







 本文以新手视角介绍如何使用百度的深度学习框架PaddlePaddle进行波士顿房价预测。详细讲解了数据处理、模型设计、训练配置、训练过程以及模型测试。通过线性回归模型,展示了深度学习在房价预测中的应用。
本文以新手视角介绍如何使用百度的深度学习框架PaddlePaddle进行波士顿房价预测。详细讲解了数据处理、模型设计、训练配置、训练过程以及模型测试。通过线性回归模型,展示了深度学习在房价预测中的应用。
首先,本文是一篇纯新手向文章,我自己也只能算是入门,有说错的地方欢迎大家批评讨论
目录
一、人工智能、机器学习、深度学习
近几年人工智能可以说是火的不能再火,大家可能会觉得人工智能=机器学习=深度学习,其实不是这样的,这三个概念是一种包含的层层深入的关系。
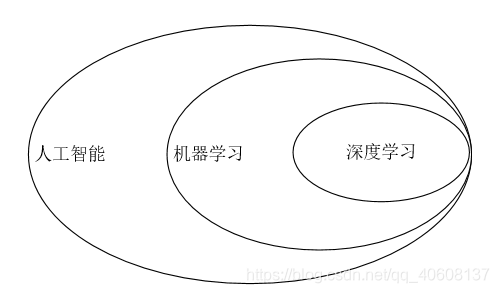
机器学习:专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。 它是人工智能的核心,是使计算机具有智能的根本途径。
深度学习:深度学习是机器学习的分支,是一种以人工神经网络为架构,对数据进行表征学习的算法。
其实这么说大家可能也没听懂,不过这并不是我们今天的主题,大致了解一下就好。
二、PaddlePaddle(飞桨)
大家平常接触到的深度学习框架可能有PyTorch、TensorFlow等等,今天的飞桨是百度研制的一款开源的深度学习框架,个人认为可以满足日常学习,另外,百度还配套有专门的线上实训平台aistudio,提供了丰富的课程以及免费的GPU(百度打钱,hahaha)十分良心。一下是PaddlePaddle的API以及GitHub地址,大家没事可以多看看挺有意思的。
三、波士顿房价预测模型
波士顿房价预测项目是一个经典的入门级项目,我们认为波士顿地区的房价受多种因素影响(人均犯罪率,一氧化氮浓度等等),我们收集了房价随各种因素变化而变化的数据,现在我们需要使用计算机根据这些数据来设计一个房价受各因素影响而变化的模型。对于预测问题,可以根据预测输出的类型是连续的实数值,还是离散的标签,区分为回归任务和分类任务。因为房价是一个连续值,所以房价预测显然是一个回归任务。下面我们尝试用最简单的线性回归模型解决这个问题,并用神经网络来实现这个模型。
构建神经网络的基本步骤如下图所示,我们将会用飞桨框架来搭建这个项目,并对其中的基本概念进行解释
数据处理
数据处理包含五个部分:数据导入、数据形状变换、数据集划分、数据归一化处理和封装load data函数。数据预处理后,才能被模型调用,可以说一个好的数据处理方式是优秀网络搭建的基石。
我们使用的数据的格式是一些506*14的数字
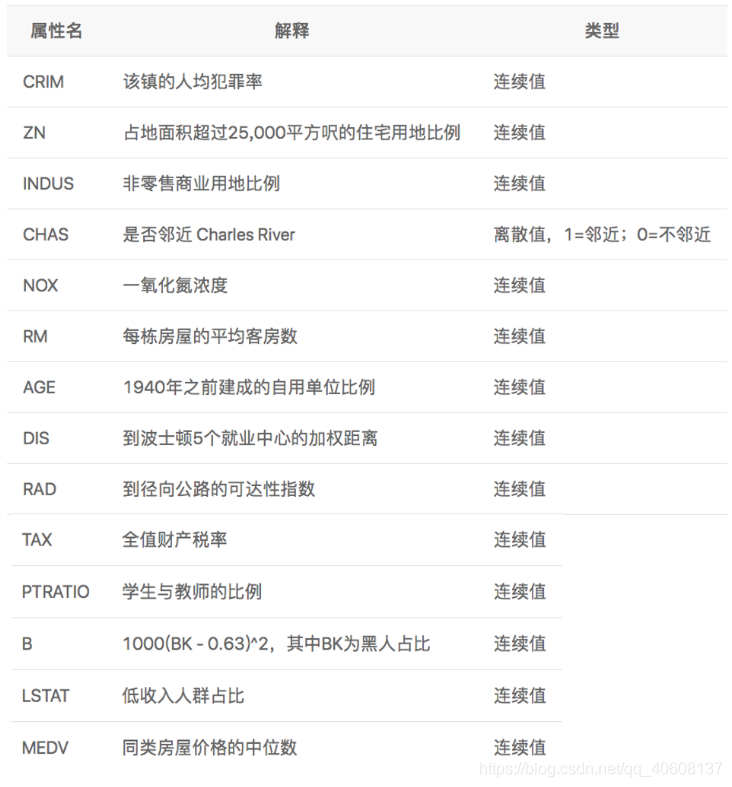
其中前13列代表影响因素,最后一列是房价(影响因素具体如下)
话不多说直接上代码
数据导入
# 导入需要用到的package
# 加载飞桨、Numpy和相关类库
import paddle
import paddle.fluid as fluid
import paddle.fluid.dygraph as dygraph
from paddle.fluid.dygraph import Linear
import numpy as np
import os
import random
# 读入训练数据
datafile = './work/housing.data'
data = np.fromfile(datafile, sep=' ')
print(data)# 在文件里的数据已经转化为Python中的ndarry格式了
[6.320e-03 1.800e+01 2.310e+00 ... 3.969e+02 7.880e+00 1.190e+01]数据形状变换
在原始文件中,我们的数据都是连在一起的是个一维的,我们不能区分出自变量(影响因素x)和因变量(房价y)之间的界限,因此我们需要对这些数据进行形状变化,形成一个2维的矩阵,每行为一个数据样本(14个值),每个数据样本包含13个X(影响房价的特征)和一个Y(该类型房屋的均价)。
# 读入之后的数 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









