



Qwen
Qwen-72B模型
| Hyperparameter | Value |
|---|---|
| n_layers | 80 |
| n_heads | 64 |
| d_model | 8192 |
| vocab_size | 151851 |
| sequence_length | 32768 |
Qwen-VL
LLM Backbone:Qwen-7B Base 模型
Visual Encoder:ViT架构使用OpenCLIP预训练好的ViT-bigG模型(经过2B的训练数据训出来的ViT模型)。
Adapter随机初始化的单层cross-attention,使用一组可学习的query向量将vit的图像特征作为kv,将视觉特征压缩到固定的256长度。
+二维绝对位置编码(三角位置编码)
输入数据:图片<img></img>,bounding box用“左上-右下”表示,统一归一化道(0,1000),描述bounding box的文本用<ref></ref>表示。
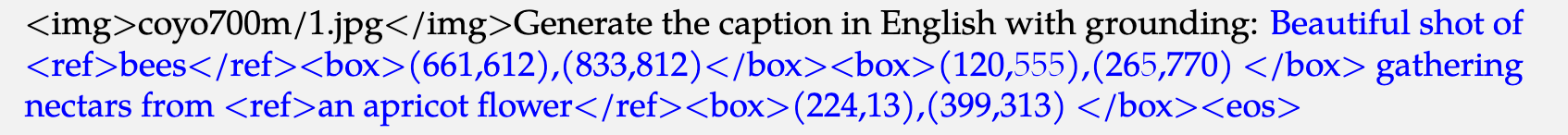
训练:
第一阶段:单任务大规模预训练(Pre-training ),主要使用大量网上抓取和内部的图文pair数据做预训练,训练数据有1.4B,英文数据占比77.3%,中文占比22.7%,训练数据的图片统一处理成224*224的尺寸。该阶段LLM模型参数是frozen的,ViT和Cross-Attention层的参数是激活更新的,这个阶段主要通过大规模数据训练模型的vision模态对齐语言模型的能力。
第二阶段:多任务预训练(Multi-task Pre-training),这个阶段使用了更高分辨率、更高质量的数据,同时引入图文混排的数据。该阶段是个多任务的预训练阶段,包括7个任务,其中有6个Vision任务(包括Captioning ,VQA,grounding等)和1个文本生成任务,这个阶段模型是全参数激活的。该阶段之所以引入文本生成任务,主要是为了保证模型的通用文本处理能力。该阶段的训练数据,Vision数据的分辨率从224*224提升到448*448,数据做了精选处理,包括多模态数据69M和 文本数据7.8M。第二阶段的数据量比第一阶段少了2个量级。该阶段训练完成后,最终产出了Qwen-VL base模型。
第三阶段: 指令微调(Supervised Fine-tuning),主要提升模型的指令遵循能力和对话能力。在这个阶段作者对数据做了些数据增强,通过人工标注、模型生成和策略拼接等方式构造多模态的多轮会话数据。该阶段指令集数据共收集了350K。
VIT
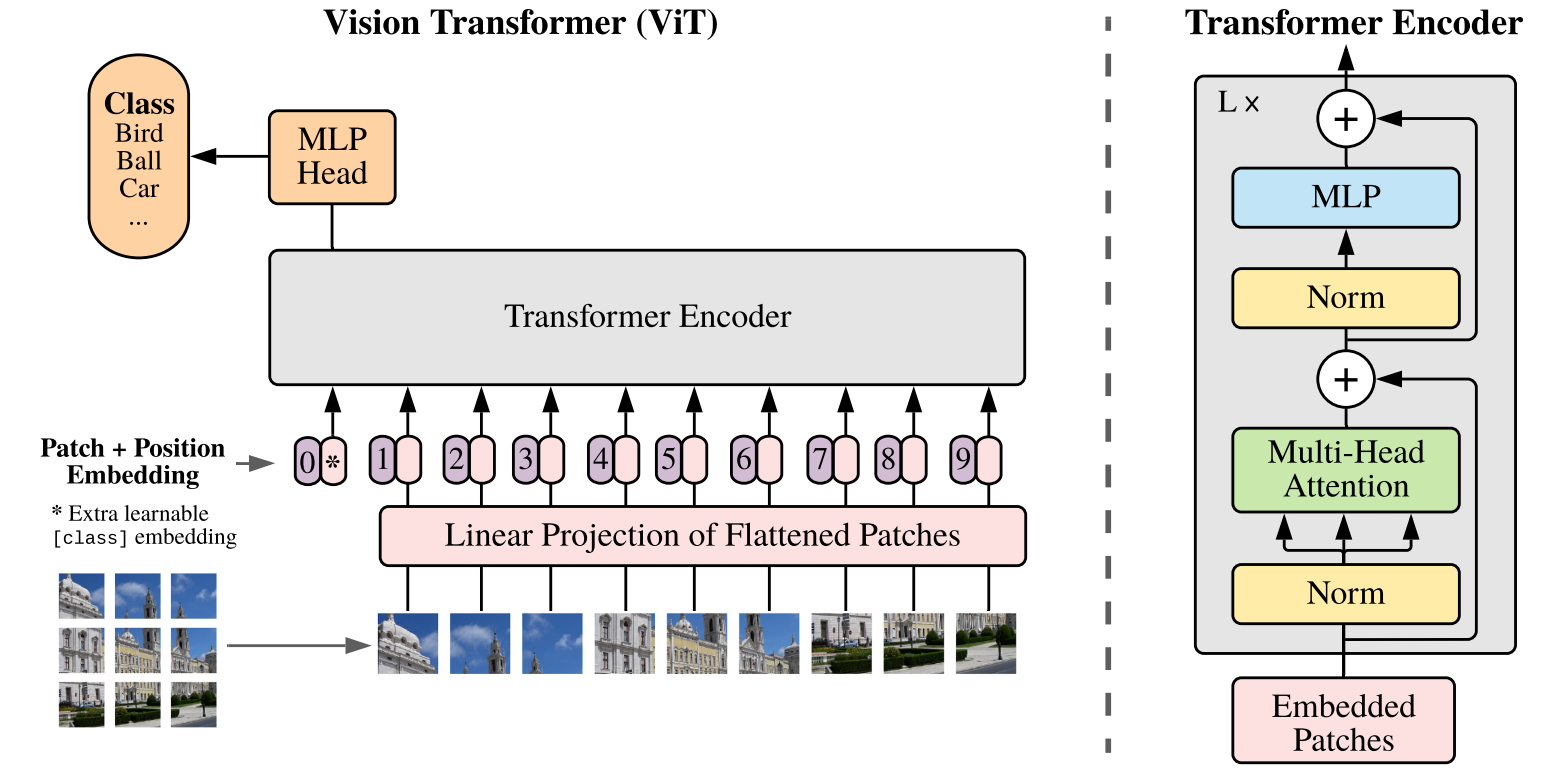
标准的ViT实现输入图片先被调整成长宽比1:1的正方形, 再分割成固定大小的patch块。(分辨率和pathch的size都是固定的)
卷积操作=(输入长度+2*padding-卷积核大小)/步长+1
Patch Embedding:使用卷积核大小为16×16,步长(stride)为16,卷积核个数为768,卷积后再展平,size变化为:[224, 224, 3] -> [14, 14, 768] -> [196, 768]。
+[cls]+使用可学习的绝对位置编码
Image预处理:训练阶段,随机裁剪输入图像并将裁剪后的图像调整为224*224,以一定概率水平翻转,再转化为Tensor格式进行标准化处理。
预测阶段,将输入图像调整为256*256,对调整后的图像进行中心裁剪保留中心区域224*224,再转化为Tensor格式进行标准化处理。
如何想要改变微调图像的分辨率大小,需要对预训练的位置嵌入执行 2D 插值,以扩展到微调尺寸:获取新位置token数目,计算原始patch个数和新位置patch个数,将patch位置嵌入转为2D维度,使用双线性插值,改为新的patch个数,将cls和patch位置嵌入合并。
Qwen2
configuration_qwen2.py
# Default tensor parallel plan for base model `Qwen2`
base_model_tp_plan = {
"layers.*.self_attn.q_proj": "colwise",
"layers.*.self_attn.k_proj": "colwise",
"layers.*.self_attn.v_proj": "colwise",
"layers.*.self_attn.o_proj": "rowwise",
"layers.*.mlp.gate_proj": "colwise",
"layers.*.mlp.up_proj": "colwise",
"layers.*.mlp.down_proj": "rowwise",
}
base_model_pp_plan = {
"embed_tokens": (["input_ids"], ["inputs_embeds"]),
"layers": (["hidden_states", "attention_mask"], ["hidden_states"]),
"norm": (["hidden_states"], ["hidden_states"]),
}
张量并行TP:将模型权重矩阵拆分到多个GPUGPU上,"colwise"按列拆分,"rowwise"按行拆分。
流水线管道并行PP:将模型的不同层分配到不同GPU上,GPU0将input_ids输出为inputs_embeds传给下一个GPU,GPU1输入[“hidden_states”, “attention_mask”]输出[“hidden_states”],以此类推。
modular_qwen2.py
class Qwen2MLP(LlamaMLP):
def __init__(self, config):
super().__init__(config)
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
class LlamaMLP(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.hidden_size = config.hidden_size
self.intermediate_size = config.intermediate_size
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=config.mlp_bias)
self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=config.mlp_bias)
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=config.mlp_bias)
self.act_fn = ACT2FN[config.hidden_act]
def forward(self, x):
down_proj = self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
return down_proj
常规MLP代码 pass
class Qwen2Attention(LlamaAttention):
def __init__(self, config: Qwen2Config, layer_idx: int):
super().__init__(config, layer_idx)
self.q_proj = nn.Linear(config.hidden_size, config.num_attention_heads * self.head_dim, bias=True)
self.k_proj = nn.Linear(config.hidden_size, config.num_key_value_heads * self.head_dim, bias=True)
self.v_proj = nn.Linear(config.hidden_size, config.num_key_value_heads * self.head_dim, bias=True)
self.o_proj = nn.Linear(config.num_attention_heads * self.head_dim, config.hidden_size, bias=False)
self.sliding_window = config.sliding_window if config.layer_types[layer_idx] == "sliding_attention" else None
@deprecate_kwarg("past_key_value", new_name="past_key_values", version="4.58")
def forward(
self,
hidden_states: torch.Tensor,
position_embeddings: tuple[torch.Tensor, torch.Tensor],
attention_mask: Optional[torch.Tensor],
past_key_values: Optional[Cache] = None,
cache_position: Optional[torch.LongTensor] = None,
**kwargs: Unpack[FlashAttentionKwargs],
) -> tuple[torch.Tensor, Optional[torch.Tensor]]:
input_shape = hidden_states.shape[:-1]
hidden_shape = (*input_shape, -1, self.head_dim)
query_states = self.q_proj(hidden_states).view(hidden_shape).transpose(1, 2)
key_states = self.k_proj(hidden_states).view(hidden_shape).transpose(1, 2)
value_states = self.v_proj(hidden_states).view(hidden_shape).transpose(1, 2)
cos, sin = position_embeddings
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)
if past_key_values is not None:
# sin and cos are specific to RoPE models; cache_position needed for the static cache
cache_kwargs = {"sin": sin, "cos": cos, "cache_position": cache_position}
key_states, value_states = past_key_values.update(key_states, value_states, self.layer_idx, cache_kwargs)
attention_interface: Callable = eager_attention_forward
if self.config._attn_implementation != "eager":
attention_interface = ALL_ATTENTION_FUNCTIONS[self.config._attn_implementation]
attn_output, attn_weights = attention_interface(
self,
query_states,
key_states,
value_states,
attention_mask,
dropout=0.0 if not self.training else self.attention_dropout,
scaling=self.scaling,
sliding_window=self.sliding_window, # main diff with Llama
**kwargs,
)
attn_output = attn_output.reshape(*input_shape, -1).contiguous()
attn_output = self.o_proj(attn_output)
return attn_output, attn_weights
def rotate_half(x):
"""Rotates half the hidden dims of the input."""
x1 = x[..., : x.shape[-1] // 2]
x2 = x[..., x.shape[-1] // 2 :]
return torch.cat((-x2, x1), dim=-1)
def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
cos = cos.unsqueeze(unsqueeze_dim)
sin = sin.unsqueeze(unsqueeze_dim)
q_embed = (q * cos) + (rotate_half(q) * sin)
k_embed = (k * cos) + (rotate_half(k) * sin)
return q_embed, k_embed
class LlamaAttention(nn.Module):
"""Multi-headed attention from 'Attention Is All You Need' paper"""
def __init__(self, config: LlamaConfig, layer_idx: int):
super().__init__()
self.config = config
self.layer_idx = layer_idx
self.head_dim = getattr(config, "head_dim", config.hidden_size // config.num_attention_heads)
self.num_key_value_groups = config.num_attention_heads // config.num_key_value_heads
self.scaling = self.head_dim**-0.5
self.attention_dropout = config.attention_dropout
self.is_causal = True
self.q_proj = nn.Linear(
config.hidden_size, config.num_attention_heads * self.head_dim, bias=config.attention_bias
)
self.k_proj = nn.Linear(
config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
)
self.v_proj = nn.Linear(
config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
)
self.o_proj = nn.Linear(
config.num_attention_heads * self.head_dim, config.hidden_size, bias=config.attention_bias
)
@deprecate_kwarg("past_key_value", new_name="past_key_values", version="4.58")
def forward(
self,
hidden_states: torch.Tensor,
position_embeddings: tuple[torch.Tensor, torch.Tensor],
attention_mask: Optional[torch.Tensor],
past_key_values: Optional[Cache] = None,
cache_position: Optional[torch.LongTensor] = None,
**kwargs: Unpack[TransformersKwargs],
) -> tuple[torch.Tensor, torch.Tensor]:
input_shape = hidden_states.shape[:-1]
hidden_shape = (*input_shape, -1, self.head_dim)
query_states = self.q_proj(hidden_states).view(hidden_shape).transpose(1, 2)
key_states = self.k_proj(hidden_states).view(hidden_shape).transpose(1, 2)
value_states = self.v_proj(hidden_states).view(hidden_shape).transpose(1, 2)
cos, sin = position_embeddings
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)
if past_key_values is not None:
# sin and cos are specific to RoPE models; cache_position needed for the static cache
cache_kwargs = {"sin": sin, "cos": cos, "cache_position": cache_position}
key_states, value_states = past_key_values.update(key_states, value_states, self.layer_idx, cache_kwargs)
attention_interface: Callable = eager_attention_forward
if self.config._attn_implementation != "eager":
attention_interface = ALL_ATTENTION_FUNCTIONS[self.config._attn_implementation]
attn_output, attn_weights = attention_interface(
self,
query_states,
key_states,
value_states,
attention_mask,
dropout=0.0 if not self.training else self.attention_dropout,
scaling=self.scaling,
**kwargs,
)
attn_output = attn_output.reshape(*input_shape, -1).contiguous()
attn_output = self.o_proj(attn_output)
return attn_output, attn_weights
def eager_attention_forward(
module: nn.Module,
query: torch.Tensor,
key: torch.Tensor,
value: torch.Tensor,
attention_mask: Optional[torch.Tensor],
scaling: float,
dropout: float = 0.0,
**kwargs: Unpack[TransformersKwargs],
):
key_states = repeat_kv(key, module.num_key_value_groups)
value_states = repeat_kv(value, module.num_key_value_groups)
attn_weights = torch.matmul(query, key_states.transpose(2, 3)) * scaling
if attention_mask is not None:
causal_mask = attention_mask[:, :, :, : key_states.shape[-2]]
attn_weights = attn_weights + causal_mask
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query.dtype)
attn_weights = nn.functional.dropout(attn_weights, p=dropout, training=module.training)
attn_output = torch.matmul(attn_weights, value_states)
attn_output = attn_output.transpose(1, 2).contiguous()
return attn_output, attn_weights
def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
"""
This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
"""
batch, num_key_value_heads, slen, head_dim = hidden_states.shape
if n_rep == 1:
return hidden_states
hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
这里提到sliding_window,具体滑动窗口计算注意力的实现代码没找到,但应该是仅计算其前后sliding_window//2范围内的注意力分数(超出窗口的位置被掩码屏蔽)。Qwen2应该就是对query和key加上rope位置编码使用滑动窗口的MHA。
class Qwen2RMSNorm(nn.Module):
def __init__(self, hidden_size, eps: float = 1e-6) -> None:
"""
Qwen2RMSNorm is equivalent to T5LayerNorm
"""
super().__init__()
self.weight = nn.Parameter(torch.ones(hidden_size))
self.variance_epsilon = eps
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
input_dtype = hidden_states.dtype
hidden_states = hidden_states.to(torch.float32)
variance = hidden_states.pow(2).mean(-1, keepdim=True)
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
return self.weight * hidden_states.to(input_dtype)
def extra_repr(self):
return f"{tuple(self.weight.shape)}, eps={self.variance_epsilon}"
常规RMSNorm
class Qwen2Model(MistralModel):
def __init__(self, config: Qwen2Config):
super().__init__(config)
self.has_sliding_layers = "sliding_attention" in self.config.layer_types
@check_model_inputs
@auto_docstring
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_values: Optional[Cache] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
use_cache: Optional[bool] = None,
cache_position: Optional[torch.LongTensor] = None,
**kwargs: Unpack[TransformersKwargs],
) -> BaseModelOutputWithPast:
if (input_ids is None) ^ (inputs_embeds is not None):
raise ValueError("You must specify exactly one of input_ids or inputs_embeds")
if inputs_embeds is None:
inputs_embeds = self.embed_tokens(input_ids)
if use_cache and past_key_values is None:
past_key_values = DynamicCache(config=self.config)
if cache_position is None:
past_seen_tokens = past_key_values.get_seq_length() if past_key_values is not None else 0
cache_position = torch.arange(
past_seen_tokens, past_seen_tokens + inputs_embeds.shape[1], device=inputs_embeds.device
)
if position_ids is None:
position_ids = cache_position.unsqueeze(0)
# It may already have been prepared by e.g. `generate`
if not isinstance(causal_mask_mapping := attention_mask, dict):
# Prepare mask arguments
mask_kwargs = {
"config": self.config,
"input_embeds": inputs_embeds,
"attention_mask": attention_mask,
"cache_position": cache_position,
"past_key_values": past_key_values,
"position_ids": position_ids,
}
# Create the masks
causal_mask_mapping = {
"full_attention": create_causal_mask(**mask_kwargs),
}
# The sliding window alternating layers are not always activated depending on the config
if self.has_sliding_layers:
causal_mask_mapping["sliding_attention"] = create_sliding_window_causal_mask(**mask_kwargs)
hidden_states = inputs_embeds
# create position embeddings to be shared across the decoder layers
position_embeddings = self.rotary_emb(hidden_states, position_ids)
for decoder_layer in self.layers[: self.config.num_hidden_layers]:
hidden_states = decoder_layer(
hidden_states,
attention_mask=causal_mask_mapping[decoder_layer.attention_type],
position_ids=position_ids,
past_key_values=past_key_values,
use_cache=use_cache,
cache_position=cache_position,
position_embeddings=position_embeddings,
**kwargs,
)
hidden_states = self.norm(hidden_states)
return BaseModelOutputWithPast(
last_hidden_state=hidden_states,
past_key_values=past_key_values if use_cache else None,
)
class MistralModel(MistralPreTrainedModel):
def __init__(self, config: MistralConfig):
super().__init__(config)
self.padding_idx = config.pad_token_id
self.vocab_size = config.vocab_size
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
self.layers = nn.ModuleList(
[MistralDecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
)
self.norm = MistralRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
self.rotary_emb = MistralRotaryEmbedding(config=config)
self.gradient_checkpointing = False
# Initialize weights and apply final processing
self.post_init()
@check_model_inputs
@auto_docstring
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_values: Optional[Cache] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
use_cache: Optional[bool] = None,
cache_position: Optional[torch.LongTensor] = None,
**kwargs: Unpack[TransformersKwargs],
) -> BaseModelOutputWithPast:
if (input_ids is None) ^ (inputs_embeds is not None):
raise ValueError("You must specify exactly one of input_ids or inputs_embeds")
if inputs_embeds is None:
inputs_embeds = self.embed_tokens(input_ids)
if use_cache and past_key_values is None:
past_key_values = DynamicCache(config=self.config)
if cache_position is None:
past_seen_tokens = past_key_values.get_seq_length() if past_key_values is not None else 0
cache_position = torch.arange(
past_seen_tokens, past_seen_tokens + inputs_embeds.shape[1], device=inputs_embeds.device
)
if position_ids is None:
position_ids = cache_position.unsqueeze(0)
mask_function = create_causal_mask if self.config.sliding_window is None else create_sliding_window_causal_mask
causal_mask = mask_function(
config=self.config,
input_embeds=inputs_embeds,
attention_mask=attention_mask,
cache_position=cache_position,
past_key_values=past_key_values,
position_ids=position_ids,
)
hidden_states = inputs_embeds
position_embeddings = self.rotary_emb(hidden_states, position_ids)
for decoder_layer in self.layers[: self.config.num_hidden_layers]:
hidden_states = decoder_layer(
hidden_states,
attention_mask=causal_mask,
position_ids=position_ids,
past_key_values=past_key_values,
use_cache=use_cache,
cache_position=cache_position,
position_embeddings=position_embeddings,
**kwargs,
)
hidden_states = self.norm(hidden_states)
return BaseModelOutputWithPast(
last_hidden_state=hidden_states,
past_key_values=past_key_values if use_cache else None,
)
class MistralDecoderLayer(GradientCheckpointingLayer):
def __init__(self, config: MistralConfig, layer_idx: int):
super().__init__()
self.hidden_size = config.hidden_size
self.self_attn = MistralAttention(config=config, layer_idx=layer_idx)
self.mlp = MistralMLP(config)
self.input_layernorm = MistralRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
self.post_attention_layernorm = MistralRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
@deprecate_kwarg("past_key_value", new_name="past_key_values", version="4.58")
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_values: Optional[Cache] = None,
use_cache: Optional[bool] = False,
cache_position: Optional[torch.LongTensor] = None,
position_embeddings: Optional[tuple[torch.Tensor, torch.Tensor]] = None, # necessary, but kept here for BC
**kwargs: Unpack[TransformersKwargs],
) -> torch.Tensor:
residual = hidden_states
hidden_states = self.input_layernorm(hidden_states)
# Self Attention
hidden_states, _ = self.self_attn(
hidden_states=hidden_states,
attention_mask=attention_mask,
position_ids=position_ids,
past_key_values=past_key_values,
use_cache=use_cache,
cache_position=cache_position,
position_embeddings=position_embeddings,
**kwargs,
)
hidden_states = residual + hidden_states
# Fully Connected
residual = hidden_states
hidden_states = self.post_attention_layernorm(hidden_states)
hidden_states = self.mlp(hidden_states)
hidden_states = residual + hidden_states
return hidden_states
Qwen2模型架构,
补一下Mistral 7B模型好像是第一个使用Sliding Window Attention的,
Qwen2-VL
动态分辨率
保留原始图片宽高比,再resize到适当大小,满足[min_pixel,max_pixel]区间再做卷积patch处理。将不同图片放到一个序列里计算,根据每个图片的起止token位置计算attention mask进行隔离。
引入2D-rope旋转位置编码:对(x,y)将维度为d对输入向量分成两半,前一半用x对一维rope矩阵,后一半用y对一维rope矩阵处理,然后拼接在一起就是二维。
补代码实现
投影层用压缩Vision token + MLP Adapter:
concat空间位置临近的patch特征,再经过2层的MLP线性变换,将n压缩为n/4。引入<|vision_start>|和<|vision_end>|标记视觉token。

Q:为什么不使用Cross-Attention的架构?
A:cross-attn适合处理固定长度的kv,Qwen2-vl动态分辨率导致每个图片的token序列变长,kv长度变化导致计算效率降低(padding浪费)以及(大图和小图都变成query长度难以学习稳定的特征压缩映射),所以无法使用cross-attn做特征压缩处理。
M-rope
文本:三个维度值保持一致
图像:x,y,T时间维度保持固定
视频:对(x,y,z)将维度d的输入向量分成三份,第一份用x的一维rope矩阵处理,第二份用y的一维rope矩阵处理,第三份用z的一维rope矩阵处理,再拼接在一起。
def apply_multimodal_rotary_pos_emb(q, k, cos, sin, mrope_section, unsqueeze_dim=1):
mrope_section = mrope_section * 2
cos = torch.cat([m[i % 3] for i, m in enumerate(cos.split(mrope_section, dim=-1))], dim=-1).unsqueeze(
unsqueeze_dim
)
sin = torch.cat([m[i % 3] for i, m in enumerate(sin.split(mrope_section, dim=-1))], dim=-1).unsqueeze(
unsqueeze_dim
)
q_embed = (q * cos) + (rotate_half(q) * sin)
k_embed = (k * cos) + (rotate_half(k) * sin)
return q_embed, k_embed
统一图像和视频:图片复制一份变为时序为2的帧序列,视频以每秒两帧的速率对视频进行采样,最终可采样偶数个帧序列。
Qwen2.5-VL
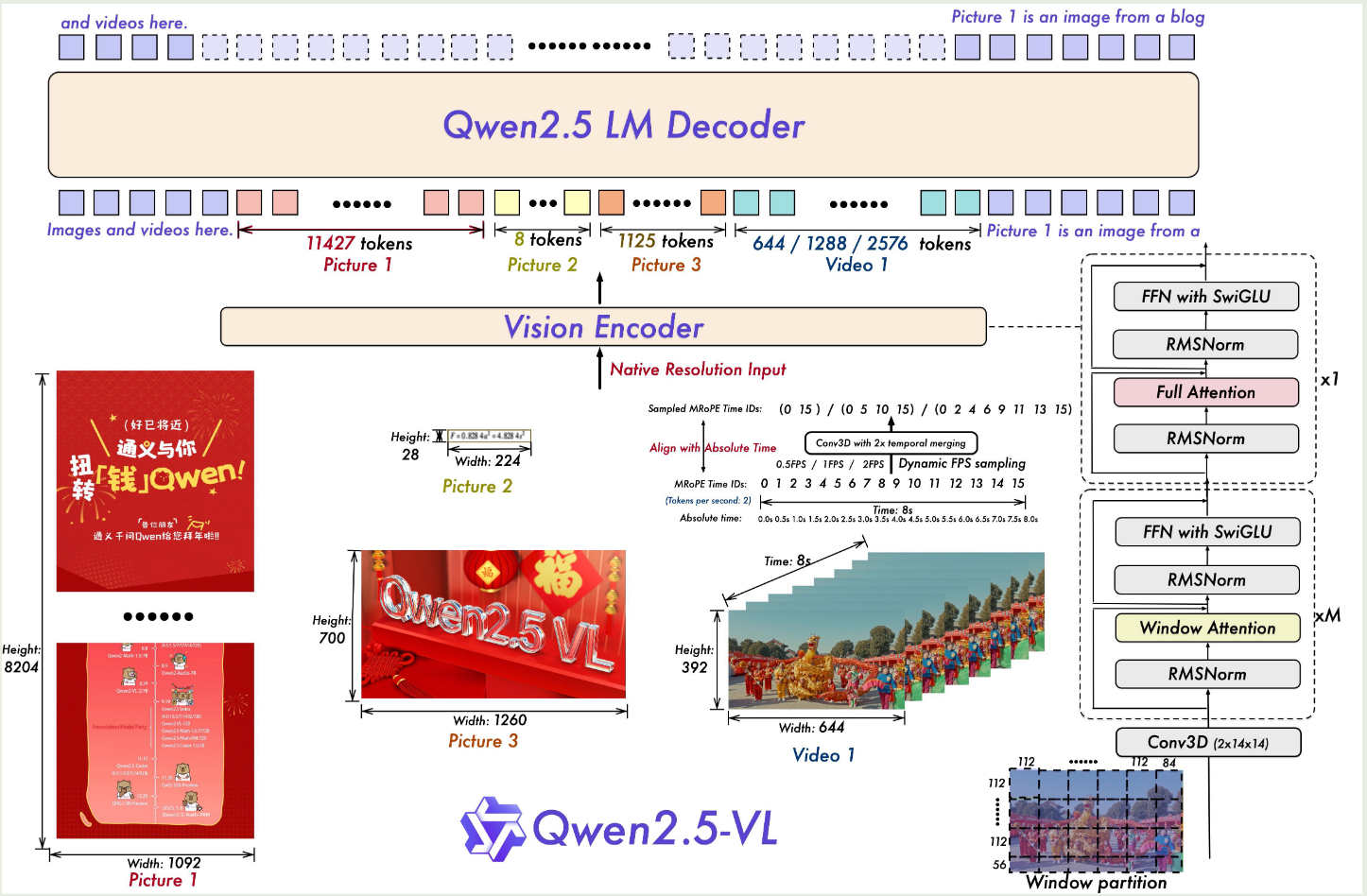
Qwen-VL将box的坐标点做(0,1000)的规范化处理,Qwen2.5-VL不进行坐标归一化,而是使用实际的像素点来表示坐标,这样能是模型学习到图像的真实尺寸信息。
Qwen2-VL的M-rope对于一个模态的起始位置的position ID,是相对于前面模态三维ID中最大的ID再加1得到。这对于时序维度的ID处理其实是不合理的,视频的时间是有绝对含义的,所以2.5对时间维度的位置ID,采用了绝对位置编码。同时也引入了动态帧的技术,每秒随机动态采集帧序列,使得模型能够通过不同时间ID的间隔,来学习时间的节奏。
从头训练原声动态分辨率的ViT,引入窗口注意力机制,只有四层是全注意力层,其余层最大窗口大小为8*8,小于8*8部分不填充保持原始尺度。
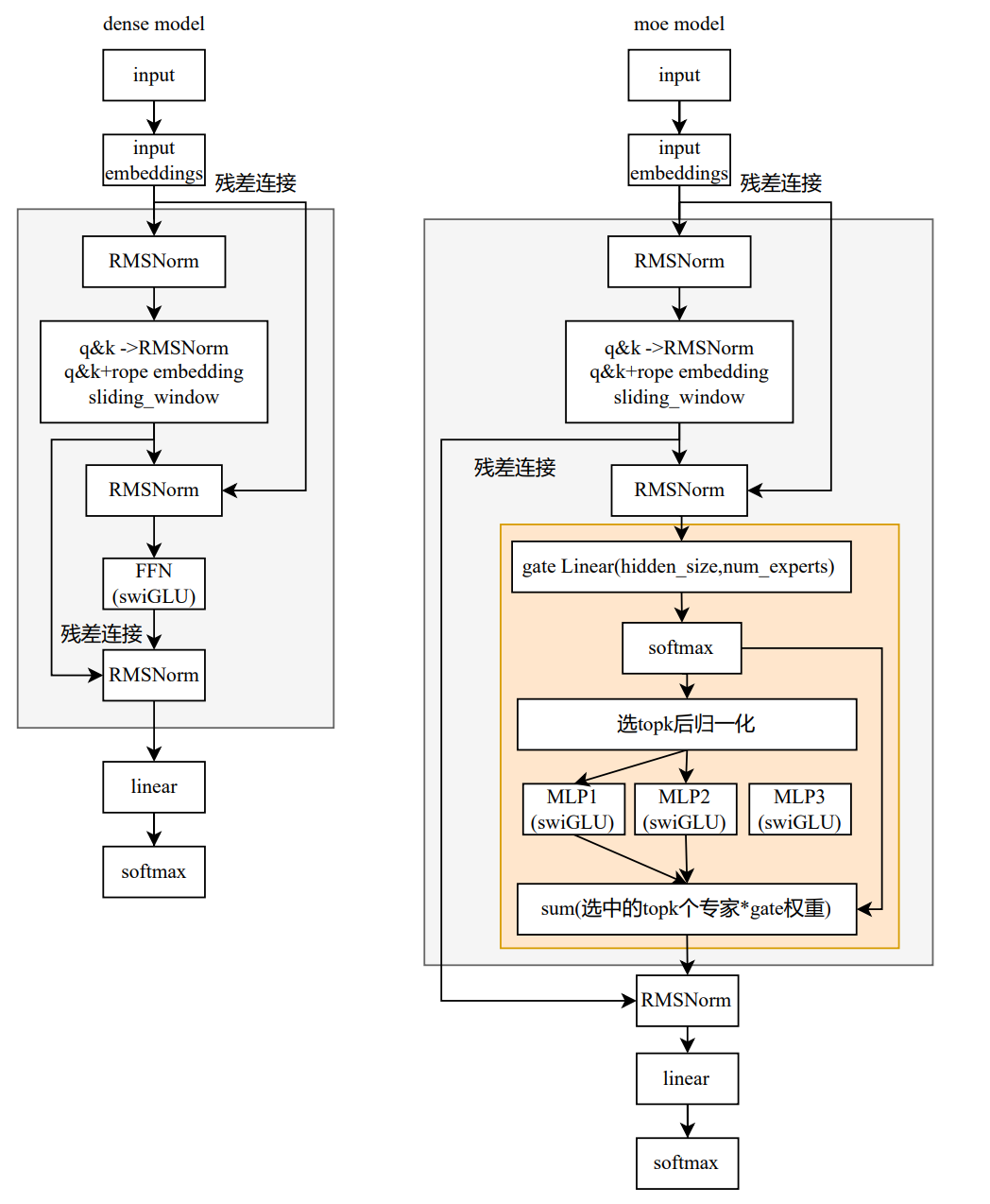
Qwen3
modular_qwen3_moe.py
class Qwen3MoeSparseMoeBlock(nn.Module):
def __init__(self, config):
super().__init__()
self.num_experts = config.num_experts
self.top_k = config.num_experts_per_tok
self.norm_topk_prob = config.norm_topk_prob
# gating
self.gate = nn.Linear(config.hidden_size, config.num_experts, bias=False)
self.experts = nn.ModuleList(
[Qwen3MoeMLP(config, intermediate_size=config.moe_intermediate_size) for _ in range(self.num_experts)]
)
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
""" """
batch_size, sequence_length, hidden_dim = hidden_states.shape
hidden_states = hidden_states.view(-1, hidden_dim)
# router_logits: (batch * sequence_length, n_experts)
router_logits = self.gate(hidden_states)
routing_weights = F.softmax(router_logits, dim=1, dtype=torch.float)
routing_weights, selected_experts = torch.topk(routing_weights, self.top_k, dim=-1)
if self.norm_topk_prob: # only diff with mixtral sparse moe block!
routing_weights /= routing_weights.sum(dim=-1, keepdim=True)
# we cast back to the input dtype
routing_weights = routing_weights.to(hidden_states.dtype)
final_hidden_states = torch.zeros(
(batch_size * sequence_length, hidden_dim), dtype=hidden_states.dtype, device=hidden_states.device
)
# One hot encode the selected experts to create an expert mask
# this will be used to easily index which expert is going to be sollicitated
expert_mask = torch.nn.functional.one_hot(selected_experts, num_classes=self.num_experts).permute(2, 1, 0)
# Loop over all available experts in the model and perform the computation on each expert
expert_hit = torch.greater(expert_mask.sum(dim=(-1, -2)), 0).nonzero()
for expert_idx in expert_hit:
expert_layer = self.experts[expert_idx]
idx, top_x = torch.where(expert_mask[expert_idx].squeeze(0))
# Index the correct hidden states and compute the expert hidden state for
# the current expert. We need to make sure to multiply the output hidden
# states by `routing_weights` on the corresponding tokens (top-1 and top-2)
current_state = hidden_states[None, top_x].reshape(-1, hidden_dim)
current_hidden_states = expert_layer(current_state) * routing_weights[top_x, idx, None]
# However `index_add_` only support torch tensors for indexing so we'll use
# the `top_x` tensor here.
final_hidden_states.index_add_(0, top_x, current_hidden_states.to(hidden_states.dtype))
final_hidden_states = final_hidden_states.reshape(batch_size, sequence_length, hidden_dim)
return final_hidden_states, router_logits
Qwen3-VL
模型架构
Transformer架构
llama架构
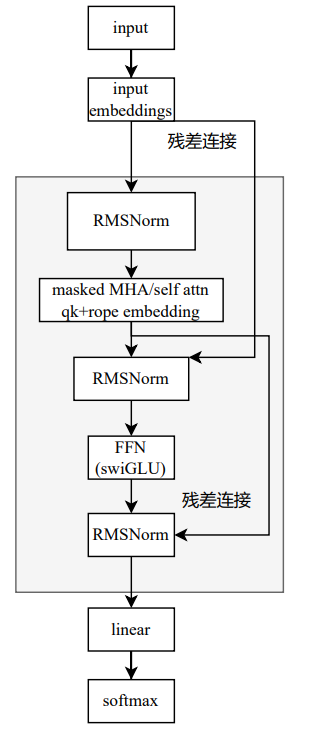
llama2架构
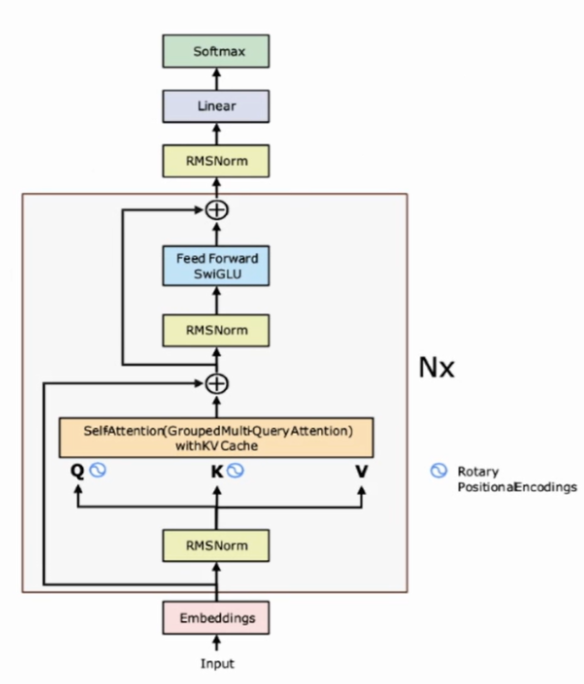
Qwen3架构


















 1167
1167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









