




作者 | 郭炜
编辑 | Debra Chen
在当今的商业环境中,大数据的管理和应用已经成为企业决策和运营的核心组成部分。然而,随着数据量的爆炸性增长,如何有效利用这些数据成为了一个普遍的挑战。
本文将探讨大数据架构、大模型的集成,以及如何将大模型集成到公司大数据架构中,并使用Apache SeaTunnel和WhaleStudio将公司内部数据进行“百科全书化”,利用大数据和大模型来提升企业运营效率。
大模型在整体公司大数据架构中的位置
当今,无论大企业还是小公司,其实都会遇到同样的问题:公司里沉淀的数据量巨大,但到底该怎么使用?
大模型的横空出世让数据利用有了全新的使用途径,问题是如何大量获得公司的数据,变成“你”的大模型?
以及如何将大模型灌入公司内部数据,并“百科全书”化?
大数据与大模型架构概览
为了更好地回答这些问题,我们首先需要弄清楚大模型在企业复杂的数据结构中处于什么位置。目前,全球流行的大数据结构图如下所示:
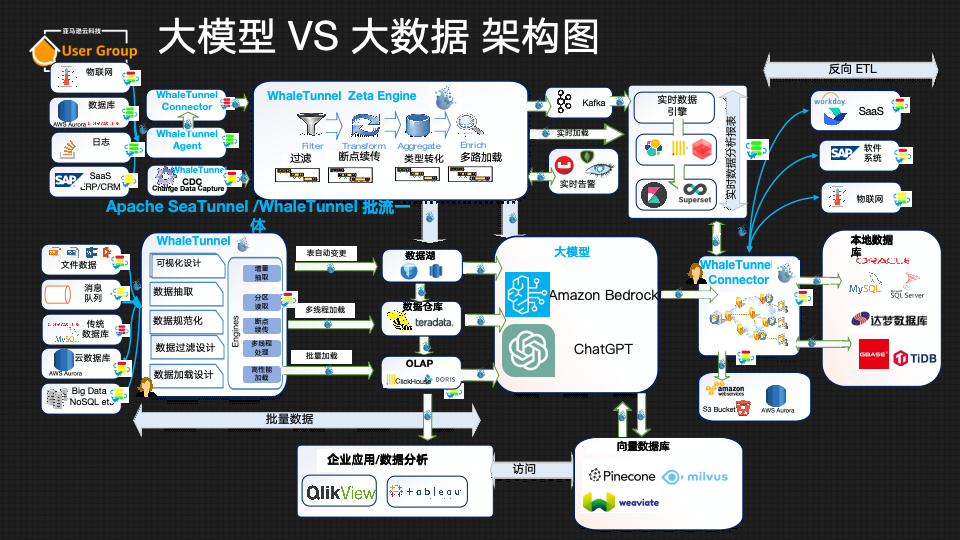
企业在处理大数据时,通常会将数据分为实时数据和批量数据两大类。实时数据可以来自车联网、数据库日志、点击流等多种来源,而批量数据则可能包括文件、报表、CSV文件等。这些数据可以通过各种工具和技术,如Apache Kafka、Amazon Kinesis等进行处理,最终被整合到企业的大数据分析系统中。
大模型在大数据架构中扮演着至关重要的角色。它们能够处理和分析大量数据,为企业提供深入的洞察和预测。大模型可以通过两种主要方法进行集成:
- 基于开源模型的优化:企业可以使用开源的大模型,并根据自己的数据进行优化,以提高模型的性能。这种方法虽然复杂,对于普通用户来做操作比较困难,但可以训练出高度定制化的模型,具体训练方法可以参考《用一杯星巴克的钱,训练自己私有化的ChatGPT》
- 数据向量化:另一种方法是将数据向量化,即将数据转换为大模型易于处理和查询的格式,然后快速地将其放入企业自己的向量数据库中。
这就是大模型在大数据架构中所处的位置和作用,大模型作为大数据架构的核心技术组件,在数据转换、预测分析和智能应用等方面发挥着不可替代的作用,是实现大数据价值的关键所在。
数据高速公路:Apache SeaTunnel& WhaleStudio
数据同步是大数据架构中的另一个关键环节。使用如Apache NiFi、Apache Spark、Sqoop等工具,可以实现数据在不同系统和数据库之间的实时和批量同步。这些工具支持跨云和混合云环境,能够处理来自各种数据源的数据,并将其同步到目标数据库或数据仓库中。但是因为依赖开源,它们的数据源支持力度非常有限。
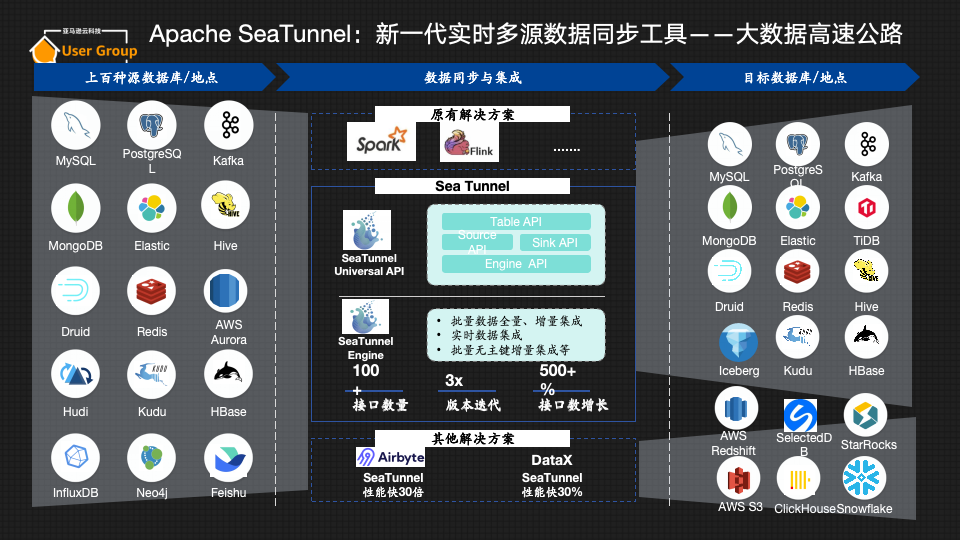
Apache SeaTunnel:新一代实时多源数据同步工具,大数据的高速公路
有一个非常形象的比喻可以简单明了地概括Apache SeaTunnel的作用——大数据的高速公路。它可以把各种各样的数据源,如MySQL、RedShift、Kafka等数据,实时和批量数据同步至目标数据库。区别于Apache NiFi、Apache Spark,新一代实时多源数据同步工具Apache SeaTunnel目前已经可以支持上百种源数据库/目的地的数据同步与集成,并支持以跨云和混合云的方式同步数据,便于不同的用户进一步进行大数据和大模型训练。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 5595
5595

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











