 Windows11下DeepSeek的WSL安装指南
Windows11下DeepSeek的WSL安装指南





前言:
本教程主要是讲windows系统,安装WSL ubuntu系统, 运行DeepSeek过程。
在windows直接安装也是可以的,但是在安装过程中遇到的不兼容问题非常多,配置也比较复杂,已掉坑里多次,所以不建议大家直接在windows上安装,推荐在系统中安装ubuntu,然后再配置环境,运行DeepSeek, 这种方式也可以利用电脑的GPU硬件做加速,很多人是intel办公集成显卡,AMD显卡,有一些显卡是可以实现硬件加速,并不是一定要nvidia显卡。
本次安装使用llama.cpp项目,安装确实稍有点复杂,但是也有很大的优势:
-
高效性:
llama.cpp采用了高效的量化技术,减少了模型的大小和计算需求,从而提高了推理速度。提供量化命令,可以直接把huggingface的模型量化成小模型。 -
轻量化:通过优化算法和减少不必要的代码,
llama.cpp实现了较小的内存占用,使其适用于各种设备。 -
跨平台支持:支持Linux、macOS和Windows等多个操作系统,可以在不同环境中运行。
-
开源性:作为开源项目
llama.cpp吸引很多的开发者参与,迭代速度非常快。 -
灵活性:模块化设计使得开发者可以选择性地使用框架的部分功能,而不必使用整个框架。
-
高性能计算:C++的高效性使得
llama.cpp能够实现高性能计算,适用于需要高吞吐量和低延迟的应用。 -
内存管理:这个项目的最重要特点就是它能够利用显卡和系统内存(RAM)。这意味着它不仅仅依赖显卡的视频内存(VRAM),还可以使用系统的RAM来进行计算,从而更好地管理资源和提高性能。传统的python项目,当使用显卡时,内存有很大空间也无法利用。用cpu时又不能加速。导致只能用nvidia cuda显卡,其他显卡无法利用。英伟达一家独大,股票节节攀升,本项目可以在推理时充分利用机器显卡。
开始安装:
步骤介绍:
安装WSL ubuntu, ubuntu编译环境,安装CUDA,下载并编译项目,下载模型,运行模型一共六步就可以在本地体验DeepSeek R1,下面逐步介绍:
1.安装WSL ubuntu
首先在系统中找到:Microsoft Store, 搜索 ubuntu, 会有多个结果,要选择Ubuntu 22.04.5 版本,可以利用window的硬件加速功能。第一个也可以,版本相同。22.04.5版本比较普遍,基本不会有兼容问题和编译问题。
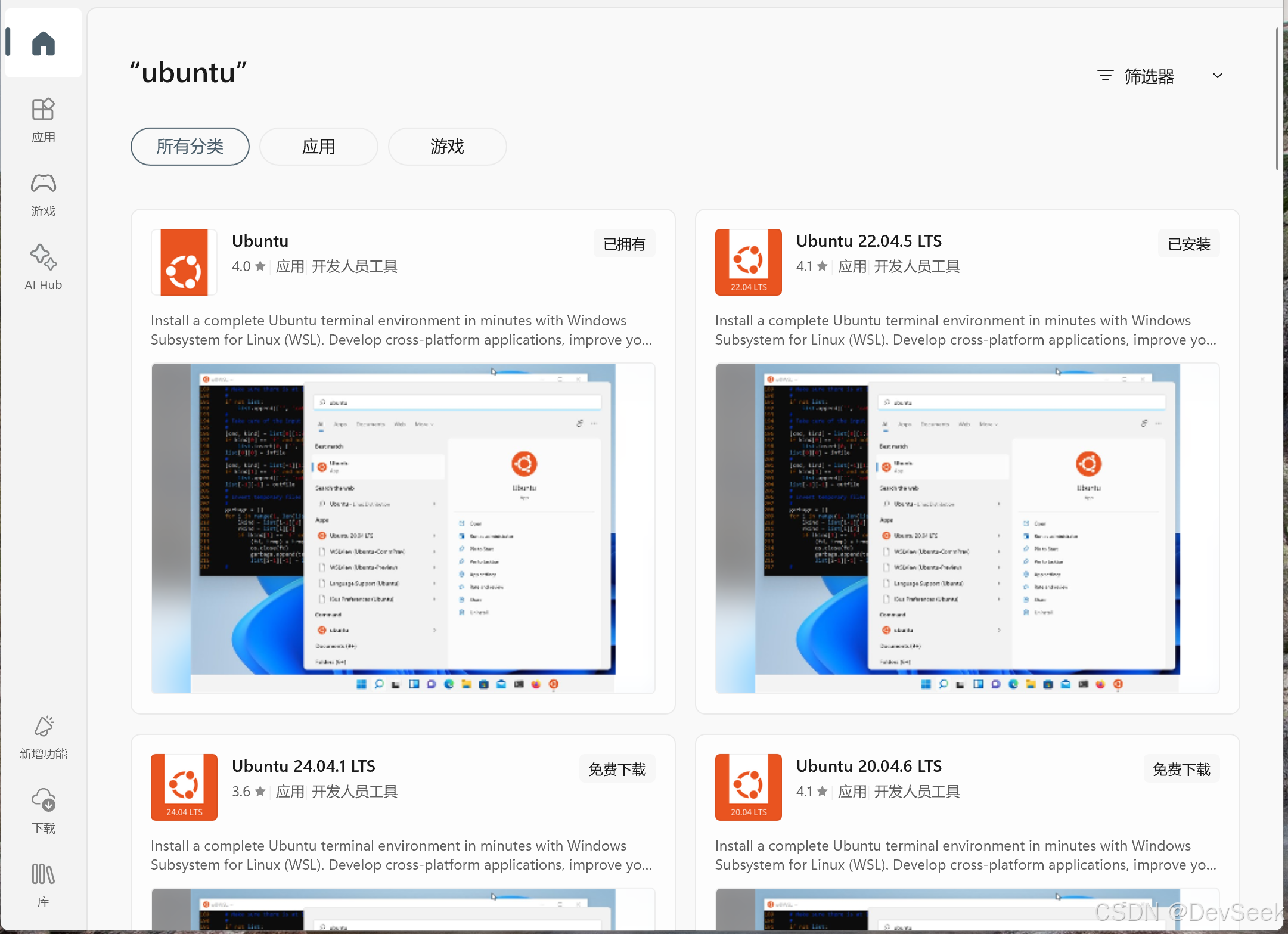
安装成功后要提示设置一个用户名和密码

2.ubuntu编译环境
安装开发相关的编译环境
sudo apt-get update
sudo apt-get install build-essential cmake3.安装CUDA
CUDA Toolkit 12.0 Downloads | NVIDIA Developer
如果是英伟达的显卡点上面的链接,按网站的提示安装,不是nvidia的跳过,保证windows正常安装了显卡驱动即可:

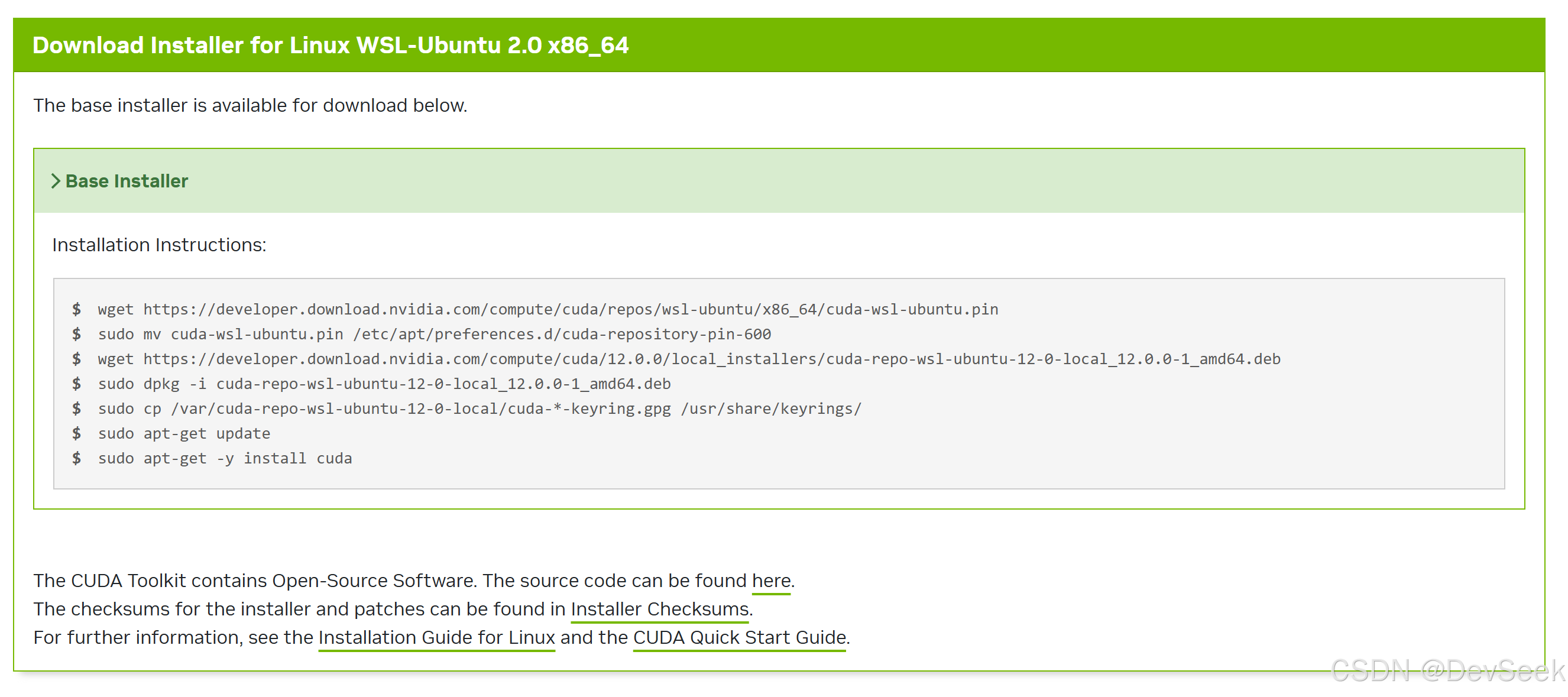
wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-wsl-ubuntu.pin
sudo mv cuda-wsl-ubuntu.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/12.0.0/local_installers/cuda-repo-wsl-ubuntu-12-0-local_12.0.0-1_amd64.deb
sudo dpkg -i cuda-repo-wsl-ubuntu-12-0-local_12.0.0-1_amd64.deb
sudo cp /var/cuda-repo-wsl-ubuntu-12-0-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cuda4.下载并编译项目
在ubuntu命令行执行:
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
项目提供的安装步骤地址:llama.cpp/docs/build.md
如果是CUDA显卡的执行,不是请跳过:
cmake -B build -DGGML_CUDA=ON
cmake --build build --config Release如果是Intel显卡及AMD显卡的参看:llama.cpp/docs/backend/SYCL.md
如果以上都不符合:
cmake -B build
cmake --build build --config Release5.下载模型
huggingface 网站搜索deepseek,找到 GUFF 格式结尾的模型, 是量化后模型
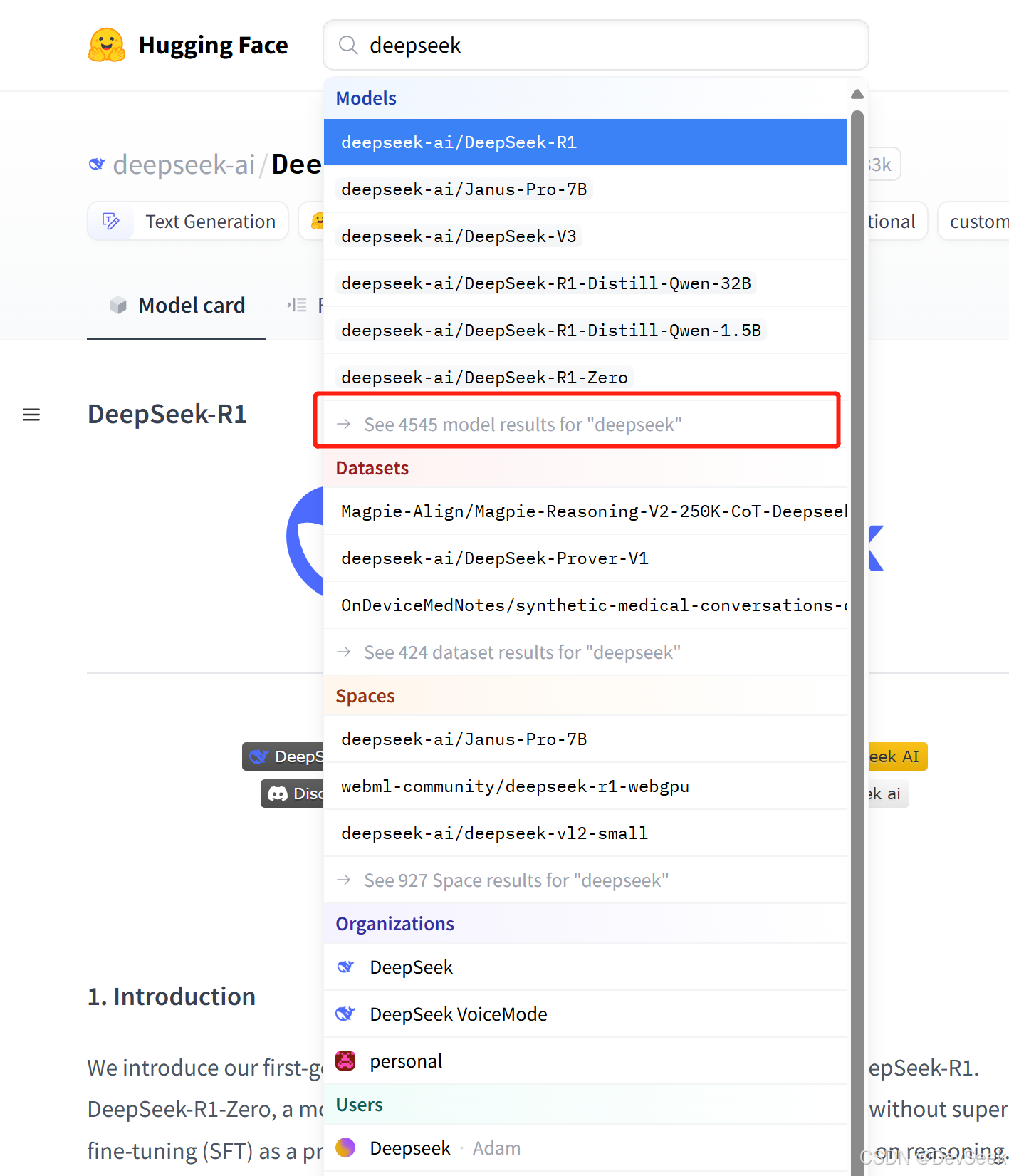
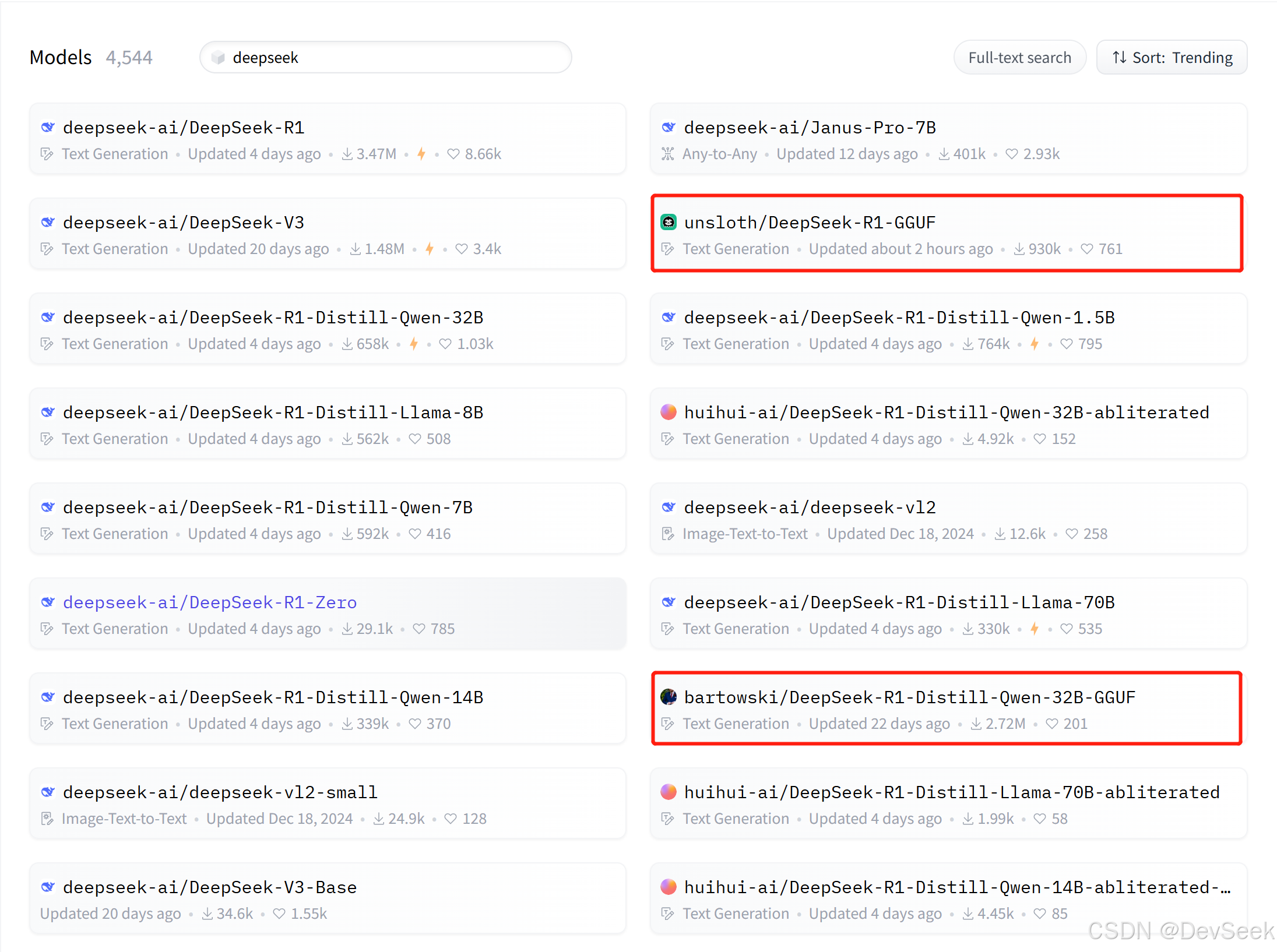
根据各自的机器配置选择模型,机器是否能运行可以参看这篇性能测试:DeepSeek 8B,14B,32B,70B在ubuntu,mac上的性能测试结果
6.运行模型
下载成功后可以任意放置位置,我自己放在 llama.cpp/models
./build/bin/llama-server -m model/DeepSeek-R1-Distill-xxxxxxx.gguf
如果有显卡加速可以增加-ngl 增加数字,设置显卡加速的数据层数,例如:
./build/bin/llama-server -m model/DeepSeek-R1-Distill-xxxxxxx.gguf -ngl 30
ngl后的可以写的数字在执行过程中可以看到30/49, 自己查看显卡的占用情况调整数字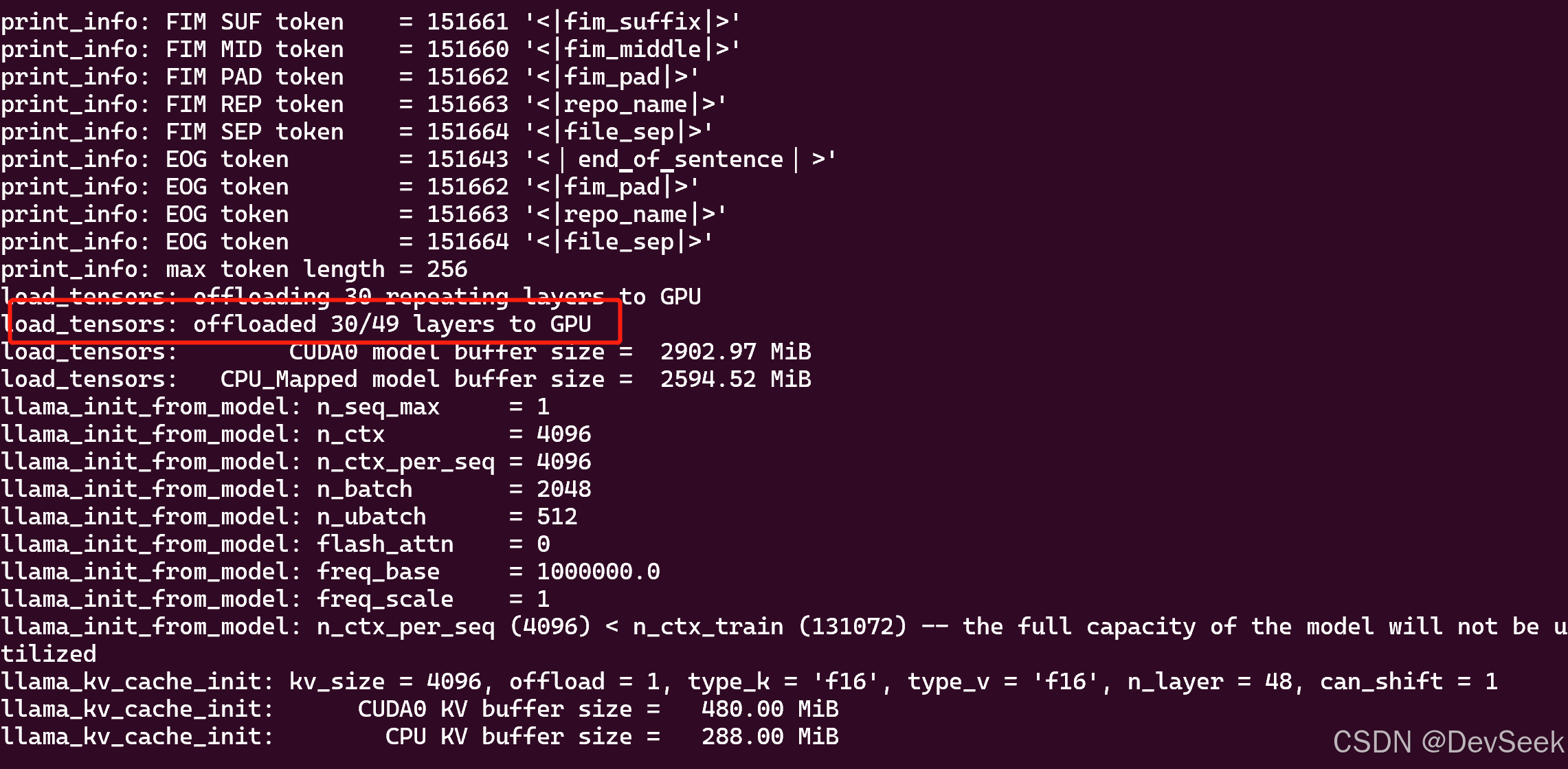
开始体验DeepSeek:
浏览器输入:http://127.0.0.1:8080 ,看到这个界面代表成功: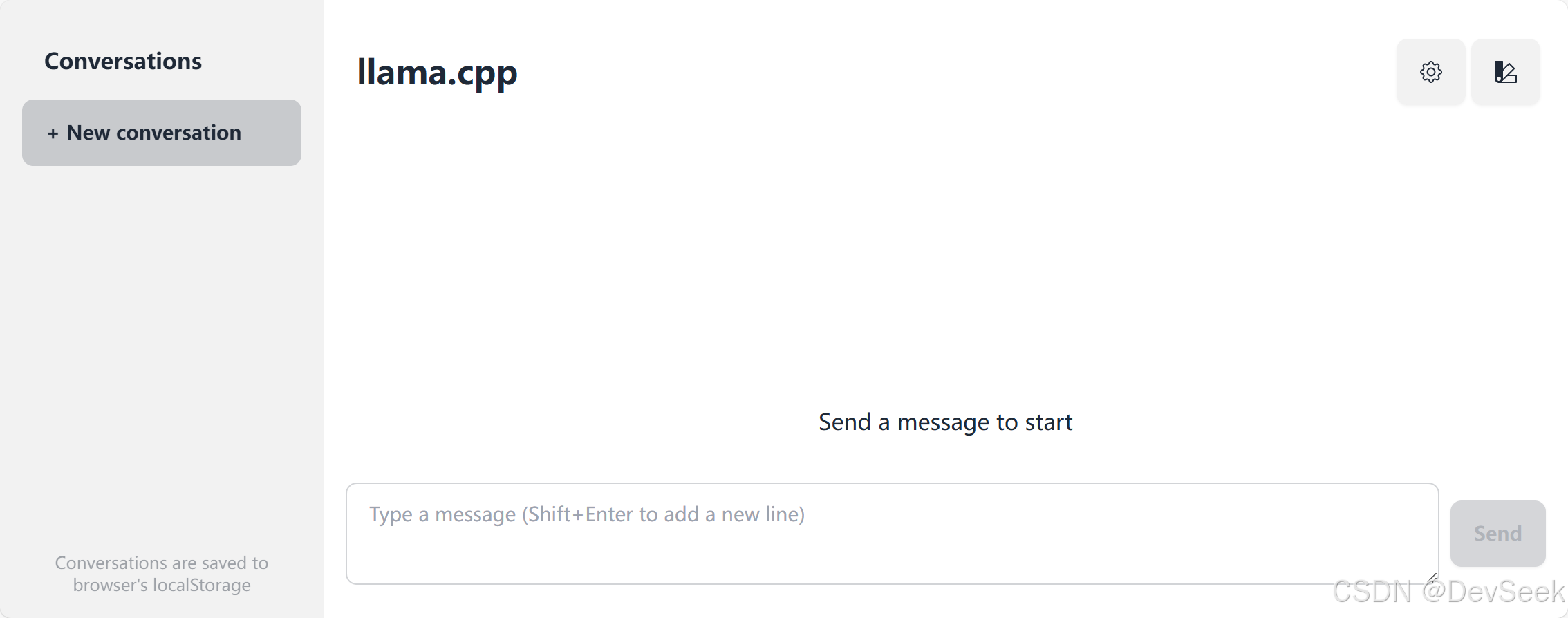
备注:
如果想让别的机器访问需要在启动时增加--host,如果不增加参数只能是本机使用。如果增加后还是无法访问,需要查看WSL的相关防火墙配置
./build/bin/llama-server -m model/DeepSeek-R1-Distill-xxxxxxx.gguf --host 0.0.0.0

















 2187
2187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









