




 本文介绍了Rime输入法中的calculus.h和calculus.cc文件,涉及音译、转换、擦除、派生、模糊音和缩写等功能。音译利用发音近似进行汉字匹配,转换简化音译过程,而模糊音设计考虑了易混淆音节,通过常量校正实现输入的灵活转换。
本文介绍了Rime输入法中的calculus.h和calculus.cc文件,涉及音译、转换、擦除、派生、模糊音和缩写等功能。音译利用发音近似进行汉字匹配,转换简化音译过程,而模糊音设计考虑了易混淆音节,通过常量校正实现输入的灵活转换。
2021SC@SDUSC
来说说第二个文件calculus.h和calculus.cc(微积分)从名字来看的话应该是讲如何来通过拼音输入来和字典库中的文字匹配,我们来大致看看。
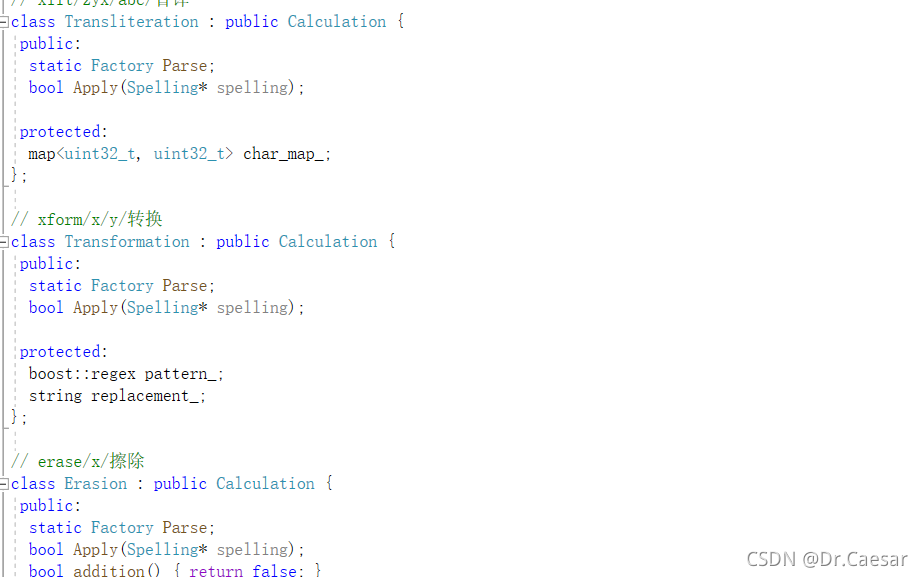
首先他定义了很多rime的api,音译、擦除、转换 、派生、模糊音、缩写等,代码我就只截取了一小部分,就不在此一一展示了,接下来进入正题.cc文件
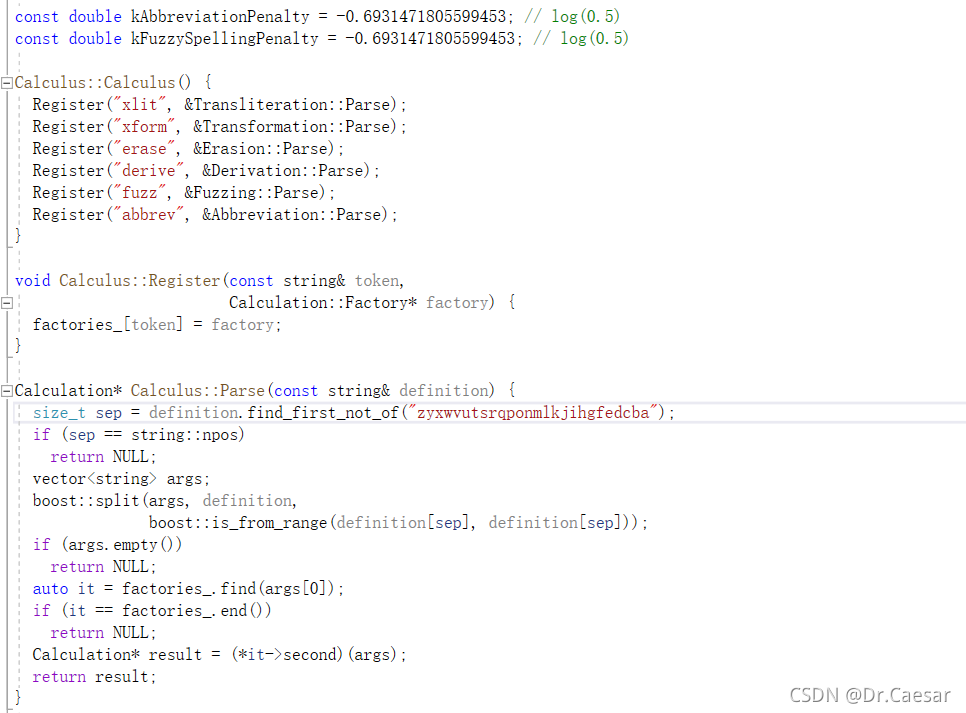
首先是对各种api的注册和常量的设计,常量主要是缩写和模糊音处罚(???这里我不是很懂,可能是出现概率?)
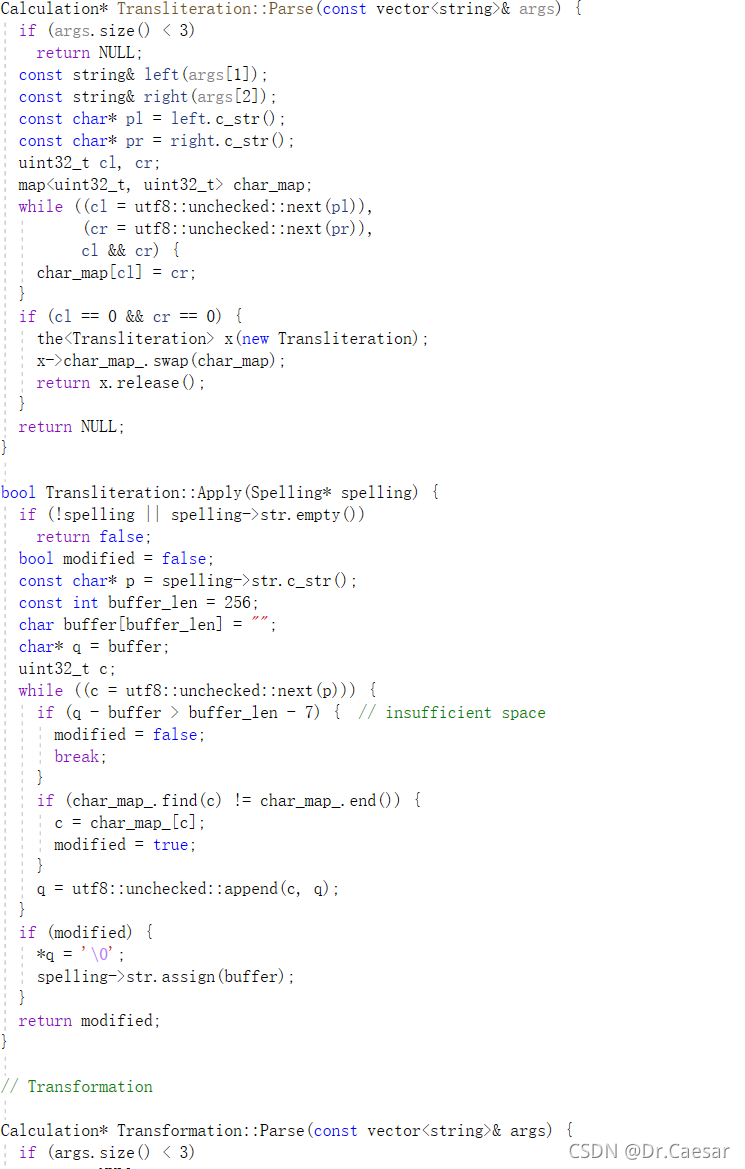
首先是音译的功能。音译,指用发音近似的汉字将外来语翻译过来,这种用于译音的汉字不再有其自身的原意,只保留其语音和书写形式。首先这里这个陌生的uint32_t是Linux c开发中的自定义数据拓展型,其实就是unsigned int 32 bit(无符号数32位int型)这样做的好处是到时候修改,只用修改中间的位数即可。这个算法其实我并没有理解地很透彻,他应该是调用或者模拟了谷歌的一个音译工具,他把输入输出的音节分为左右两个字符串数组进行校验,是一种根据语音相似性将一类语言体系的文字对应到另一类语言体系的文字的方法。借助这个工具,在输入拉丁字母(例如 a、b、c 等)后,系统便会将其转换成目标语言中具有相似发音的字符。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 988
988

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









