




 本文通过Paddle详细介绍了如何构建一个基于13个因素预测波士顿房价的线性回归模型,对比了与numpy编写的优势,并鼓励读者交流指正。
本文通过Paddle详细介绍了如何构建一个基于13个因素预测波士顿房价的线性回归模型,对比了与numpy编写的优势,并鼓励读者交流指正。
写在前面: 我是「虐猫人薛定谔i」,一个不满足于现状,有梦想,有追求的00后
\quad
本博客主要记录和分享自己毕生所学的知识,欢迎关注,第一时间获取更新。
\quad
不忘初心,方得始终。
\quad❤❤❤❤❤❤❤❤❤❤
数据
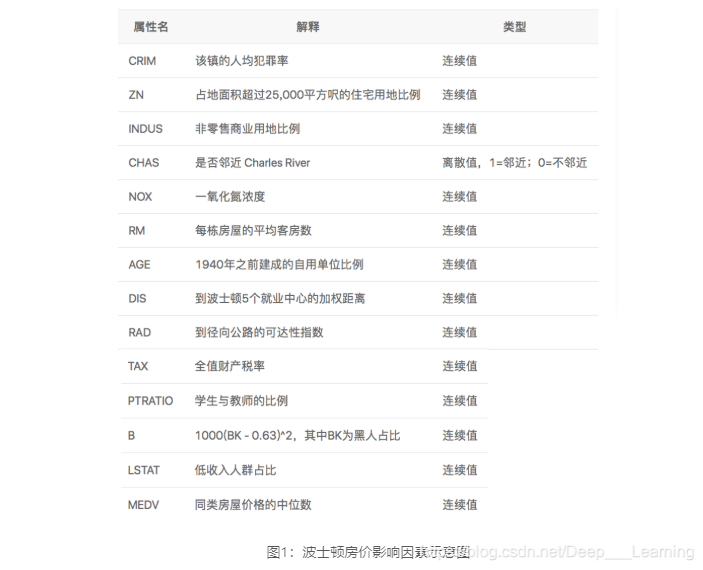
该数据集统计了13种可能影响房价的因素和该类型房屋的均价,我们期望构建一个基于13个因素进行房价预测的模型。
代码
import paddle.fluid as fluid
import paddle.fluid.dygraph as dygraph
from paddle.fluid.dygraph import Linear
import numpy as np
def load_data():
# 从文件导入数据
datafile = './res/housing.data'
data = np.fromfile(datafile, sep=' ')
feature_names = [
'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX',
'PTRATIO', 'B', 'LSTAT', 'MEDV'
]
feature_num = len(feature_names)
data = data.reshape([data.shape[0] // feature_num, feature_num])
ratio = 0.8
offset = int(data.shape[0] * ratio)
training_data = data[:offset]
maximums, minimums, avgs = training_data.max(axis=0), training_data.min(
axis=0), training_data.sum(axis=0) / training_data.shape[0]
global max_values
global min_values
global avg_values
max_values = maximums
min_values = minimums
avg_values = avgs
for i in range(feature_num 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1596
1596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









