




注意力机制:Self-Attention
注意力机制的计算公式非常简洁:
Attention(Q,K,V)=softmax(QKTdk)V,\text{Attention}(Q,K,V)=\text{softmax}(\frac{QK^T}{\sqrt{d_k}})V,Attention(Q,K,V)=softmax(dkQKT)V,
其中Q,K,VQ,K,VQ,K,V之间的计算就是注意力机制的核心,也就是常说的:Query、Key和Value,从数学角度出发,这几个就是由向量所组成的矩阵,然后矩阵之间进行运算、缩放得到最终的输出结果,但纸上得来终觉浅,模型的知识还是需要实操才能得到更深入的理解,所以这里从注意力机制整个流程中计算维度的角度出发解释其计算流程,也更方便程序的编写。
现在假设输入的是一个特征矩阵XXX(或者可以理解为是一个句子,里面是词向量),其维度为
X:[N,input_features],X:[N,input\_features],X:[N,input_features],
input_featuresinput\_featuresinput_features即为每个特征向量的维度,再经过三个不加偏置的全连接层的计算,假设其对应矩阵为WQ,WK,WVW_Q,W_K,W_VWQ,WK,WV,其维度为
WQ:[input_features,head_dim],W_Q:[input\_features,head\_dim],WQ:[input_features,head_dim],
WK:[input_features,head_dim],W_K:[input\_features,head\_dim],WK:[input_features,head_dim],
WV:[input_features,head_dim_v],W_V:[input\_features,head\_dim\_v],WV:[input_features,head_dim_v],
head_dimhead\_dimhead_dim则理解为计算注意力权重过程中中间层的维度,然后将其与所输入的特征矩阵XXX进行矩阵乘法,得到前面所提到的Q,K,VQ,K,VQ,K,V矩阵:
Q:[N,head_dim],Q:[N,head\_dim],Q:[N,head_dim],
K:[N,head_dim],K:[N,head\_dim],K:[N,head_dim],
V:[N,head_dim_v].V:[N,head\_dim\_v].V:[N,head_dim_v].
得到所需的矩阵之后,代入注意力机制的计算公式进行计算,第一步就是Q×KTQ\times K^TQ×KT,由于这两个矩阵中的第一维就是表示需要分配注意力权重的维度:某个单词或者某个通道,所以这里矩阵KKK转置后的计算就是表示计算着两个矩阵中对应向量的内积,其维度变换为:
Q×KT:[N,head_dim]×[head_dim,N]=[N,N],Q\times K^T:[N,head\_dim]\times [head\_dim,N]=[N,N],Q×KT:[N,head_dim]×[head_dim,N]=[N,N],
后面的除以dk\sqrt{d_k}dk,也就是除以head_dimhead\_dimhead_dim,是为了重新将特征向量中的元素缩放到方差为1的分布中,并不会改变矩阵的维度;而softmaxsoftmaxsoftmax操作只是将每行映射为和为1的权重(后续用于分配不同的注意力权重给不同位置的ValueValueValue向量),同样不会改变矩阵的维度,即:
softmax(QKTdk):[N,N].\text{softmax}(\frac{QK^T}{\sqrt{d_k}}):[N,N].softmax(dkQKT):[N,N].
来到最后一步,按照上面的步骤可以轻易得出:
softmax(QKTdk)V:[N,N]×[N,head_dim_v]=[N,head_dim_v].\begin{split}
\text{softmax}(\frac{QK^T}{\sqrt{d_k}})V&:[N,N]\times [N,head\_dim\_v]\\&=[N,head\_dim\_v].
\end{split}softmax(dkQKT)V:[N,N]×[N,head_dim_v]=[N,head_dim_v].
到这里,整个注意力机制的计算过程就已经完成了,核心思想就是计算向量之间的内积并作为权重分配给不同特征向量,最终实现注意力机制的“注意力”功能。

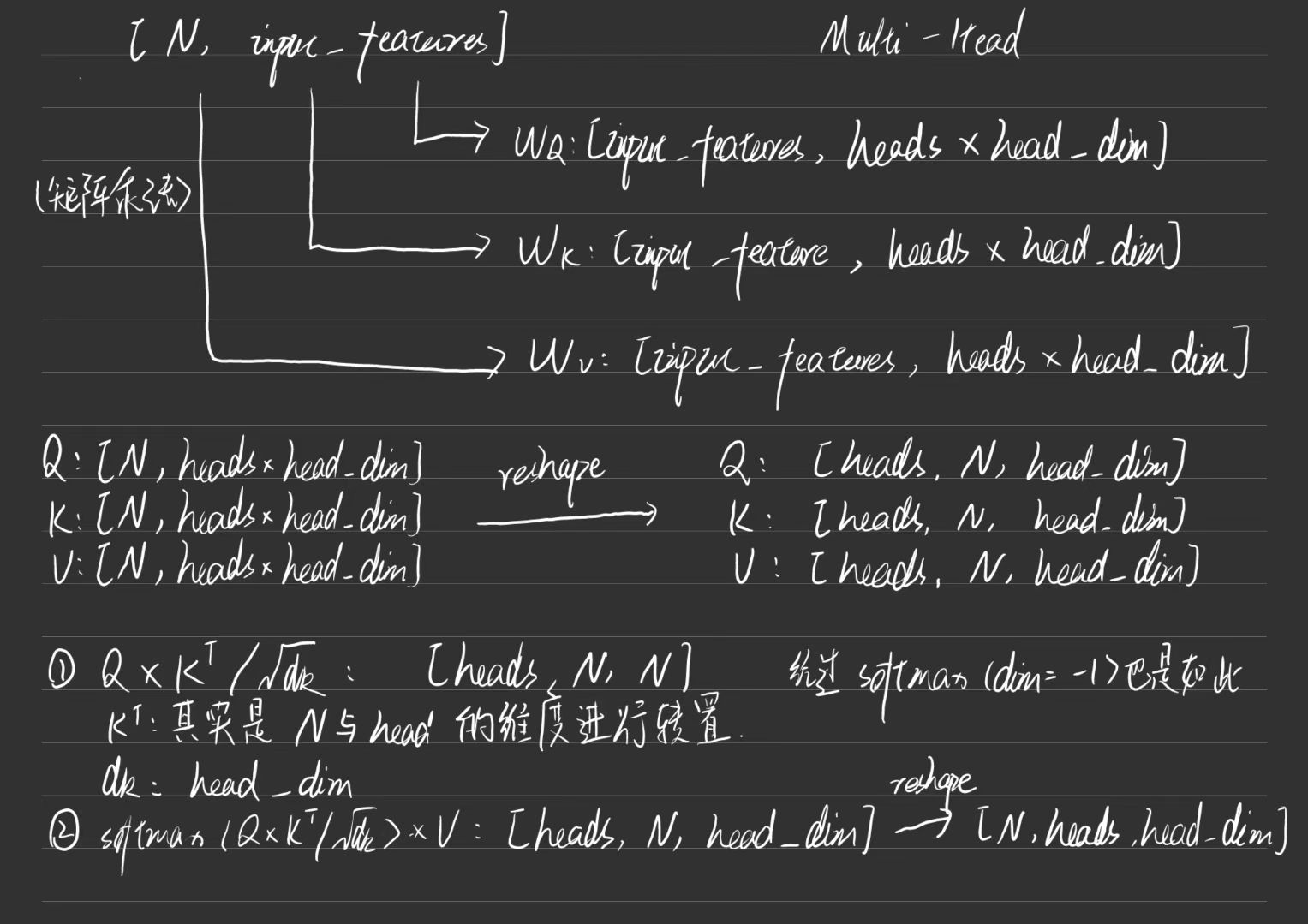
多头注意力机制:Multi-Head Attention
多头注意力机制就是对多个注意力机制的输出输出结果进行拼接:
MultiHead(Q,K,V)=Concat(head1,...,headh)WOwhere headi=Attention(QWiQ,KWiK,VWiV)\begin{aligned}\mathrm{MultiHead}(Q,K,V)& =\mathrm{Concat}(\mathrm{head}_{1},...,\mathrm{head}_{\mathrm{h}})W^{O} \\\mathrm{where~head_{i}}& =\text{Attention}(QW_{i}^{Q},KW_{i}^{K},VW_{i}^{V}) \end{aligned}MultiHead(Q,K,V)where headi=Concat(head1,...,headh)WO=Attention(QWiQ,KWiK,VWiV)
简单来说可以直接写多个Attention再使用拼接代码实现,但是也可以直接通过矩阵的拆分来实现,下面简单介绍下多头注意力机制中矩阵维度的变化。
同样的,假设输入的是一个特征矩阵XXX,其维度为
X:[N,input_features],X:[N,input\_features],X:[N,input_features],
headsheadsheads即为多头注意力机制中的头数,同样经过三个不加偏置的全连接层,其对应矩阵为WQ,WK,WVW_Q,W_K,W_VWQ,WK,WV,其维度为
WQ:[input_features,heads×head_dim],W_Q:[input\_features,heads\times head\_dim],WQ:[input_features,heads×head_dim],
WK:[input_features,heads×head_dim],W_K:[input\_features,heads\times head\_dim],WK:[input_features,heads×head_dim],
WV:[input_features,heads×head_dim_v],W_V:[input\_features,heads\times head\_dim\_v],WV:[input_features,heads×head_dim_v],
其余符号含义和计算过程与上述类似,同样得到前面所提到的Q,K,VQ,K,VQ,K,V矩阵:
Q:[N,heads×head_dim],Q:[N,heads\times head\_dim],Q:[N,heads×head_dim],
K:[N,heads×head_dim],K:[N,heads\times head\_dim],K:[N,heads×head_dim],
V:[N,heads×head_dim_v].V:[N,heads\times head\_dim\_v].V:[N,heads×head_dim_v].
在进行进一步计算之前,需要对这些矩阵进行reshape一下:
Q:[heads,N,head_dim],Q:[heads,N,head\_dim],Q:[heads,N,head_dim],
K:[heads,N,head_dim],K:[heads,N,head\_dim],K:[heads,N,head_dim],
V:[heads,N,head_dim_v],V:[heads,N,head\_dim\_v],V:[heads,N,head_dim_v],
现在计算Q×KTQ\times K^TQ×KT,这里的对KKK进行转置其实就是对NNN和head_dimhead\_dimhead_dim的维度进行交换,这里包括后面的矩阵运算也都是在后面两个维度上进行的,可以得到:
Q×KT:[heads,N,head_dim]×[heads,head_dim,N]=[heads,N,N],\begin{split}
Q\times K^T&:[heads,N,head\_dim]\times [heads,head\_dim,N] \\&=[heads,N,N],
\end{split}Q×KT:[heads,N,head_dim]×[heads,head_dim,N]=[heads,N,N],
同样的,经过缩放和softmax\text{softmax}softmax的计算后不会改变矩阵的维度,那么有:
softmax(QKTdk)V:[heads,N,N]×[heads,N,head_dim_v]=[heads,N,head_dim_v].\begin{split}
\text{softmax}(\frac{QK^T}{\sqrt{d_k}})V&:[heads,N,N]\times [heads,N,head\_dim\_v]\\&=[heads,N,head\_dim\_v].
\end{split}softmax(dkQKT)V:[heads,N,N]×[heads,N,head_dim_v]=[heads,N,head_dim_v].
主要的计算部分到这里已经结束了,需要进一步使用多头注意力机制的结果就可以在这个基础上进行reshape等操作。


















 1140
1140






 到【灌水乐园】发言
到【灌水乐园】发言









