



 本文介绍了rime输入法中encoder.h和encoder.cc文件的短语编码功能,详细阐述了如何根据仓颉五代规则进行编码配置,包括最大输入字长、最小词频设定以及不同长度词的编码公式。通过exclude_patterns和rules,实现特定字词的排除和编码逻辑。
本文介绍了rime输入法中encoder.h和encoder.cc文件的短语编码功能,详细阐述了如何根据仓颉五代规则进行编码配置,包括最大输入字长、最小词频设定以及不同长度词的编码公式。通过exclude_patterns和rules,实现特定字词的排除和编码逻辑。
2021SC@SDUSC
encoder.h和encoder.cc是定义关于短语编码的功能,先看.h文件
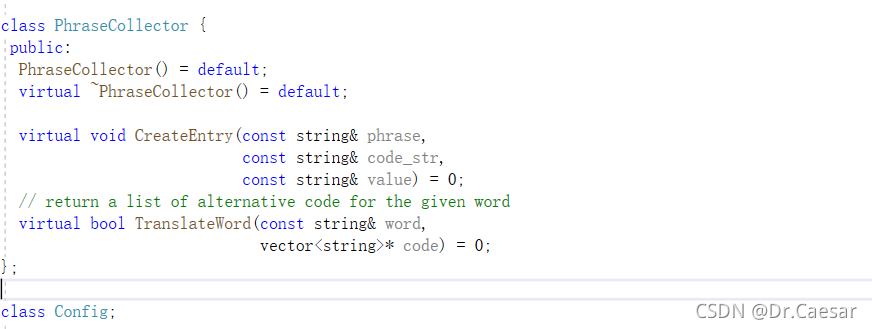
这里定义了一个短语收集类,它定义了一个功能 返回给定单词的可选代码列表。
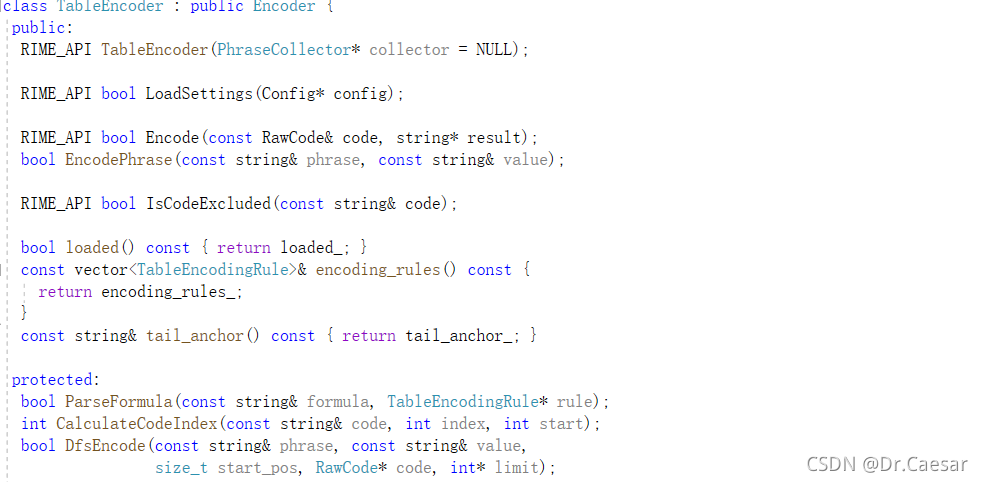
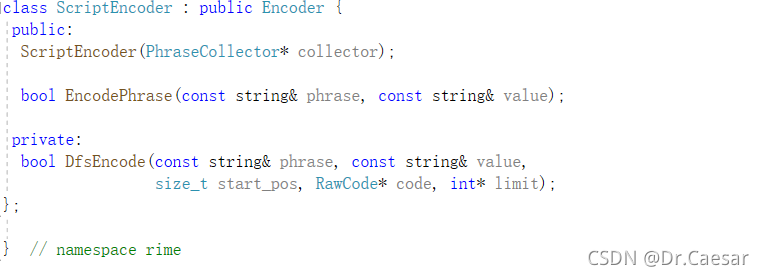
然后就是一些基于规则和音节的短语编码定义。再看看.cc文件
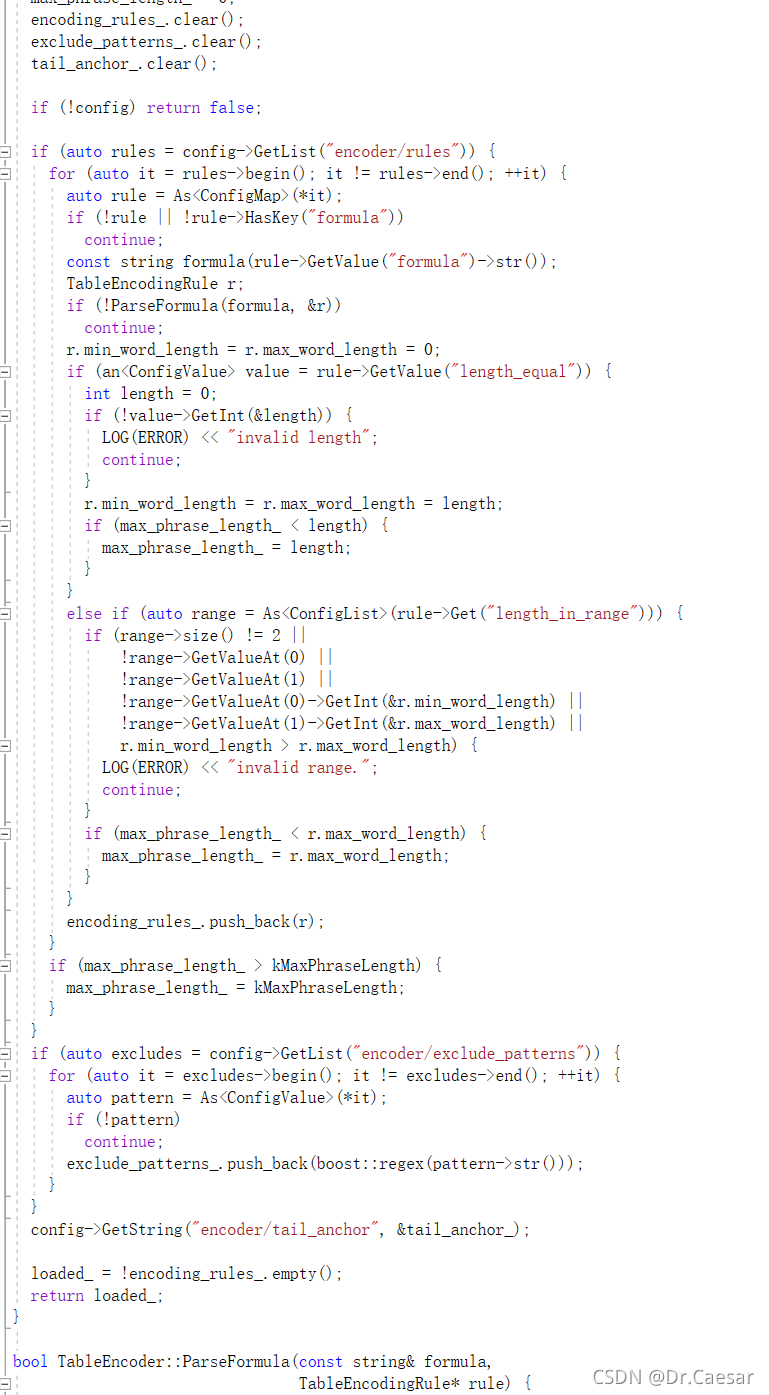
这里是按照仓颉五代的配置来进行编码的。max_phrase_length配合use_preset_vocabulary来限制最大输入字长min_phrase_weight配合use_preset_vocabulary来设定输入最小词频,根据仓颉五代规则 encoder:
exclude_patterns:
- '^x.*$'
- '^z.*$'
rules:
- length_equal: 2//对于2字词
formula: "AaAzBaBbBz"//取第一字首尾码、第二字首次尾码
- length_equal: 3//对于三字词
formula: "AaAzBaBzCz"//取第一字首尾码、第二字首尾码、第三字尾码
- length_in_range: [4, 10]//对于4-10字词
formula: "AaBzCaYzZz"//取第一字首码、第二字尾码、第三字首码、倒数第二字和末字尾码
tail_anchor: "'"

根据上述规则进行字典匹配


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









