 深度解析:嵌入式技术的Embedding应用与优化
深度解析:嵌入式技术的Embedding应用与优化





Embedding
一种将离散变量转为连续变量的方式。字面理解-嵌入语义空间到向量空间的映射
两种应用
- 1.NLP word embedding
- 2.categories data entity embedding
Embedding 有三个主要目的
- 在embedding 空间中查找最近邻,这可以很好的用于根据用户的兴趣来进行推荐
- 作为监督学习任务的输入
- 用于可视化不同离散变量之间的关系
Onehot
缺点:
1.对于多类型的类别变量,变换后向量维度太大,过于稀疏
2…映射之间完全独立,并不能表示出不同类别之间的关系
【Onehot无法考虑语义间的相互关系,但是Embedding的训练需要借助Onehot】
表示类别变量的理想解决方案,则是我们是否可以通过较少的维度表示出每个类别,并且还可以以一定的表现出不同类别变量之间的关系,这也是Embedding出现的目的.
keras.layers.Embedding(input_dim, output_dim, input_length)
参数
- input_dim:这是文本数据中词汇的取值可能数。例如,如果您的数据是整数编码为0-9之间的值,那么词汇的大小就是10个单词;
- output_dim:这是嵌入单词的向量空间的大小。它为每个单词定义了这个层的输出向量的大小。例如,它可能是32或100甚至更大,可以视为具体问题的超参数;
- input_length:这是输入序列的长度,就像您为Keras模型的任何输入层所定义的一样,也就是一次输入带有的词汇个数。例如,如果您的所有输入文档都由1000个字组成,那么input_length就是1000。
Go straight to code!
from tensorflow.keras.layers import Dense,Flatten, Embedding,Input
from tensorflow.keras.models import Model
from tensorflow.keras.preprocessing import sequence,text
from tensorflow.keras.metrics import binary_accuracy
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.preprocessing.text import one_hot
import numpy as np
# define documents
docs = ['Well done!',
'Good work',
'Great effort',
'nice work',
'Excellent!',
'Weak',
'Poor effort!',
'not good',
'poor work',
'Could have done better.']
# define class labels
labels = np.array([1, 1, 1, 1, 1, 0, 0, 0, 0, 0])
max_length=4
size=50
encode_docs=[one_hot(d,size) for d in docs]

paded_docs=pad_sequences(encode_docs,maxlen=max_length,padding='post')
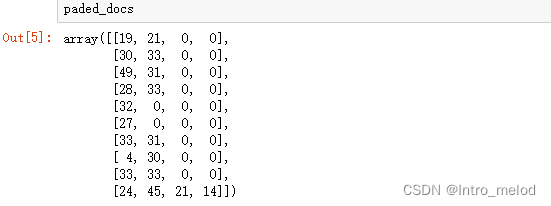
input=Input(shape=(4,))
x=Embedding(size,8,input_length=max_length)(input)
x=Flatten()(x)
x=Dense(1,activation='sigmoid')(x)
model=Model(inputs=input,outputs=x)
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['acc'])
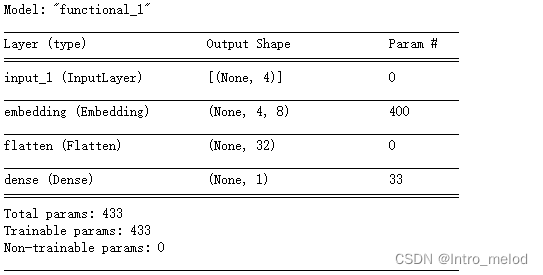
model.summary()
model.fit(paded_docs,labels,epochs=100,verbose=0)
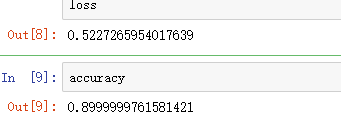
loss,accuracy=model.evaluate(paded_docs,labels,verbose=0)
预测
test=one_hot('hei',50)
padded_test=pad_sequences([test],maxlen=max_length,padding='post')
padded_test
#array([[23, 0, 0, 0]])
model.predict(padded_test)
#array([[0.53474814]], dtype=float32)



















 5772
5772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











