



 ApacheDolphinScheduler是一个分布式工作流编排调度系统,其高可用性通过冗余组件和故障转移实现。API-Server和Worker可以通过增加实例实现负载均衡,Master则通过分片策略和主备或分布式锁机制保证高可用。当节点宕机时,Master会监控并执行故障转移,确保系统稳定运行。
ApacheDolphinScheduler是一个分布式工作流编排调度系统,其高可用性通过冗余组件和故障转移实现。API-Server和Worker可以通过增加实例实现负载均衡,Master则通过分片策略和主备或分布式锁机制保证高可用。当节点宕机时,Master会监控并执行故障转移,确保系统稳定运行。

高可用性是 Apache DolphinScheduler 的特性之一。它通过冗余来避免单点问题,所有组件天然支持横向扩容;但仅仅保证了冗余还不够,当系统中有节点宕机时,还需要有故障转移机制能够自动将宕机节点正在处理的工作转移到新节点上执行,从而实现高可用。
01 DolphinScheduler架构介绍
Apache DolphinScheduler是一个分布式易扩展的工作流编排调度系统。其核心架构主要由3部分组成:APIServer, Master, Worker。
其中API-Server负责接收所有的用户操作请求,Master负责工作流的编排和调度,Worker负责工作流中任务的执行。整个系统通过注册中信做服务发现,通过数据库持久化元数据。 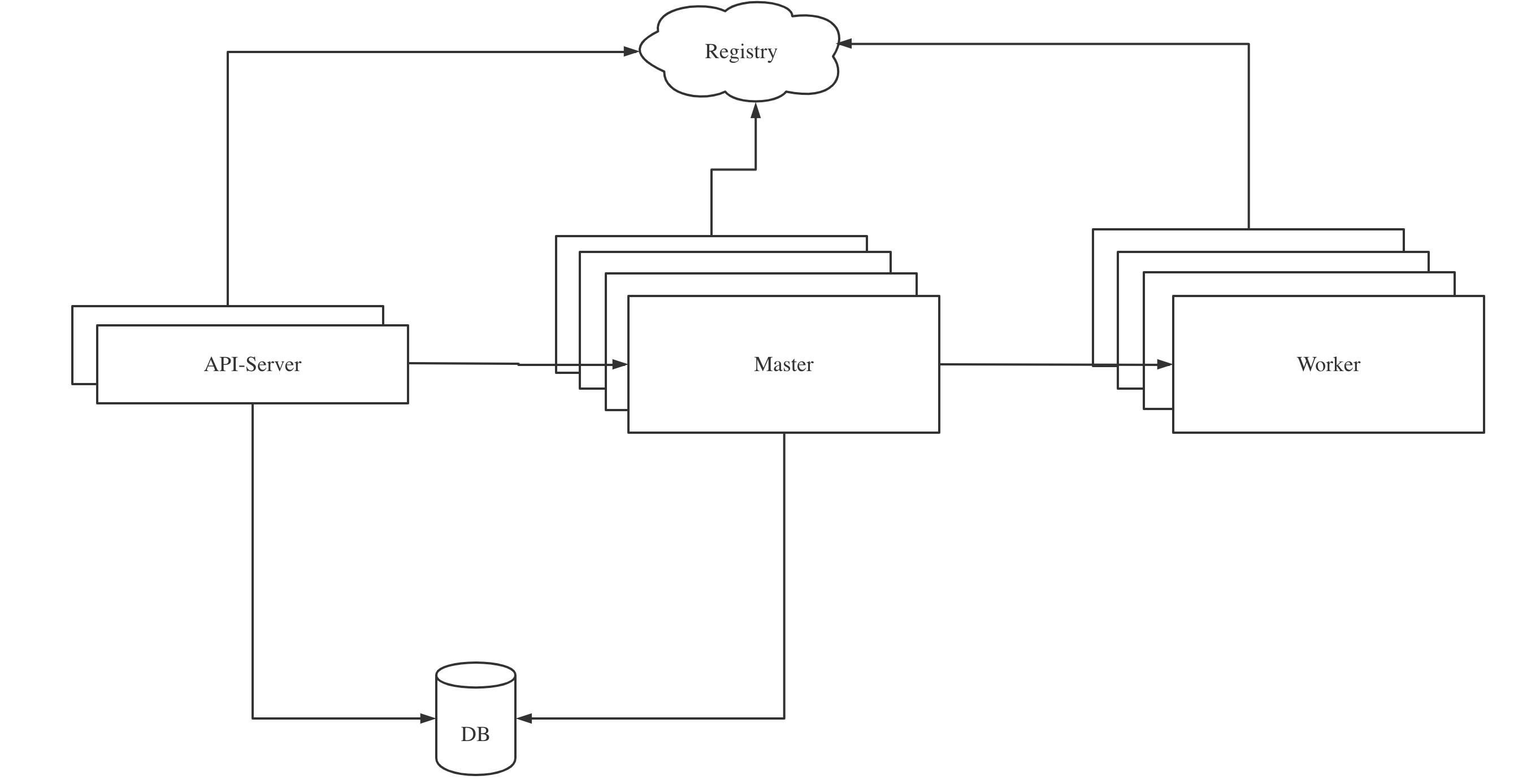
一个工作流执行的生命周期如下:
- 在API-Server中创建,并将元数据持久化到DB中。
- 通过手动点击或定时执行生成一个触发工作流执行的Command写入DB。
- Master消费DB中的Command,开始执行工作流,并将工作流中的任务分发给Worker执行。
- 当整个工作流执行结束之后,Master结束工作流的执行。
02 DolphinScheduler集群高可用
分布式系统中必须要考虑的因素是系统整体的高可用(HA)。高可用指的是系统整体能够对外提供服务的时间占比很高,系统因为故障而无法提供服务的时间占比很短。
为了保证系统的高可用,架构的一个设计原则是通过冗余来避免出现单点问题。单点问题是指系统中某一任务组件只有单个实例,如果该实例出现了故障,那么会导致系统整体不可用。
Apache DolphinScheduler也是通过冗余来避免单点问题,在DolphinScheduler中,所有组件天然就支持横向扩容。
01 API-Server高可用
对于API-Server来说,由于API-Server是一个无状态服务,因此API-Server可以很容易的通过部署多台来保证高可用。在部署多台API-Server之后,只需要将他们注册在同一网关,即可一起对外提供服务。 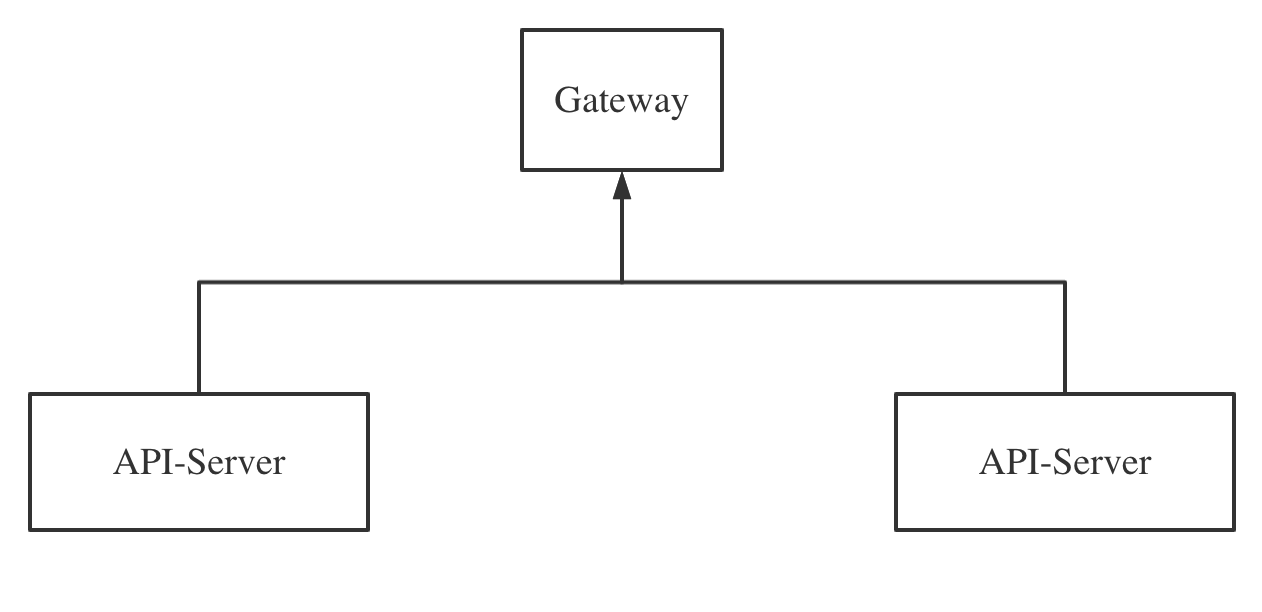
02 Master高可用
Master作为DolphinScheduler中处理工作流的核心组件,其可用性直接关系到整个系统的稳定性。
由于Master并不像API-Server一样只是被动的接收外界的请求,Master会主动的消费数据库中的工作流,而一个工作流在某一时刻只能被一个Master处理,因此Master在横向扩容的时候需要考虑的问题更多。
一种比较简单的方案是采用active-standby的方式,即部署多台Master服务,但是只有一台处于active状态,对外工作,其他Master服务都处于standby状态,只有等active的Master宕机,standby状态的Master会重新选举出一台新的active Master对外工作。 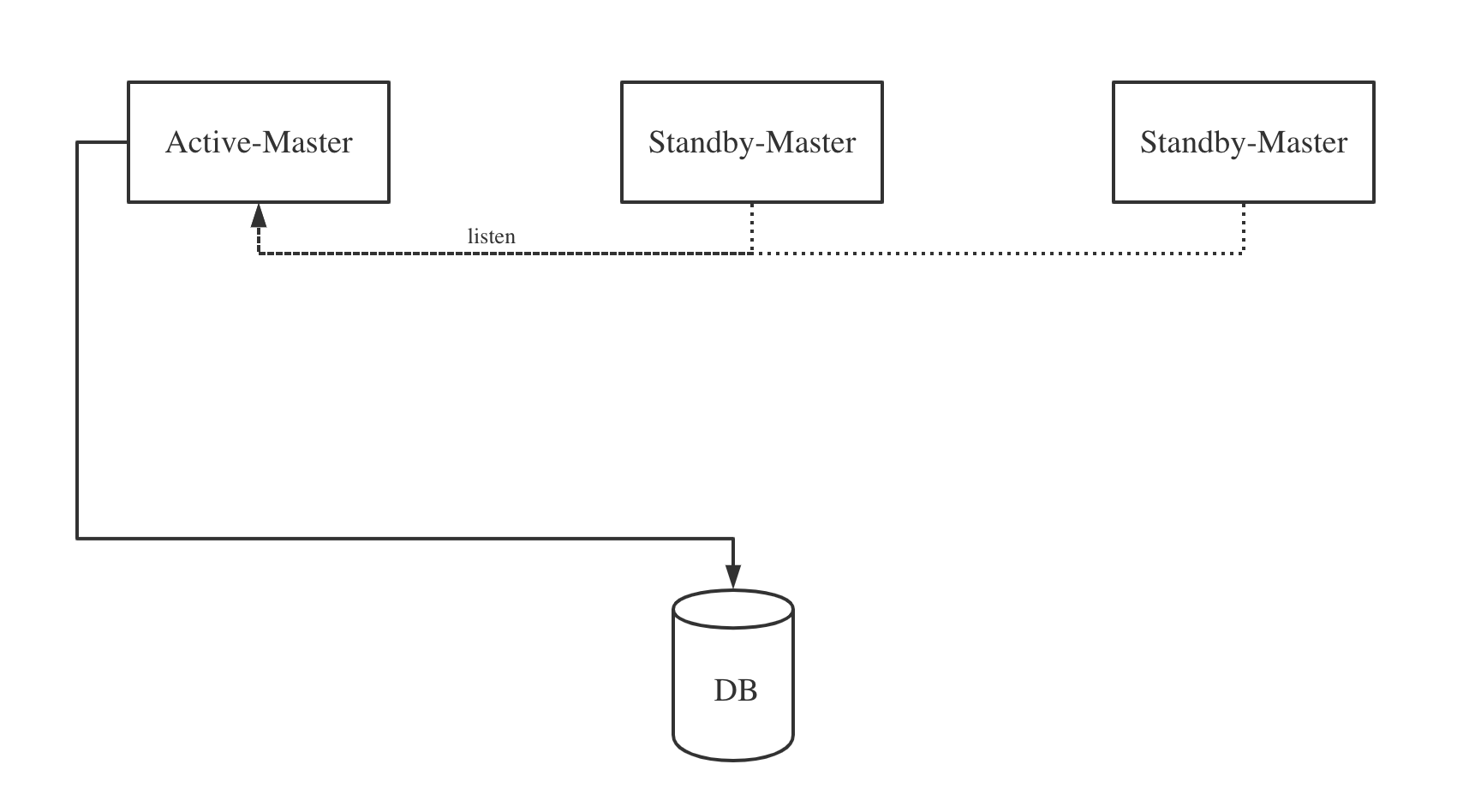
这种方案实现起来简单,同时可以很好的解决Master单点问题,但是这种active-standby的架构同一时刻只能有一台Master进行工作,对于DolphinScheduler来说,由于Master需要处理工作流的调度,因此这会导致整个集群的工作流处理吞吐量上不去。
在DolphinScheduler中采用分片的方式对工作流元数据进行了预划分,具体来说对工作流产生的command根据id进行分片,将command均匀的分散到所有的Master,这样来达到所有Master都可以同时工作,并且不会互相影响。
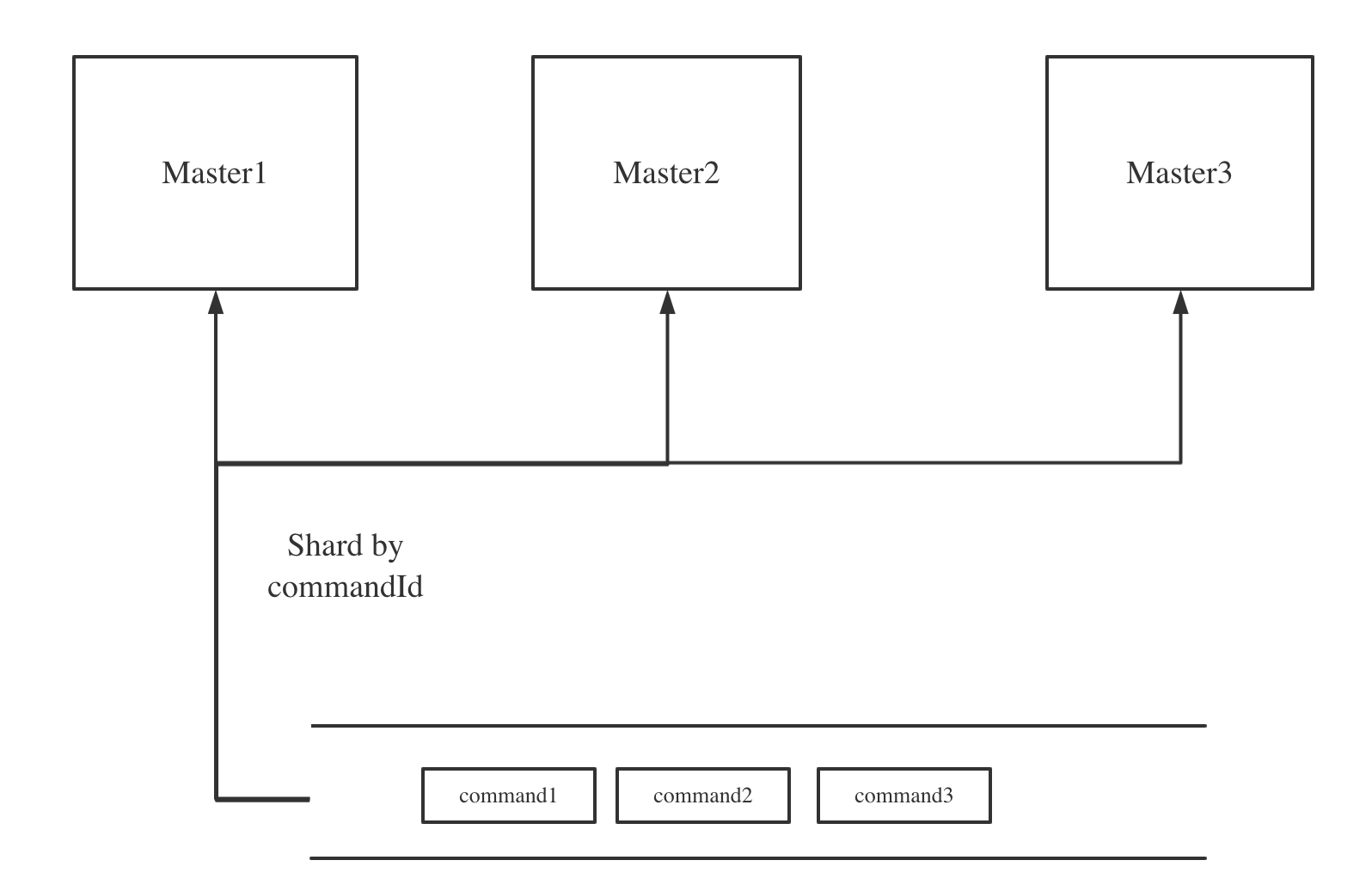 Master通过注册中心来感知集中其他Master的节点信息,由于当节点上下线的时候,Master的元数据变更通知到所有Master服务时间会不一致,因此通过数据库事务做了进一步的保障,保证同一个Command只会被处理一次。
Master通过注册中心来感知集中其他Master的节点信息,由于当节点上下线的时候,Master的元数据变更通知到所有Master服务时间会不一致,因此通过数据库事务做了进一步的保障,保证同一个Command只会被处理一次。
03 Worker高可用
Worker作为DolphinScheduler中任务执行组件,其扩展比较容易,这是由于在设计上,Worker主要是被动的接收Master分发的任务,他不会主动去数据库中拉取任务。因此Woker只需要在横向扩容之后注册到注册中心即可,Master会通过注册中心感知到Worker的元数据变更。
03 DS中的Failover实现原理
仅仅保证了冗余还不够,当系统中有节点宕机时,还需要有故障转移机制能够自动将宕机节点正在处理的工作转移到新节点上执行。在DolphinScheduler中所有的故障转移工作都由Master完成。
Master会监听注册中心中所有Master和Worker的健康状况,一旦有节点下线,所有Master会收到该节点下线的事件,然后执行容错逻辑。
通过竞争分布式锁的方式来决定由谁来进行本次故障转移操作。
在执行容错操作时,会根据Master/Worker的类型不同执行不同的容错操作。对于发生Master容错时,所有存活的Master会通过竞争分布式锁的方式来决定由谁来进行本次故障转移操作,竞争到分布式锁的Master会去数据库中查询出宕机节点中正在运行的工作流实例生成容错请求。对于发生Worker容错,所有Master会找出当前内存中是否有正在该Worker上运行的任务,如果有那么触发任务容错逻辑。
一种特殊情况是,可能集群中所有Master都宕机了,那么此时没有Master可以执行容错逻辑,因此当后面集群恢复时,在Master启动的时候也会进行容错逻辑。
本文由 白鲸开源科技 提供发布支持!


















 294
294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











