



点亮 ⭐️ Star · 照亮开源之路
https://github.com/apache/dolphinscheduler
这是一系列关于 DolphinScheduler v2.0.1的源码分析文章,包括对 Master、Worker 基本原理、Master 提交执行、Worker 接受执行、 command 解耦、command 唯一消费实现原理、kill 执行分析等在内的深度解析与思考。
1
command唯一消费实现原理
实现原理总共分三步:
每个 master 分配 slot
master 在初次启动和注册的监听中都核心调用了 syncMasterNodes() 方法。
该方法主要更新 全部 MASTER_SIZE 和自身SLOT_LIST,SLOT_LIST 只存放自身 slot 值。
至此,每个 master 都能知道总 master 个数和自己的 slot 值。
大致流程为:清空 slot -> 获取锁 -> 更新 master -> 释放锁;
特别注意,这里SLOT_LIST.clear()和分布式锁,后面会有思考。
private void updateMasterNodes() {
// 清空slot, 此时每个master的slot都为0
SLOT_LIST.clear();
this.masterNodes.clear();
String nodeLock = Constants.REGISTRY_DOLPHINSCHEDULER_LOCK_MASTERS;
try {
// 获取分布式锁
registryClient.getLock(nodeLock);
Collection<String> currentNodes = registryClient.getMasterNodesDirectly();
List<Server> masterNodes = registryClient.getServerList(NodeType.MASTER);
syncMasterNodes(currentNodes, masterNodes);
} catch (Exception e) {
logger.error("update master nodes error", e);
} finally {
// 释放分布式锁
registryClient.releaseLock(nodeLock);
}
}
private void syncMasterNodes(Collection<String> nodes, List<Server> masterNodes) {
masterLock.lock();
try {
this.masterNodes.addAll(nodes);
this.masterPriorityQueue.clear();
this.masterPriorityQueue.putList(masterNodes);
int index = masterPriorityQueue.getIndex(NetUtils.getHost());
if (index >= 0) {
// 更新master个数和自身slot
MASTER_SIZE = nodes.size();
SLOT_LIST.add(masterPriorityQueue.getIndex(NetUtils.getHost()));
}
logger.info("update master nodes, master size: {}, slot: {}",
MASTER_SIZE, SLOT_LIST.toString()
);
} finally {
masterLock.unlock();
}
}消费 command
消费条件:只要 master_size 不为0即可正常消费command;
消费逻辑:使用 command 的ID % MASTER_SIZE == slot 确定 command 属于哪个 master 。一次只消费一个 command ,高版本已经实现获取多个。
理论上,每个 master 都有各自的 slot ,一个 command 不会被多个 master 扫到,但是假如 command 被多个 master 扫到呢,为了防止重复消费,才有第三步。
特别注意,master 能消费 command 的条件,后面会有思考。
private Command findOneCommand() {
int pageNumber = 0;
Command result = null;
while (Stopper.isRunning()) {
// 只要master_size不为0即可正常消费command
if (ServerNodeManager.MASTER_SIZE == 0) {
return null;
}
List<Command> commandList = processService.findCommandPage(ServerNodeManager.MASTER_SIZE, pageNumber);
if (commandList.size() == 0) {
return null;
}
for (Command command : commandList) {
int slot = ServerNodeManager.getSlot();
// 获取属于自身的command
if (ServerNodeManager.MASTER_SIZE != 0
&& command.getId() % ServerNodeManager.MASTER_SIZE == slot) {
result = command;
break;
}
}
if (result != null) {
logger.info("find command {}, slot:{} :",
result.getId(),
ServerNodeManager.getSlot());
break;
}
pageNumber += 1;
}
return result;
}防止重复消费
如果没有删除到记录,表示已经被消费,抛异常,触发事务回滚。
@Transactional
public ProcessInstance handleCommand(Logger logger, String host, Command command, HashMap<String, ProcessDefinition> processDefinitionCacheMaps
) {
ProcessInstance processInstance = constructProcessInstance(command, host, processDefinitionCacheMaps);
// cannot construct process instance, return null
if (processInstance == null) {
logger.error("scan command, command parameter is error: {}", command);
moveToErrorCommand(command, "process instance is null");
return null;
}
processInstance.setCommandType(command.getCommandType());
processInstance.addHistoryCmd(command.getCommandType());
saveProcessInstance(processInstance);
this.setSubProcessParam(processInstance);
// 删除并校验
this.deleteCommandWithCheck(command.getId());
return processInstance;
}
private void deleteCommandWithCheck(int commandId) {
int delete = this.commandMapper.deleteById(commandId);
// 通过删除 + 事务保证
if (delete != 1) {
throw new ServiceException("delete command fail, id:" + commandId);
}
}思考1
command 为什么会被重复消费?
一旦所有 master 都已启动,且 slot 值都固定, command 是不会被重复消费的,只有当 master 上下线,才有可能被重复消费。
在有 command 的前提下分析:
首先(见第2步骤) master 消费 command 的条件是 MASTER_SIZE != 0,(见第1步骤)当master 发生上下线时,所有其余 master 会通过监听触发 updateMasterNodes() 方法,执行以下2个操作:
1) 将 SLOT_SIZE.clear(),这意味着getSlot()时都返回0。
public static Integer getSlot() {
if (SLOT_LIST.size() > 0) {
return SLOT_LIST.get(0);
}
return 0;
}2)争夺分布式锁,切记这时串行的。也就是没抢到锁的master此时:slot = 0,master_size = 原master个数。此时是可以正常消费command的,且消费的一样。
优化建议
虽然有第三步事务保证 command 不被重复消费,但是还是有优化空间的,尽可能减少重复消费。
1)上下线时,未获取到锁的 master 暂时不工作,只需置MASTER_SIZE = 0。
private void updateMasterNodes() {
SLOT_LIST.clear();
// 设置为0
MASTER_SIZE = 0;
......
}2)上下线时,未获取到锁的 master 保留原 slot,正常工作。移动 SLOT_LIST.clear() 到获取锁后。
private void updateMasterNodes() {
// 删除
// SLOT_LIST.clear();
this.masterNodes.clear();
String nodeLock = Constants.REGISTRY_DOLPHINSCHEDULER_LOCK_MASTERS;
try {
registryClient.getLock(nodeLock);
// 移到到获取锁后
SLOT_LIST.clear();
Collection<String> currentNodes = registryClient.getMasterNodesDirectly();
List<Server> masterNodes = registryClient.getServerList(NodeType.MASTER);
syncMasterNodes(currentNodes, masterNodes);
} catch (Exception e) {
logger.error("update master nodes error", e);
} finally {
registryClient.releaseLock(nodeLock);
}
}2
Kill 执行分析
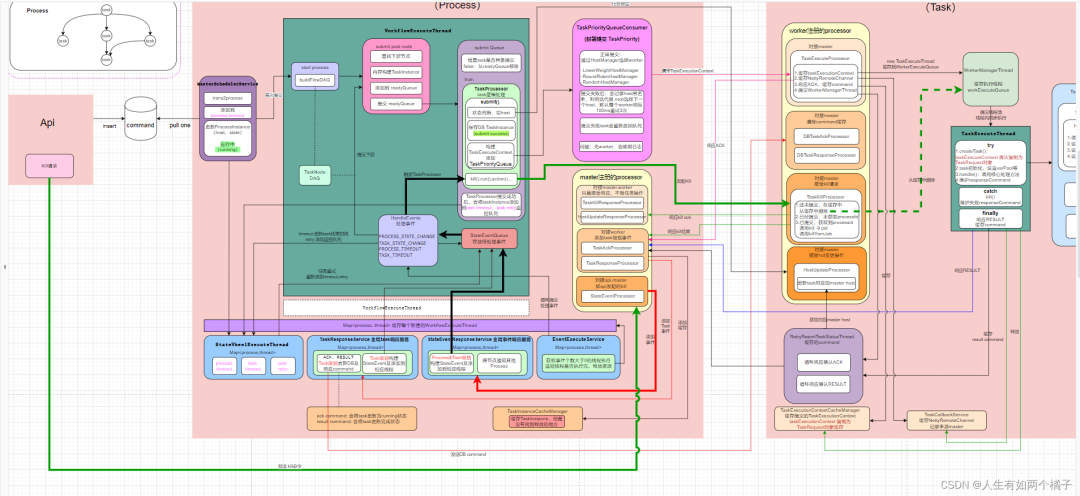
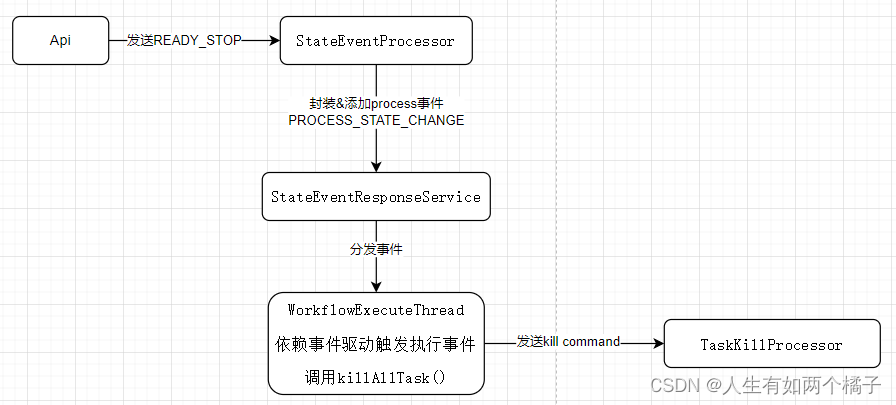
将上图简化如下
API
processInstance 被 master 接管执行后,会在 processInstance 里记录该 master host 值,api 就是通过 host 值找到 master,直接发起 READY_STOP 请求的。没有通过c ommand 解耦。
StateEventProcessor
该 Processor 主要是对接 Api 以及其他 master,不会与 worker 交互。针对 kill,这里负责接受 READY_STOP 请求,并且封装为事件添加到 StateEventResponseService 。
StateEventResponseService
负责分发事件
WorkflowExecuteThread
收到 process kill 事件后,会调用 killAllTasks() ,参照源码,原理是遍历 activeTaskProcessorMaps 获取 taskProcessor(前文讲过每一个已经提交的task对应一个 taskProcessor ),执行 stop 操作,该操作就是向 worker 发起 kill command 。
疑问:taskProcessor 如何知道应该向哪个 worker 发送 command ? (见思考1)
TaskKillProcessor
worker 负责接受 maste r发出的 kill command(见思考2),task kill 后,会向 master 响应 result command ,进而封装分发事件,当 process 检测到有 kill 状态 task 时,更新自己的状态为 kill 。至此整个 kill 结束,页面上 process 为 kill ,执行中 task 也为 kill 。
private void killAllTasks() {
logger.info("process {} 开始kill所有TaskProcessor绑定的task size {}", processInstance.getId(), activeTaskProcessorMaps.size());
// 遍历activeTaskProcessorMaps,依次kill task
for (int taskId : activeTaskProcessorMaps.keySet()) {
TaskInstance taskInstance = processService.findTaskInstanceById(taskId);
if (taskInstance == null || taskInstance.getState().typeIsFinished()) {
continue;
}
ITaskProcessor taskProcessor = activeTaskProcessorMaps.get(taskId);
taskProcessor.action(TaskAction.STOP);
if (taskProcessor.taskState().typeIsFinished()) {
StateEvent stateEvent = new StateEvent();
stateEvent.setType(StateEventType.TASK_STATE_CHANGE);
stateEvent.setProcessInstanceId(this.processInstance.getId());
stateEvent.setTaskInstanceId(taskInstance.getId());
stateEvent.setExecutionStatus(taskProcessor.taskState());
this.addStateEvent(stateEvent);
}
}
}思考1
taskProcessor 如何知道应该向哪个 worker 发送 command?
参照源码 CommonTaskProcessor 的 killTask() ,taskProcessor 会查找 taskInstance 里的 host 值,向 worker 发送command。
而 host 是 worker 接受到 task,并响应回 ack command 添加到 TaskResponseService ,要注意 TaskResponseService 是 master 服务级别的,要串行处理所有 task 的 ack , result command ,所以 host 完全有可能来不及更新就发起 kill,这样就会造成漏杀。
public boolean killTask() {
try {
taskInstance = processService.findTaskInstanceById(taskInstance.getId());
if (taskInstance == null) {
return true;
}
if (taskInstance.getState().typeIsFinished()) {
return true;
}
// 这里只判断taskInstance会漏杀,还应该扫描下ack command
if (StringUtils.isBlank(taskInstance.getHost())) {
taskInstance.setState(ExecutionStatus.KILL);
taskInstance.setEndTime(new Date());
processService.updateTaskInstance(taskInstance);
return true;
}
TaskKillRequestCommand killCommand = new TaskKillRequestCommand();
killCommand.setTaskInstanceId(taskInstance.getId());
ExecutionContext executionContext = new ExecutionContext(killCommand.convert2Command(), ExecutorType.WORKER);
// 查找worker host
Host host = Host.of(taskInstance.getHost());
executionContext.setHost(host);
nettyExecutorManager.executeDirectly(executionContext);
logger.info("send kill command: {}", killCommand);
} catch (ExecuteException e) {
logger.error("kill task error:", e);
return false;
}
logger.info("master kill taskInstance name :{} taskInstance id:{}",
taskInstance.getName(), taskInstance.getId());
return true;
}思考2
worker如何正确kill task。
先分析下,worker接受到task后,会有几种情况,情况不同,kill方式也不同。
1. worker 刚接受 task ,还没添加到 WorkerManagerThread 的 workerExecuteQueue 队列
2. 已添加到 WorkerManagerThread 的 workerExecuteQueue 队列,还没被 ExecutorService 真正提交执行
3. 已被 ExecutorService 真正提交执行,还没有初始化 processId 等信息
4. 被 ExecutorService 真正提交执行且有 processId 等信息
其中1、3过程很短暂,可以忽略,但是真要是发生了,会有漏杀的问题。
核心逻辑在doKill()方法,针对2、4不同的kill方式:
针对2,只要从队列中删除,并且直接响应 result command 即可;
针对4,拿到 processId并调用 kill -9 pid,此时 task 对应的 TaskExecuteThread 依旧在正常执行中,当 task kill 后,例如 shell task 在执行 process.waitFor() 会收到 kill(exitCode=137) , TaskExecuteThread 正常结束,在 finally 中响应 result command ;
private Pair<Boolean, List<String>> doKill(TaskKillRequestCommand killCommand) {
try {
Integer processId = taskExecutionContext.getProcessId();
// 情况2,从队列中删除
if (processId.equals(0)) {
workerManager.killTaskBeforeExecuteByInstanceId(taskInstanceId);
TaskExecutionContextCacheManager.removeByTaskInstanceId(taskInstanceId);
logger.info("the task has not been executed and has been cancelled, task id:{}", taskInstanceId);
return Pair.of(true, appIds);
}
// 情况4,调用kill -9 强杀
String pidsStr = ProcessUtils.getPidsStr(taskExecutionContext.getProcessId());
if (!StringUtils.isEmpty(pidsStr)) {
String cmd = String.format("kill -9 %s", pidsStr);
cmd = OSUtils.getSudoCmd(taskExecutionContext.getTenantCode(), cmd);
logger.info("process id:{}, cmd:{}", taskExecutionContext.getProcessId(), cmd);
OSUtils.exeCmd(cmd);
}
} catch (Exception e) {
processFlag = false;
logger.error("kill task error", e);
}
// 通过日志查找applicationId , kill yarn任务
Pair<Boolean, List<String>> yarnResult = killYarnJob(Host.of(taskExecutionContext.getHost()).getIp(),
taskExecutionContext.getLogPath(),
taskExecutionContext.getExecutePath(),
taskExecutionContext.getTenantCode());
return Pair.of(processFlag && yarnResult.getLeft(), yarnResult.getRight());
}3
PR 福利
前面说的是从 process 到 task ,从 master 到 worker 整个 kill 的全过程,下面分析一种特别的情况。
复现初始条件:一个 process 只有一个 task , task 执行失败,在重试队列等待重试,此时发起 kill 。
分析:
master 接收到 kill 后,正常封装事件,分发事件, WorkflowExecuteThread 会调用 killAllTasks() ,重点来了, killAllTasks 会遍历 activeTaskProcessorMaps ,但是此时 activeTaskProcessorMaps 是空的(因为 task 已经失败,activeTaskProcessorMaps 会移除taskProcessor),也就是不会向 worker 发送 kill command ,也不会有 worker 发回的 result command ,整个 WorkflowExecuteThread 处于静默状态,此时 process 一直处于 READY_STOP 状态,task 处于失败状态。
但是当 task 达到重试条件时,静默状态终于被打破,task 发起重试,最终会添加到 readyToSubmitTaskQueue 并触发提交,正常重试情况是生成新的 taskInstance 实例。
当 processInstance 是 READY_STOP 时,是不会生成新的实例,查看源码 getSubmitTaskState() , taskInstance 的状态是会发生变化的,从之前失败状态 变更为 KILL 状态。
if (processInstanceState == ExecutionStatus.READY_STOP
|| !checkProcessStrategy(taskInstance)) {
state = ExecutionStatus.KILL;
}并且当提交成功后,会添加一个 TASK_STATE_CHANGE 事件,最后更新 processInstance 状态为 STOP 。此时 process 处于 STOP 状态, task 由失败状态变更为 KILL 状态。
现象总结:发起 kill , processInstance 会从 READY_STOP 状态一直等待一个超时间隔时长才会变为 STOP 状态, taskInstance 会从失败状态,等待一个超时间隔时长后变为 kill 状态。
版权声明:本文为优快云博主「人生有如两个橘子」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.youkuaiyun.com/qq_37706484/article/details/126892623
历史文章
Apache DolphinScheduler v2.0.1 Master 和 Worker 执行流程分析系列(二)
Apache DolphinScheduler v2.0.1 Master 和 Worker 执行流程分析系列(一)
公众号回复关键词“ds201”即可获取高清配图。
如果您也想给社区投稿,欢迎联系zenghui@apache.org!
参与贡献
随着国内开源的迅猛崛起,Apache DolphinScheduler 社区迎来蓬勃发展,为了做更好用、易用的调度,真诚欢迎热爱开源的伙伴加入到开源社区中来,为中国开源崛起献上一份自己的力量,让本土开源走向全球。

参与 DolphinScheduler 社区有非常多的参与贡献的方式,包括:

贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/issues/5689
非新手问题列表:https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A%22volunteer+wanted%22
如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/community/development/contribute.html
来吧,DolphinScheduler开源社区需要您的参与,为中国开源崛起添砖加瓦吧,哪怕只是小小的一块瓦,汇聚起来的力量也是巨大的。
参与开源可以近距离与各路高手切磋,迅速提升自己的技能,如果您想参与贡献,我们有个贡献者种子孵化群,可以添加社区小助手微信(Leonard-ds) ,手把手教会您( 贡献者不分水平高低,有问必答,关键是有一颗愿意贡献的心 )。

添加社区小助手微信(Leonard-ds)
添加小助手微信时请说明想参与贡献。
来吧,开源社区非常期待您的参与。
< 🐬🐬 >
更多精彩推荐
☞DolphinScheduler 登陆 AWS AMI 应用市场!
☞DolphinScheduler 机器学习工作流预测今年 FIFA 世界杯冠军大概率是荷兰!
☞手把手教你上手Apache DolphinScheduler机器学习工作流
☞突破单点瓶颈、挑战海量离线任务,Apache Dolphinscheduler在生鲜电商领域的落地实践
☞名额已排到10月 | Apache DolphinScheduler Meetup分享嘉宾继续火热招募中
☞【Meetup讲师】您有一张社区认证讲师证书未领取,点击领取!
☞DolphinScheduler 登上开源热力榜 Top30!云原生推动的开源技术栈大重构正在进行
我知道你在看哟

















 1493
1493

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









