






往期文章: 来源 Logan投资 公众号
金融人必看!机器学习预测的「非主流标注法」,让策略赢在起跑线!
在时序择时预测上的策略通常分有两种,因子型和规则型的策略。
规则型择时因为需要对每条规则来编写代码,每个因子的开平仓规则都不一样,这样就导致了在进行策略更新迭代和管理上会很麻烦,也很难去判断这个因子有没有效,也很难对比(因为每个的规则都不一样),所以我在因子层面很少使用规则型策略,但大的层面还可以用一用。
本文讨论的择时因子的检验,则是基于因子型择时策略的因子。因子型可以方便的进行因子挖掘和策略迭代,因子都统一为0上多0下空,同时可以构建统一的单因子检验和筛选、多因子模型训练与预测的统一框架。整个框架都较为系统,好管理。

为什么多因子选股能更容易成功?
是因为相比于择时,多因子选股能在几千个股票上选择,能更快的达到概率收敛,因为如果你的选股因子是ok的,那么在选择的几百个股票中有十几二十个股票上是负的超额收益也不影响大方向。
相比来看,择时是在单标的上运行的,为了让择时因子的策略和检验也尽可能的达到概率收敛,能做的做法就是单个择时因子在多个指数上进行检验,而在策略构建上也要采用多个择时因子合成信号的方法。
这就是择时因子的检验之一,多指数测试,检验择时因子的普适性
在多个指数的基础上,每个指数计算该因子的以下指标和检验
-
正态分布检验:KDE图,w检验
-
因子序列平稳性检验:ADF检验
-
分组收益差:因子排序的收益分层能力,将因子排序后分组,计算每组的平均未来收益差,衡量因子的排序解释力,同时也考虑的因子值大小与未来收益大小的关系。
-
滚动IC:考虑因子预测能力的稳定性,使用滑动窗口计算因子值与未来收益的滚动相关系数,观察其在不同时间段是否保持有效性。
-
卡方检验:检验因子值与收益正负之间的独立性
-
互信息量检验(Mutual Info):检验因子与未来收益的非线性信息依赖性,捕捉非线性相关关系,适用于复杂分布特征的因子。
-
基于指数的单因子回测
以下演示是基于中证1000指数计算的一个择时因子,计算了8年的数据
(操作时应该也用相同方法对其他指数根据同一逻辑计算的择时因子进行检验)
KDE(Kernel Density Estimation)Plot
是一种用于可视化数据分布的方法,它可以帮助我们检测数据的正态性。在KDE Plot中,数据的密度被估计并绘制成一条平滑的曲线,这有助于我们观察数据的分布形状。
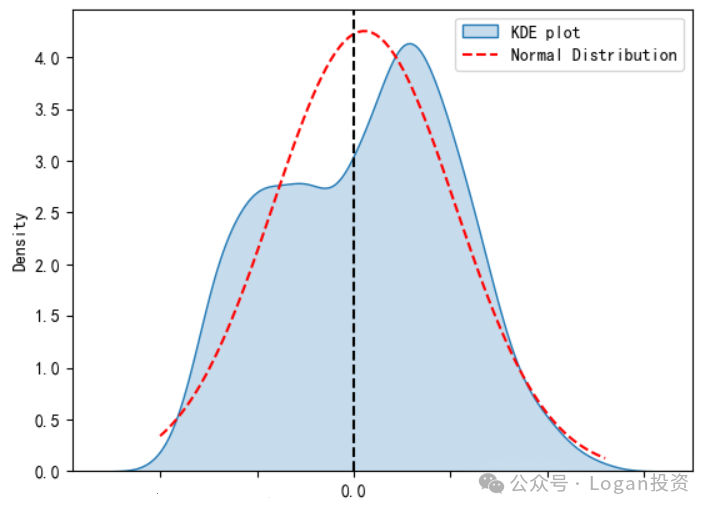
数据来源:Logan投资公众号
通过上图可以看到数据不是很符合正态分布,也做了W(Shapiro-Wilk)检验,结论p值小于0.05,即有大于95%的概率拒绝数据服从正态分布的原假设。所以上面那些检验我也就不做了,有些检验依赖正态分布假设。而有研究解决了非正态金融数据下择时能力检验的问题,这一块在另一篇推文再写。
因子值分组收益差
择时因子值分组收益检验主要是检验因子值与未来收益是否存在单调递增或递减关系。
这里的检验做法和多因子选股相似,多因子选股是根据在b时刻因子值大小对股票进行分组再计算多空收益,而择时因子分组检验则是在a到b这段历史时间上按照因子值大小分组,计算每组所对应的该指数的历史平均未来收益。
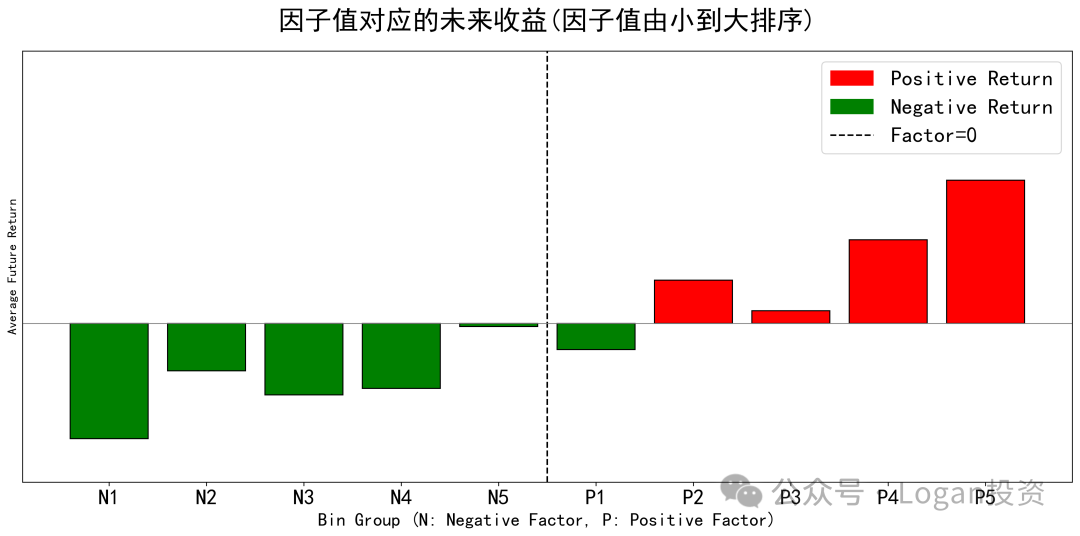
数据来源:Logan投资公众号
可以看到上图中,该因子确实符合递增关系,即该择时因子值越大,对应的未来收益也越大,反之亦然 ,符合逻辑。但也可以发现因子值在0附近时,收益关系不显著,所以在构建策略的时候可以设定阈值,当因子值的绝对值大于X时才进行择时操作(虽然有点规则型的意思,而且这么回测存在未来数据分布泄露的问题)。
IC值/滚动IC(Information Coefficient)
因子选股中的IC值计算是基于截面数据进行计算的,但是在择时中则基于时序进行计算。我计算了这个因子8年的滚动IC值,如下图
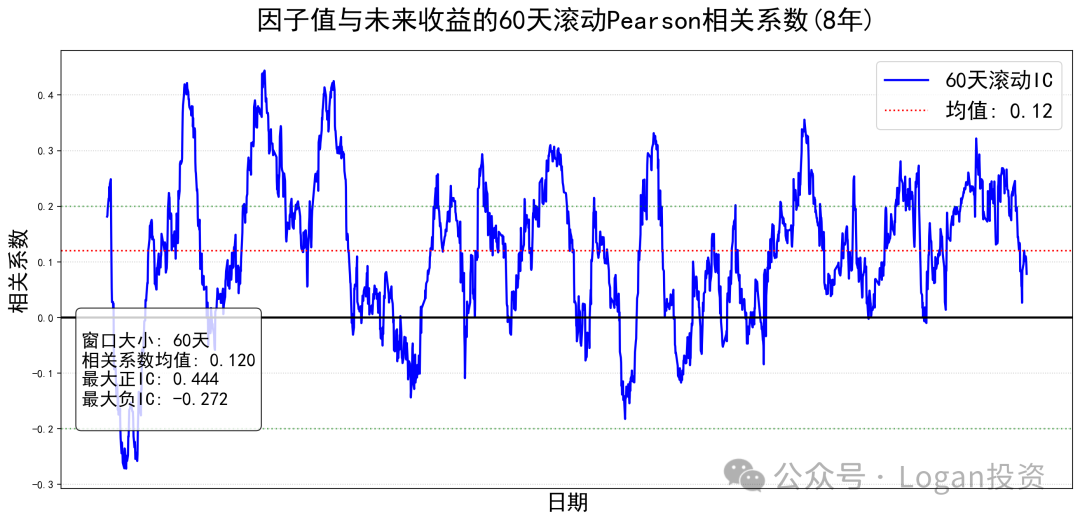
数据来源:Logan投资公众号
可以发现大部分时间这个因子的IC值都大于0,IC胜率高,IC均值的绝对值为0.12,大于0.05。可以说是挺好的择时因子了。
一些小想法:在检验上面,基于截面计算择时因子IC值的方法,我觉得可以根据多个指数来操作。在a时刻,n个指数根据同一逻辑计算出因子值,同时也对应n个指数对应的未来收益,对这两列数据计算IC值我觉得也是可行的,只是指数数量没有股票这么多,可以考虑行业指数。其实跟因子选股一样,只是在择时检验中,标的不是股而是指数。(这里我就不去算其他指数了)

















 703
703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









