



数据处理
数据获取
爬虫
实际工作中大部分都是从数据库里取数
数据标注
只有一小部分有标签 大部分无标签的话
半监督学习:没标注数据和有标注数据共同使用
做法1:半监督学习 基于有标签的小部分数据进行训练 在无标签上测试得到标签 (原始数据+生成标签数据再次训练模型,更新标签)
自学习,假设我们有一些已经标注好的数据,一在小数据里训练一下模型,二再对没标好的进行预测,称为伪标号,三将两种数据合并,再进行预测,多次循环。判断标号的确信程度选择留下来的标号数据,再进行循环预测,让样本置信程度更高。
做法2:将不确定的标签交给人工标注
做法3:弱监督学习 根据数据结果人工设置筛选条件去获得一些标签 如包含“xx”关键词的就为黑样本
使用更深的神经网络或集成模型来标注数据 不需要考虑线上部署的花费
数据清洗
去掉缺失大于30%的列 确认数据类型是否正确
问题:70w数据怎么分析 一样计算方差均值吗?读取速度慢
分类数据怎么看数据分布
数据错误 进行数据清洗 超出范围、模式冲突、看模型数据分布和一致性
进行数据变换 因为对数值敏感 可能受单位影响

特征工程

随机森林 随机抽取特征生成n颗树,每个树的结果根据多数投票得到最终结果。
boosting 每颗树不是独立完成 而是顺序完成 一起合成得到一个最终的结果。
全连接层 所有的输入和输出大小和数据集相关
卷积 自定义卷积核 每次不用看所有的 只看相关一小部分的特征
但是卷积对位置敏感 如果手抖同一个物品出现在不同区域 所以加入池化层增加鲁棒性
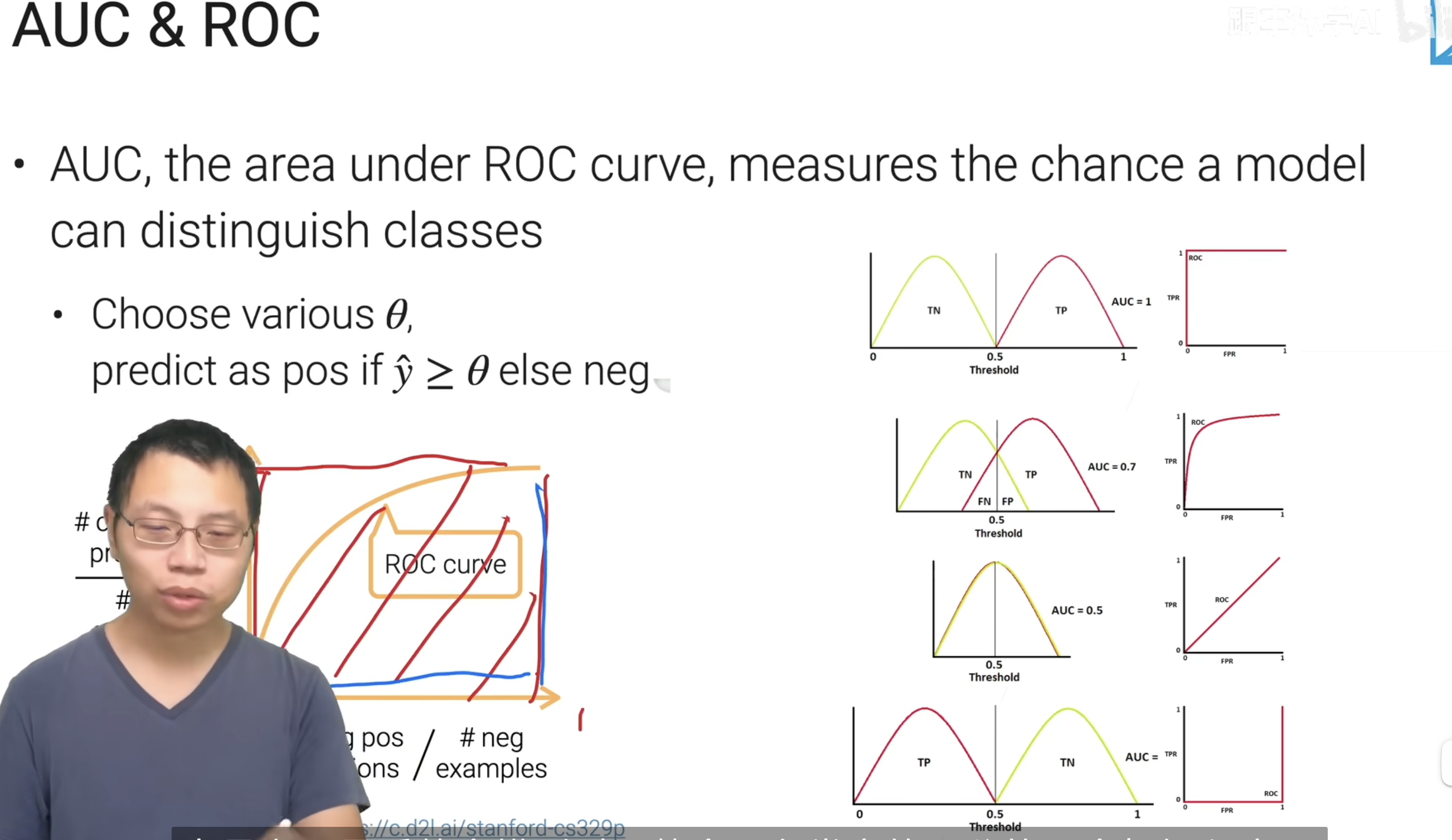
auc判断是否能将两个类很好的区别开来
auc=0.5 完全区分不开 一般>0.5 如果<0.5则auc为1-0.5符合取反


















 199
199

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









