



这个问题困扰了我好久,一直以为是因为我的电脑用户名是中文的原因,因为其他同学都没有这种错。整了好多解决办法都没用,终于给我发现了这个救命文章,特地转载过来希望能解决同样困惑的,如果原作者看到了要求删除拜托请联系我。
附原文链接在windows上运行flume,解决Test Path:路径具有非法字符的问题 - 桐梓坡勒布朗 - 博客园
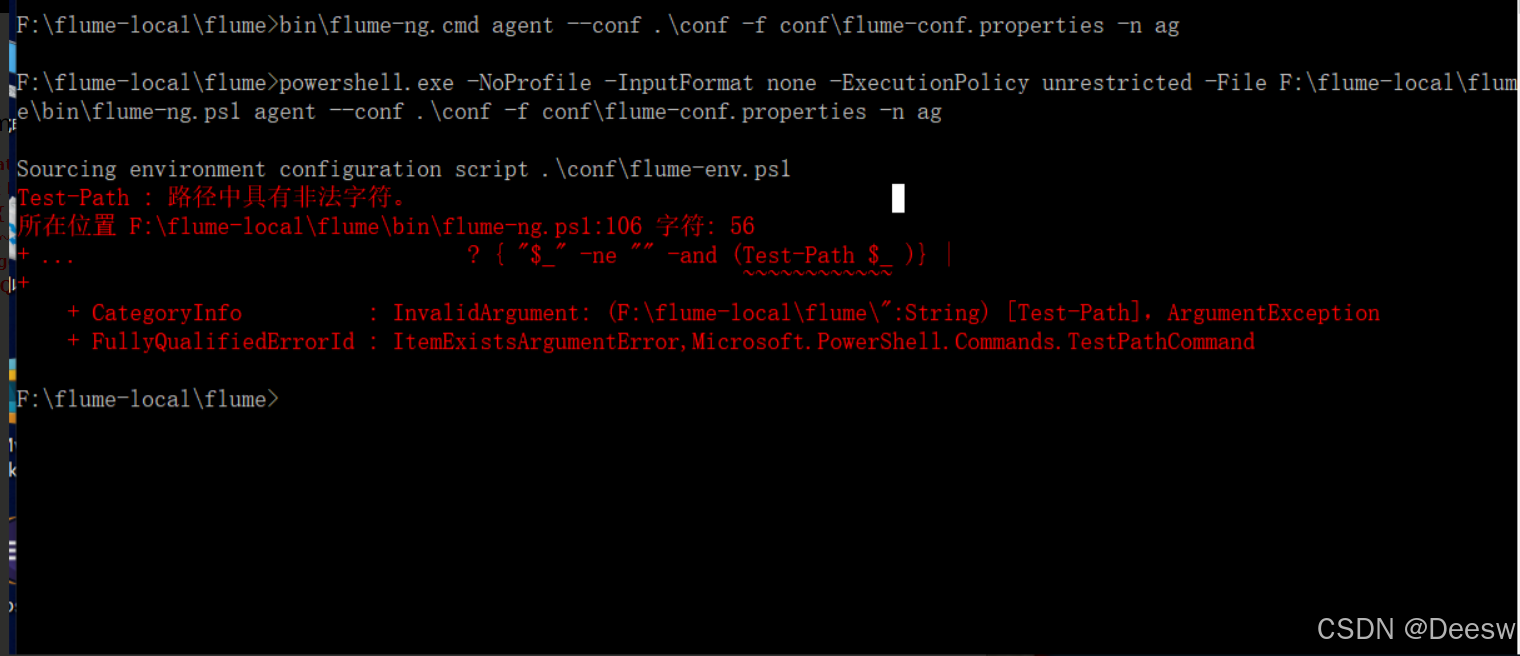
解压安装后出现如下报错(原文章的图)
Test-Path : 路径中具有非法字符。
所在位置 F:\flume-local\flume\bin\flume-ng.ps1:106 字符: 56
+ ... ? { "$_" -ne "" -and (Test-Path $_ )} |
+ ~~~~~~~~~~~~
+ CategoryInfo : InvalidArgument: (F:\flume-local\flume\bin\":String) [Test-Path],ArgumentException
+ FullyQualifiedErrorId : ItemExistsArgumentError,Microsoft.PowerShell.Commands.TestPathCommand
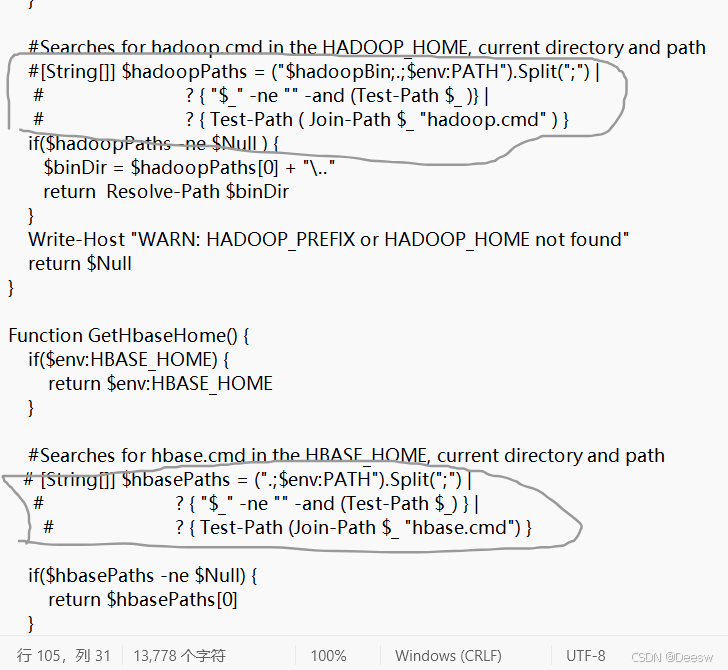
解决方法:找到flume-ng.ps1文件,将报错的106行的getHadoopPath以及后面的两个类似的方法注释,下图圈起来的就是需要注释的

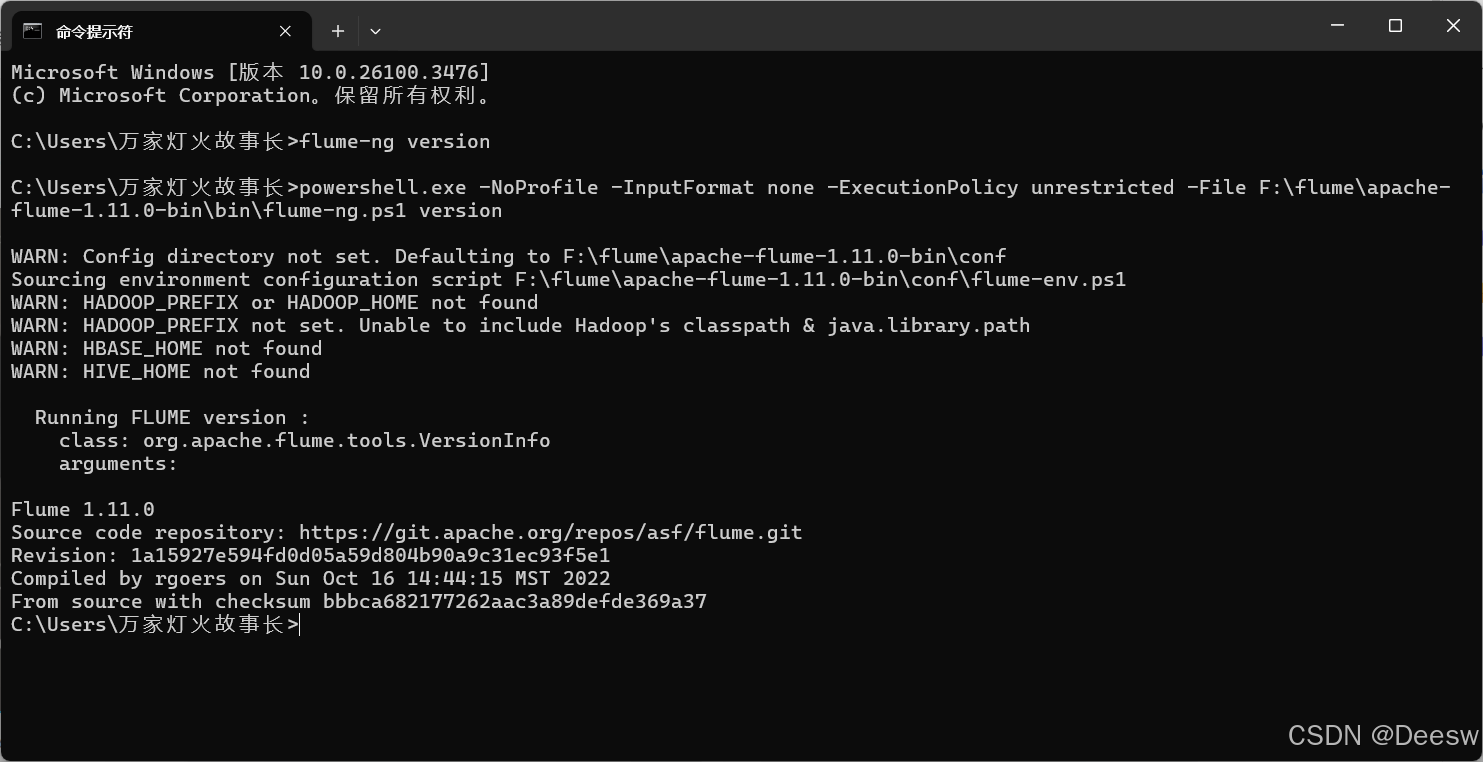
之后就去cmd运行flume-ng version,类似下图就说明成功了

















 1243
1243

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









