




1、数据如下(文件名:ceshi1.csv):
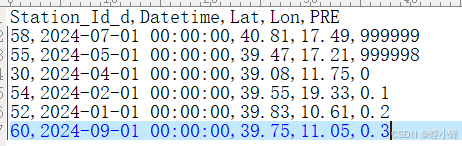
2、首先,设置999999和999998为缺测值,并读取数据
# 设置缺测值
miss_data = [999999, 999998]
# 读取数据
data0 = pd.read_csv('E:\\ceshi1.csv', header = 0, sep=',', na_values=miss_data)
3、这一步我也不懂为啥要这么做。。。等等我再学习下。。。。
data1 = np.array(data0)
4、删除降水数据含有缺测值的行
# 创建pandas DataFrame
df = pd.DataFrame(data1)
# 要删除第5列分钟降水中含有缺失值的行(从第0行开始算),第5列的索引是4
column_index = 4
# 使用pandas的dropna方法,传入axis=0表示按行进行操作,subset参数指定处理特定列
df_cleaned = df.dropna(axis=0, subset=[column_index])
# 转换回numpy数组
data2 = df_cleaned.values
这段代码会删除第降水数据列中包含缺失值的行。以上结束。
补充:
如果你想要删除任何包含缺失值的行,可以使用how='any'参数:
df_cleaned = df.dropna(axis=0, how='any')

















 1445
1445

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









