







MySQL面试题 - MySQL中count(*)、count(1)和count(字段名)有什么区别?
回答重点
在MySQL中,count(*)、count(1)和count(字段名)都是用来统计行数的聚合函数,但它们有些许的区别:
功能上:
- count(*)会统计表中所有行的数量,包括nu11值(不会忽略任何一行数据)。由于只是计算行数,不需要对具体的列进行处理,因此性能通常较高。
- count(1)和count(*)几乎没差别,也会统计表中所有行的数量,包括nu11值。
- count(字段名)会统计指定字段不为nu11的行数。这种写法会对指定的字段进行计数,只会统计字段值不为nul1的行。
效率上:
- count(1)和count(*)效率一致,网上其实众说纷纭,实际上当然得看官网怎么说!
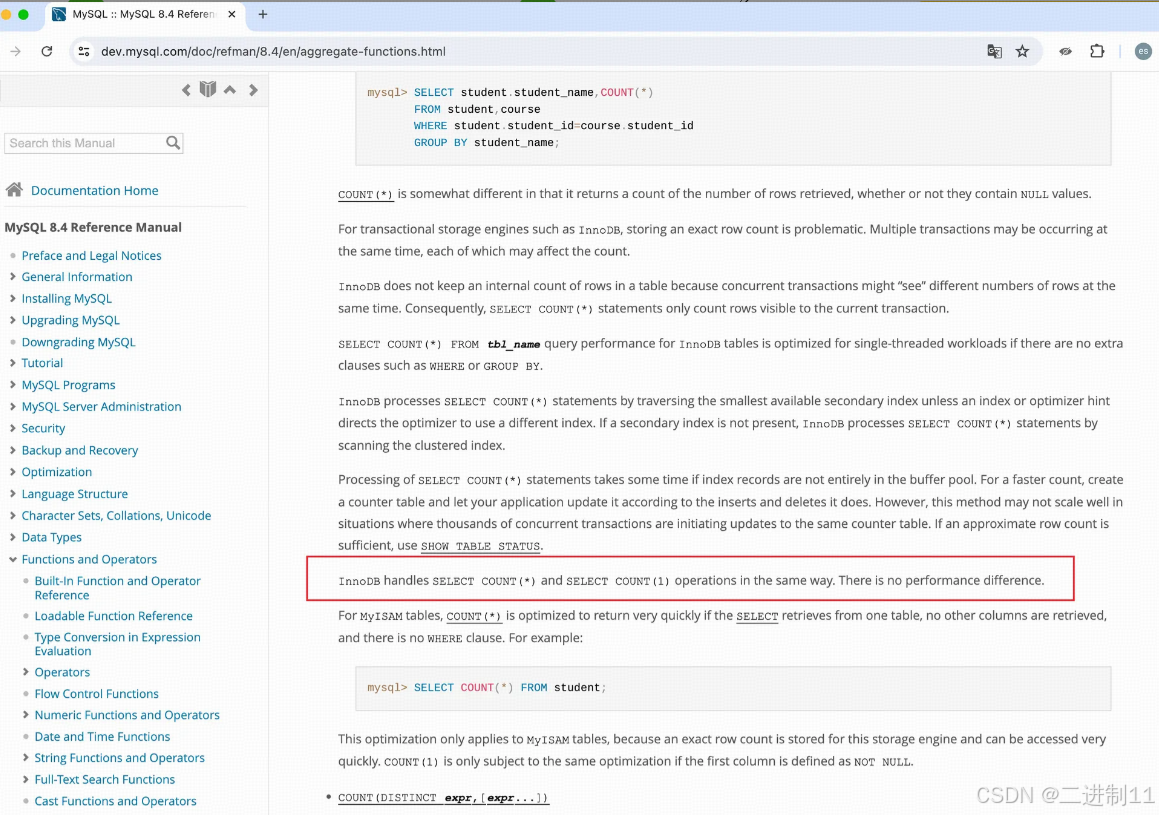
There is no performance difference.没有差异的!
- count(字段)的查询就是全表扫描(如果对应的字段没有索引,如果有索引则用索引),正常情况下它还需要判断字段是否是null值,因此理论上会比count(1)和count(*)慢。
但是如果字段不为null,例如是主键,那么理论上也差不多,而且本质上它们的统计功能不一样,在需要统计null 的时候,只能用count(1)和count(*),不需要统计 null的时候只能用count(字段),所以也不用太纠结性能问题。
引言
在MySQL数据库操作中,COUNT函数是最常用的聚合函数之一,用于统计记录数量。然而,COUNT(*)、COUNT(1)和COUNT(字段名)这三种写法在实际应用中有什么区别呢?本文将深入探讨这三种写法的异同点,并通过流程图帮助理解它们的执行过程。
基本概念
COUNT(*)
SELECT COUNT(*) FROM table_name;
COUNT(*)用于统计表中的记录总数,包括所有列,无论是否包含NULL值。
COUNT(1)
SELECT COUNT(1) FROM table_name;
COUNT(1)中的"1"是一个常量表达式,它不会检查任何具体的列值。
COUNT(字段名)
SELECT COUNT(column_name) FROM table_name;
COUNT(字段名)只统计指定列中非NULL值的数量。
主要区别对比
| 比较项 | COUNT(*) | COUNT(1) | COUNT(字段名) |
|---|---|---|---|
| 统计范围 | 所有记录 | 所有记录 | 仅非NULL记录 |
| 性能 | 优化后最佳 | 等同于COUNT(*) | 需检查字段值 |
| 使用索引情况 | 可能使用 | 可能使用 | 如果字段有索引则使用 |
| 结果是否包含NULL | 包含 | 包含 | 不包含 |
执行流程分析
COUNT(*)和COUNT(1)的执行流程
对于COUNT(*)和COUNT(1),MySQL优化器会尽可能选择最优的执行路径:
- 首先检查是否有可用的索引
- 如果有合适的索引,直接通过索引统计行数(效率最高)
- 如果没有合适索引,则需要进行全表扫描
COUNT(字段名)的执行流程
COUNT(字段名)的执行过程:
- 必须检查每一行的指定字段值
- 只对非NULL值进行计数
- 如果字段上有索引,可能会使用索引优化
- 需要更多的I/O和CPU资源
性能比较
在大多数现代MySQL版本中(5.7及以上):
- COUNT(*)和COUNT(1)的性能几乎相同,优化器会对它们做相同的处理
- COUNT(字段名)通常比前两者慢,特别是当:
- 字段包含很多NULL值时
- 字段没有索引时
- 表数据量很大时
实际测试案例
假设有一个包含100万条记录的表users,其中email字段有约30%的NULL值:
-- 测试1: COUNT(*)
SELECT COUNT(*) FROM users; -- 耗时约0.12秒
-- 测试2: COUNT(1)
SELECT COUNT(1) FROM users; -- 耗时约0.11秒
-- 测试3: COUNT(email)
SELECT COUNT(email) FROM users; -- 耗时约0.35秒
-- 测试4: COUNT(id) id是主键
SELECT COUNT(id) FROM users; -- 耗时约0.13秒
从测试可以看出:
- COUNT(*)和COUNT(1)性能几乎相同
- COUNT(非索引字段)明显更慢
- COUNT(主键字段)性能接近COUNT(*)
使用建议
- 统计所有行数时:优先使用COUNT(*),这是最标准的SQL写法,意图明确
- 统计非NULL值数量时:使用COUNT(字段名)
- 避免使用COUNT(1):虽然性能与COUNT()相当,但语义不如COUNT()明确
- 大表优化:
- 考虑添加合适的索引
- 可以使用近似值(如从INFORMATION_SCHEMA获取)
- 考虑使用缓存计数
特殊情况说明
- MyISAM引擎:对于没有WHERE条件的COUNT(*),MyISAM会直接返回存储的行数,极其快速
- InnoDB引擎:由于MVCC机制,COUNT(*)需要实际计算,无法直接返回准确行数
- 带有WHERE条件:所有COUNT变体都需要评估条件,性能差异会缩小
结论
在MySQL中:
- COUNT(*)和COUNT(1)在性能上基本没有区别,都统计所有行数
- COUNT(字段名)只统计非NULL值,通常性能较差
- 从代码可读性角度,推荐使用COUNT(*)来统计行数
- 特定场景下,选择合适的COUNT变体可以优化查询性能
理解这些差异有助于编写更高效、更清晰的SQL查询语句,特别是在处理大型数据集时。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









