




 本文介绍了Rime输入法中syllabifier.h和syllabifier.cc文件的音节到汉字映射及模糊音输入算法。通过n叉树记录输入队列的访问,并在拼写过程中优先选择最佳拼写类型,避免错误。同时,利用尾随分离符区分多音节输入。在路径中寻找最佳公共类型,优化模糊音节点的选择。
本文介绍了Rime输入法中syllabifier.h和syllabifier.cc文件的音节到汉字映射及模糊音输入算法。通过n叉树记录输入队列的访问,并在拼写过程中优先选择最佳拼写类型,避免错误。同时,利用尾随分离符区分多音节输入。在路径中寻找最佳公共类型,优化模糊音节点的选择。
2021SC@SDUSC
syllabifier.h和syllabifier.cc音节发生器文件,这个文件就是之前提到的音节到汉字的映射、模糊音输入等功能的具体算法实现
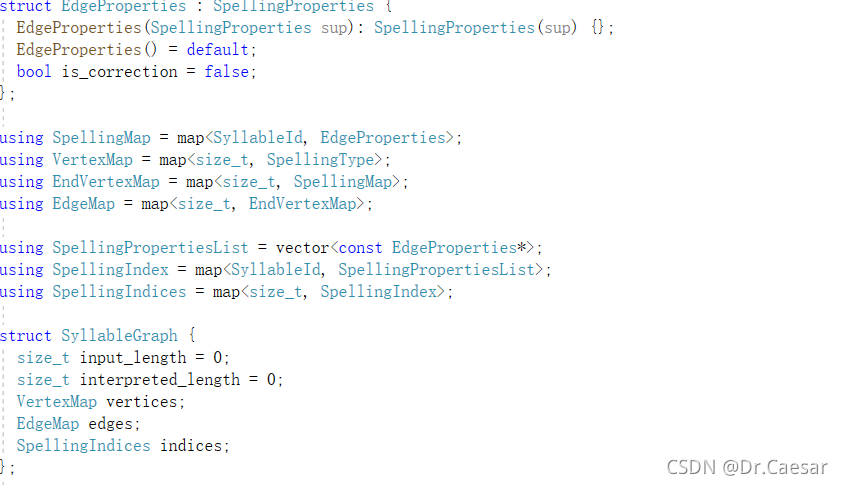
这里定义了多种拼写属性,半角,全角,全拼等还有两个api 创建音节图和校正。因为算法篇幅较长,就不将头文件展开解析了。直接进入正题。
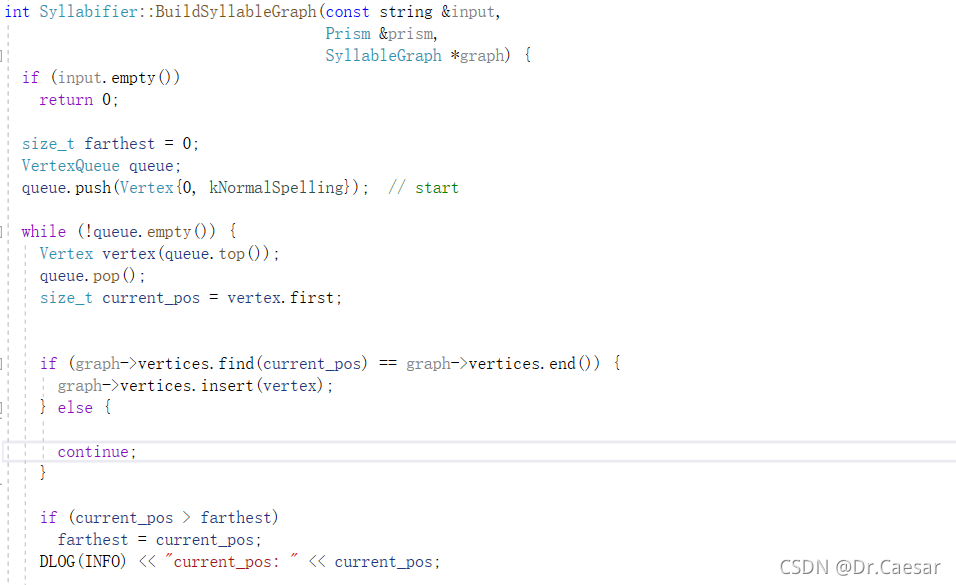
它首先是对输入队列的n叉树记录对顶点的访问,然后记录对顶点的访问首选拼写类型优先。当graph->vertices[current_pos] = std::min(vertex.second, graph->vertices[current_pos]);,丢弃拼写错误的类型。
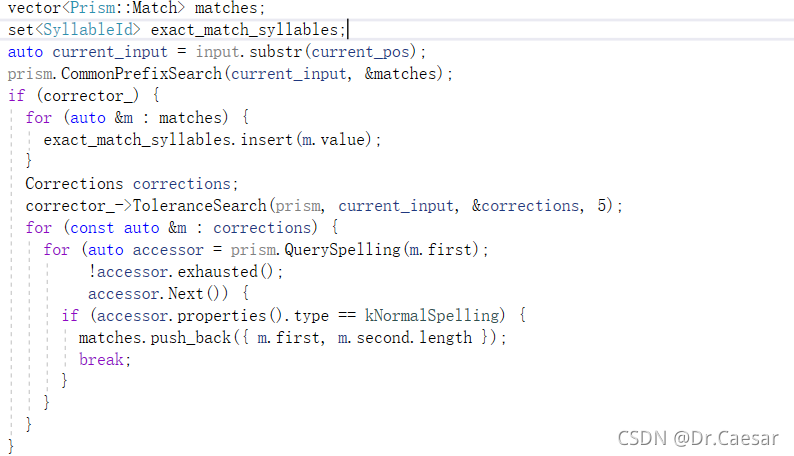
这里是用一个音节来尝试能走到哪里,从而验证算法
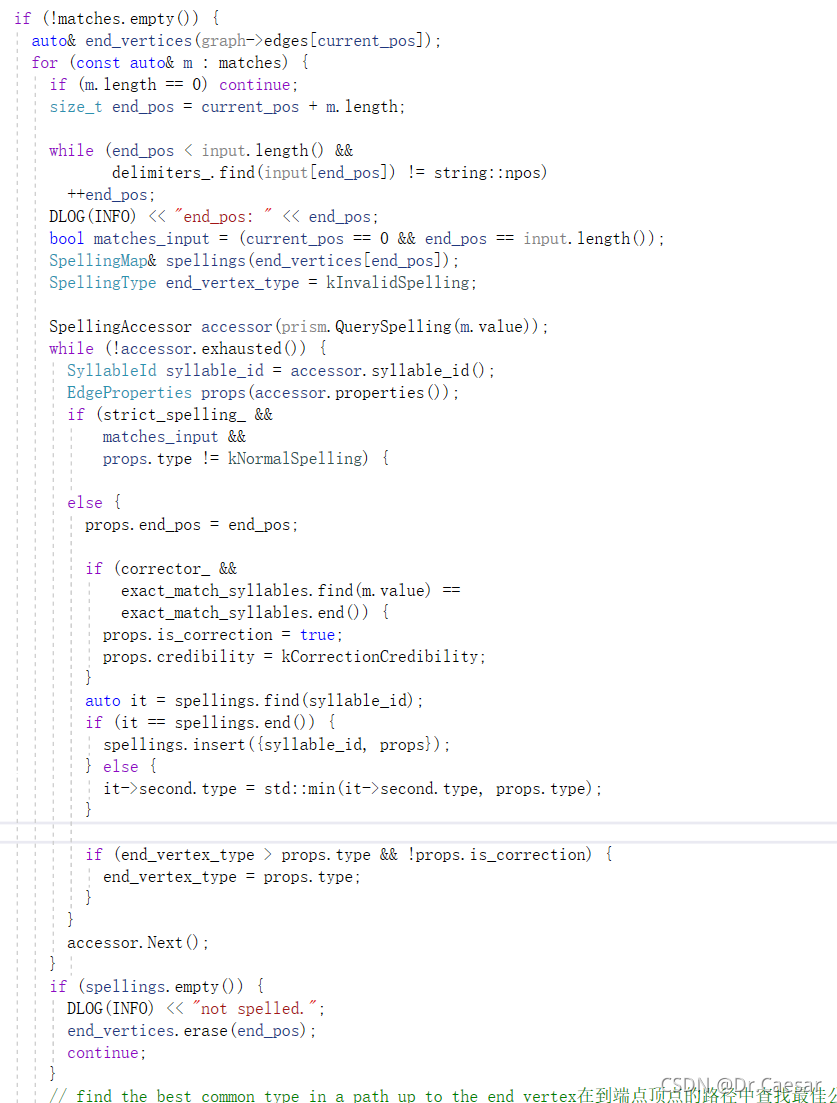
使用尾随分离符来区别多个音节输入。再启动拼写代数时,拼写的结果是一组音节的话就正常输出,否则他与音节本身完全相似。当你在输入音节拼写循环中实现了每个音节严格拼写的情况,那么就取消模糊拼写或
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 997
997

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









