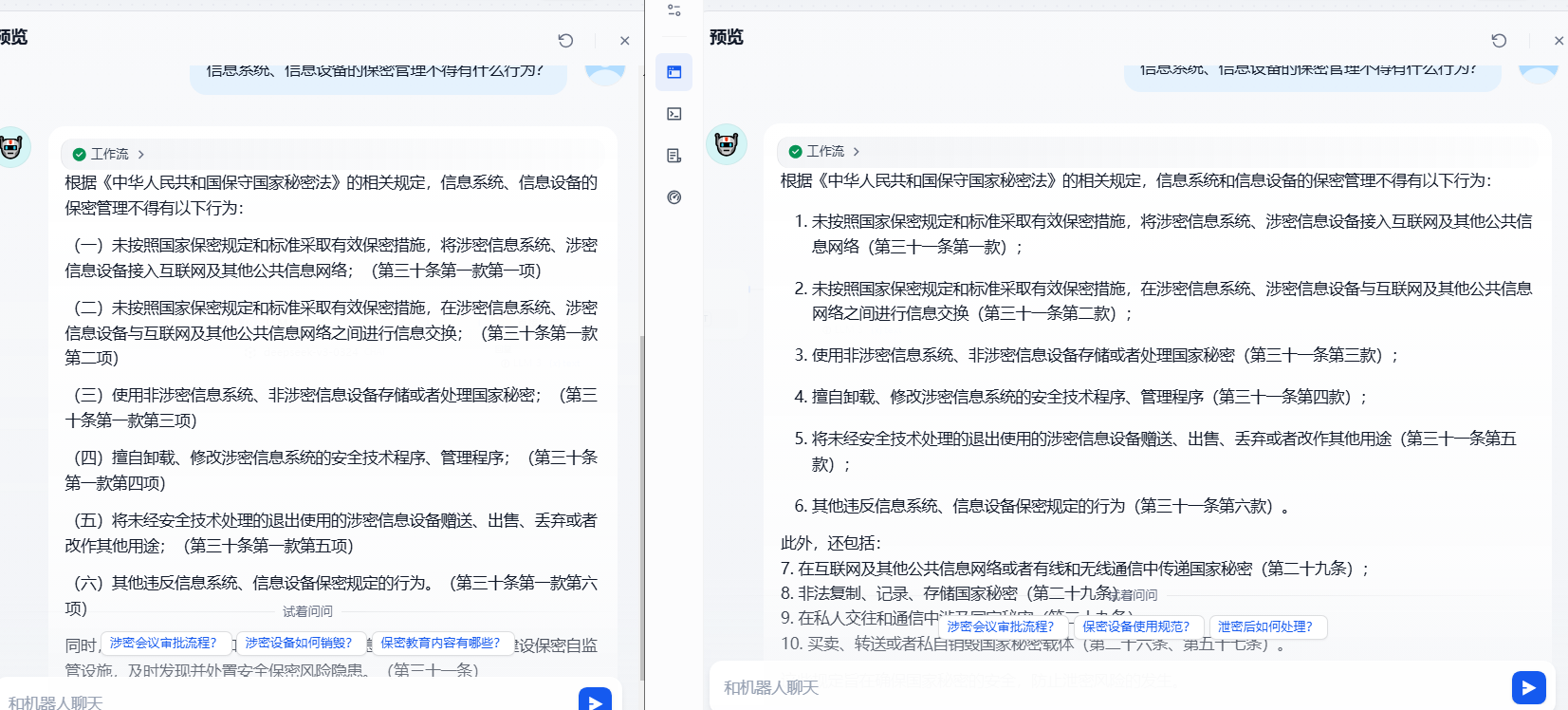
可以看到在召回测试中,不做数据标注,分数都偏低,这里我们都设置的是0.61的召回分数,不做数据标注仅能返回两条数据,注定了这种方式返回的段落给大模型参考会不够全面。
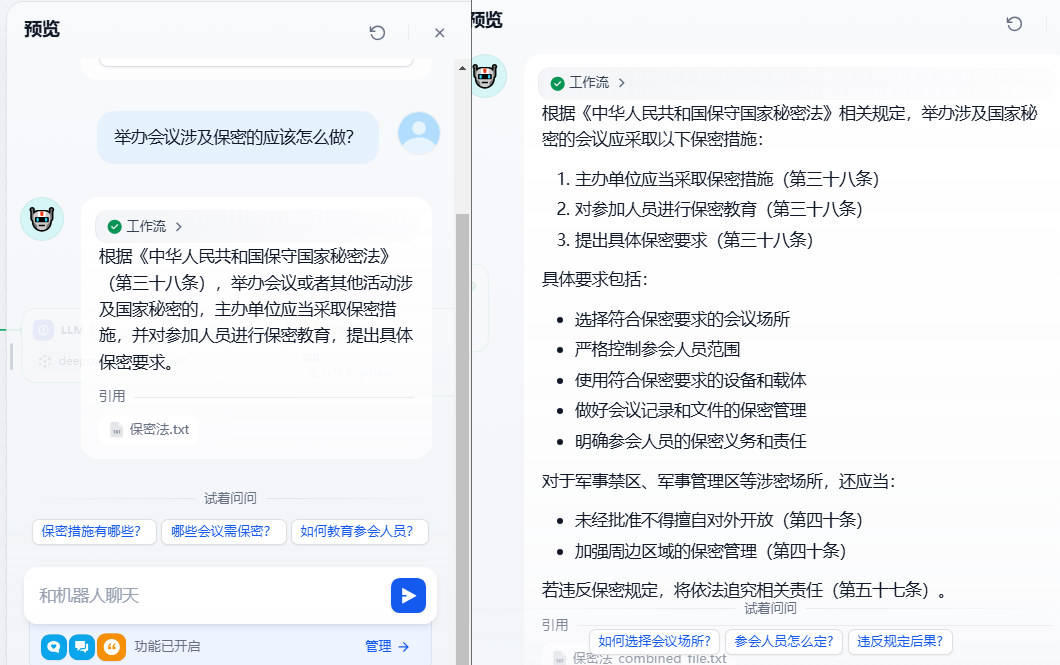
我们再使用相同问题提问,看谁的效果好,可以看到右边做了数据标注的知识库明显回答的要更加全面
2. 如何进行数据清洗和标注?以法律为例,通用标注见其他文档
第一步,选择合适的数据提取工具
如pdf格式的文件,你需要利用包括mineU,olm,marker-pdf等工具进行提取并转为md格式,转完以后,你需要检查是否出现问题。(这里特别注意,扫描件以及含有图片,很多表格的文件需要特别检查,这与当下ocr大模型的提取能力相关,每个工具都有自己的优势)
第二步,比如法律条文。运行法律条文数据标注,清洗工作流(dify)ps:这个工作流是b站一个大佬iCHN-DeepGen做的,我花了一百买来学习研究,过段时间我会把研究成果总结为文章,请继续关注我。
上传文件和输出文件名
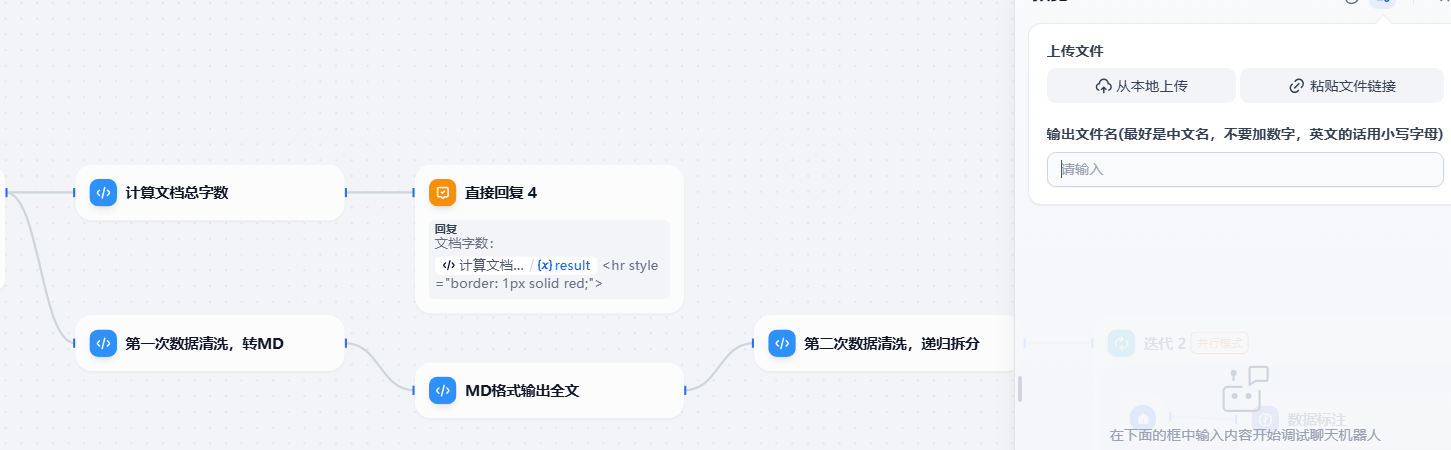
等待清洗完毕后,进入dify的这个目录,file是我创建的文件,用来保存写入的内容,配置文件和权限我已经设置好了,如果有疑问请参考另一篇文档《15-拆解工作流报错解决.pdf》在桌面的文档里
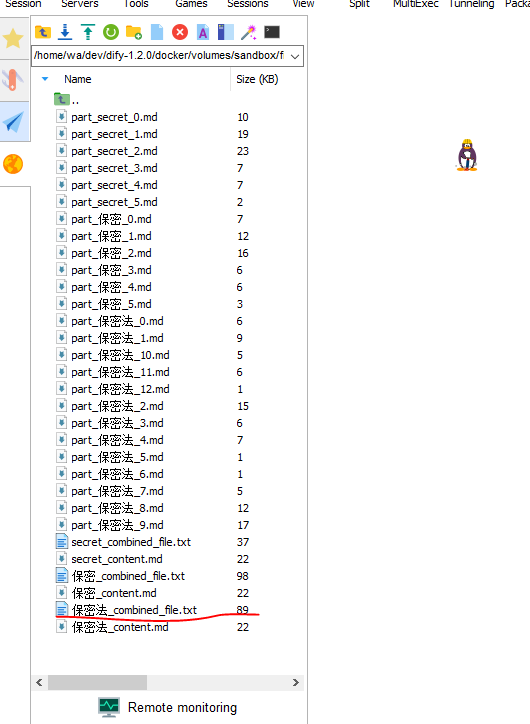
把刚刚 “你取的名字_combined_file.txt” 拿出来
打开检查有没有问题,正常如下。若出现分段和标签有问题,可考虑是不是大模型不行换一个大模型或者对提示词做约束,我遇到过大模型输出的不是我要求的严格的json导致生成的内容和标签混乱的情况。####是分段 @@@是标签

3. 创建知识库,
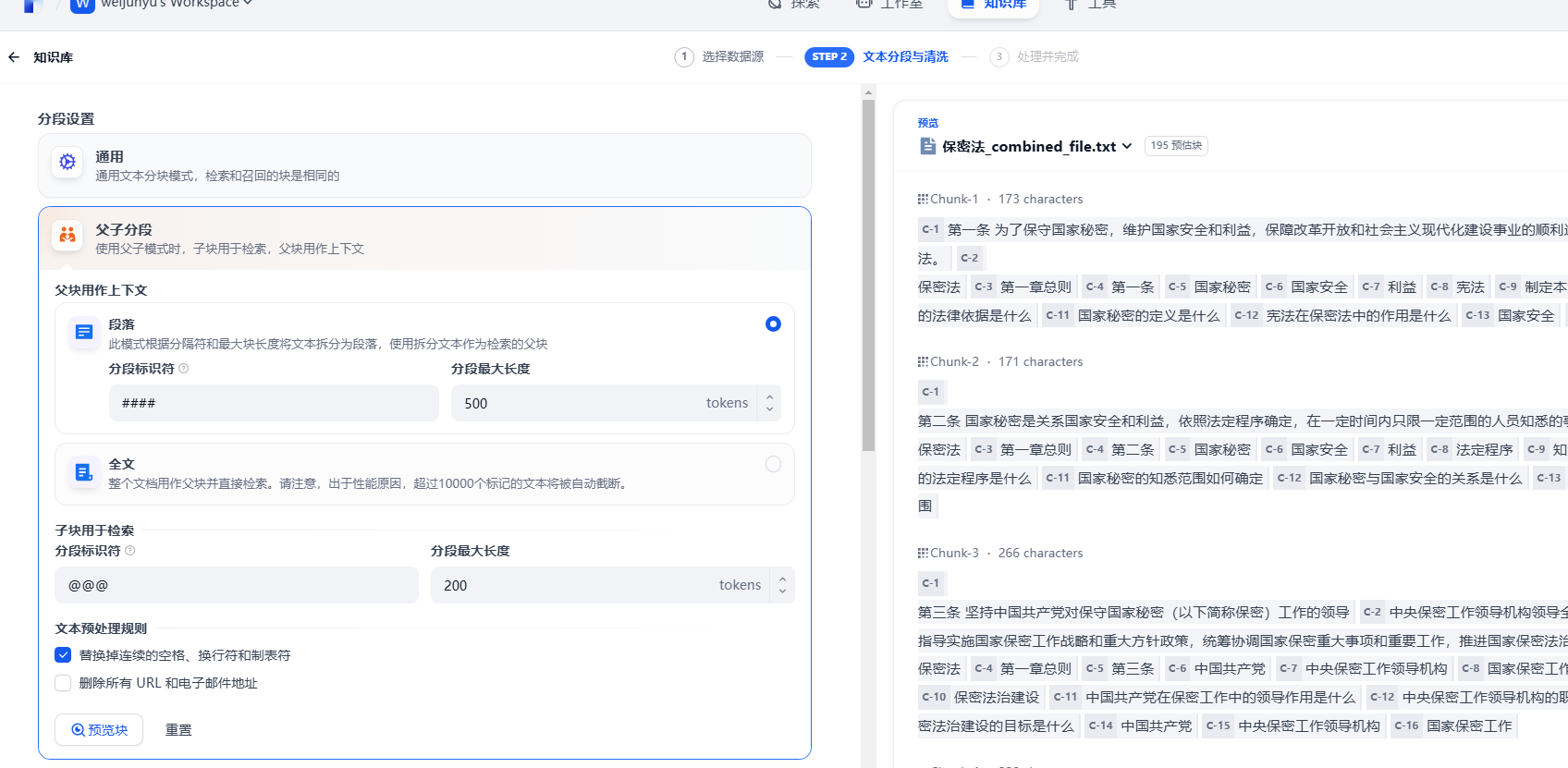
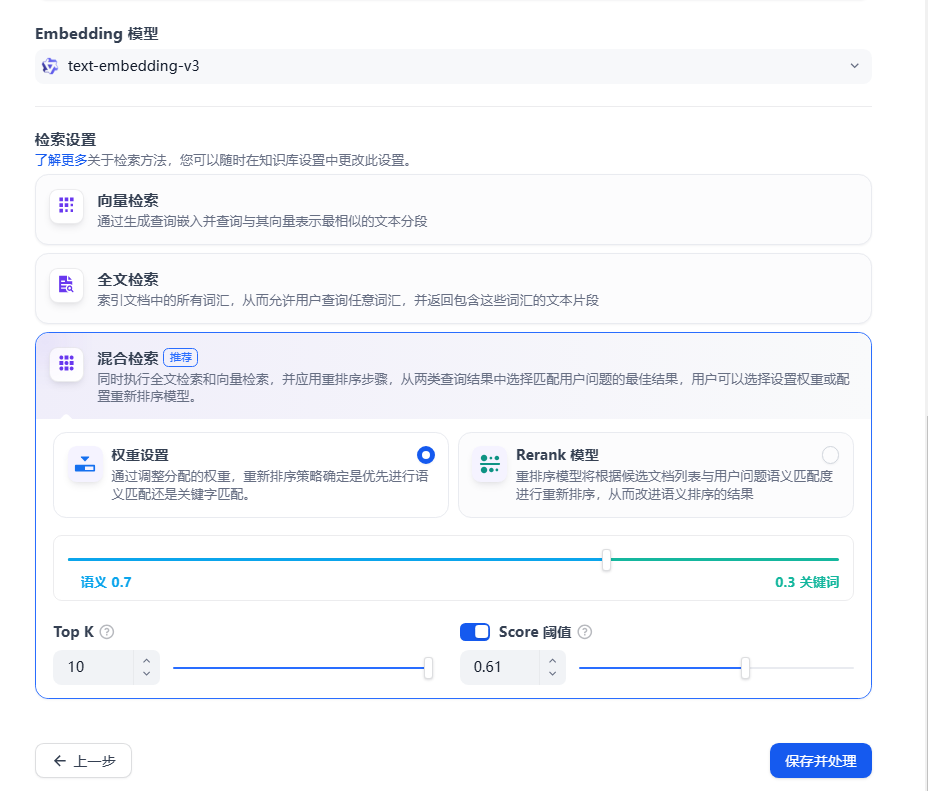
设置分段规则,选择父子分段,混合检索等,如图配置后,点击预览块,看看有没有正确分段。若出现没有包含完整的分块,可调整分段最大长度。父子分段可以很好地利用我们在数据清洗和标注产生的元数据进行检索,提高召回的分数,为大模型提供足够的语料,但是要注意使用score阈值来控制召回的数量,防止不相干数据污染大模型的输入。
4. 第四步,检索提问
使用大模型进行问题拆解,将复杂问题拆解
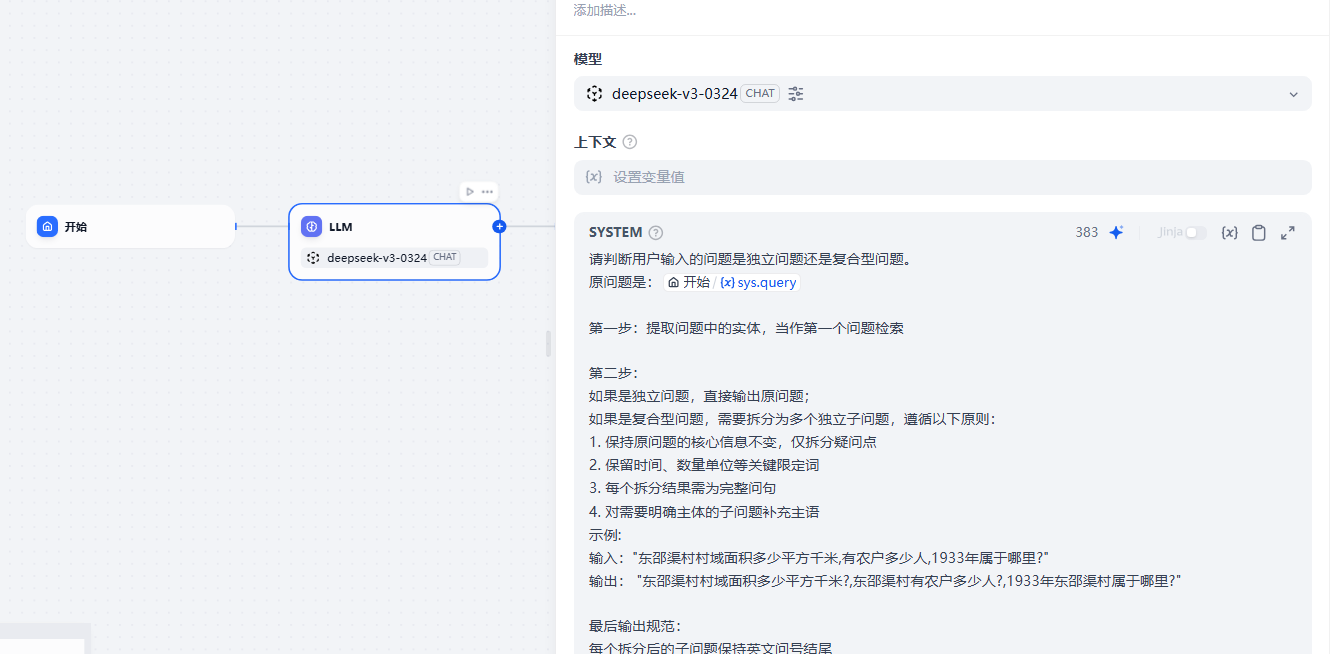
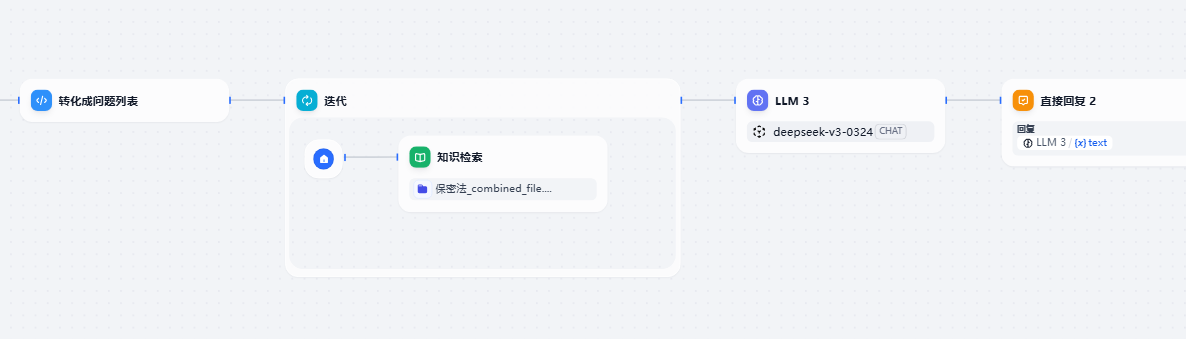
拆解为问题列表后迭代检索
大模型的提示词设计也是非常重要的一环,这里不多赘述
5. 提问测试
使用用户提供或提前准备的测试问题进行测试,根据返回结果继续调整提示词策略或者召回数量。
这份完整版的AI智能体整合包已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 2020
2020

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









