




 这篇博客介绍了如何使用Python的pandas库对DataFrame进行分组统计,将统计结果转换为list形式。首先展示了分组聚合的方式,通过`groupby()`和`agg()`函数实现。接着,重点讲解了字典操作,利用`setdefault()`、`defaultdict()`以及try-except结构创建字典,将数据按分组键存储为列表。最后,给出了四种不同的字典构建方法,并展示了将字典转换回DataFrame的方法。
这篇博客介绍了如何使用Python的pandas库对DataFrame进行分组统计,将统计结果转换为list形式。首先展示了分组聚合的方式,通过`groupby()`和`agg()`函数实现。接着,重点讲解了字典操作,利用`setdefault()`、`defaultdict()`以及try-except结构创建字典,将数据按分组键存储为列表。最后,给出了四种不同的字典构建方法,并展示了将字典转换回DataFrame的方法。
对字典追加元素以及分组聚合
描述:有两列,按照其中的一列分组,对另一列统计,转为list形式
#自定义数据
x1=np.random.randint(10,size=(20,1))
x2=np.random.randint(10,size=(20,1))
y=np.random.random(size=(20,1))
a=pd.DataFrame(np.c_[x1,x2,y],columns=['did_x','didx_2','dis'])
a.did_x=a.did_x.astype(int)
a.didx_2=a.didx_2.astype(int)
a
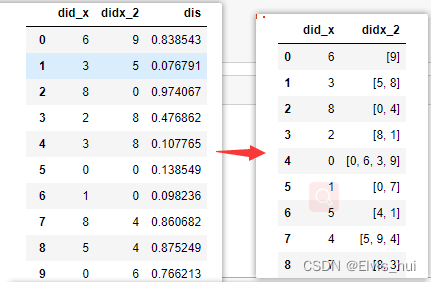
第一种:分组聚合方式
#分组聚合方式
a.groupby(['did_x']).agg({'didx_2':list}).reset_index()
第二种:形成字典方式
往往字典在实际中能解决很多问题,而且很灵活,我们重点掌握字典的一些用法
-------------------------------------------------------------------------------
setdefault接受一个键和一个默认值,并返回关联值,如果没有当前值,则返回默认值。
在本例中,我们将获得一个空的或已填充的列表,然后将当前值追加到该列表中。
#第一种方式
dic={}
for x in range(len(a)):
dic.setdefault(a.iloc[x,0],[]).append(a.iloc[x,1])
输出:

#字典转为Series然后转为DF 就能得到结果
pd.Series(dic).to_frame().reset_index().rename(columns={'index':'did_x',0:'didx_2'})
-------------------------------------------------------------------------------
#第二种方式
#先将dataframe两列数据转为list
data=a[['did_x','didx_2']].values.tolist()
from collections import defaultdict
ss=defaultdict(list)#defaultdict(list, {})
for i,j in data:
ss[i].append(j)
输出:

-------------------------------------------------------------------------------
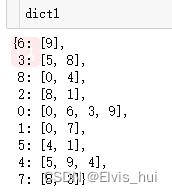
# 第三种方式
dict1={}
for i ,j in data:
try:
dict1[i].append(j)
except KeyError:
dict1[i]=[j]
## 第四种方式 not in
dict2={}
for x in data:
key=x[0]
if key not in dict2:
dict2[key]=[]
dict2[key].append(x[1])



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











