




话不多说,先上图:
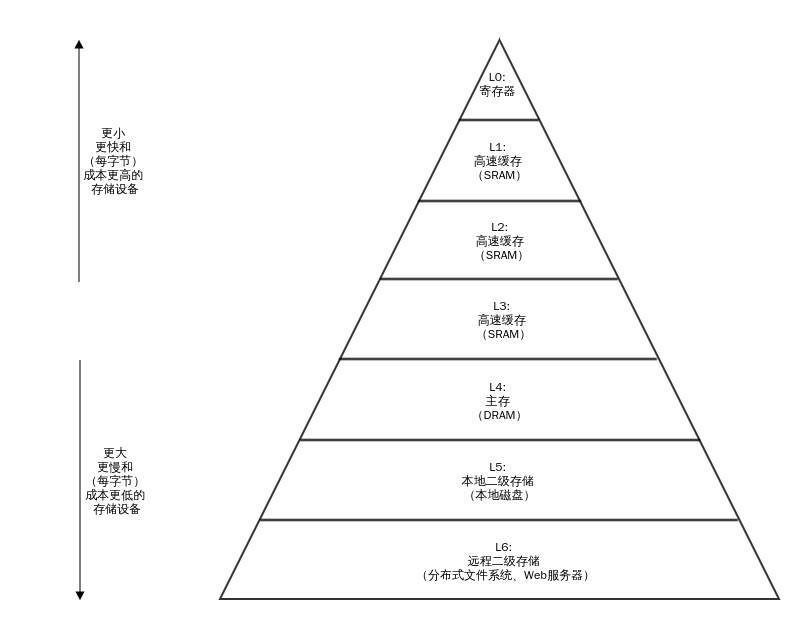
这是《深入理解计算机系统》一书中关于存储器层次结构的配图。现代计算机硬件系统都是多级存储结构,越在塔尖的存储器,CPU读取速度越快,但是相应的造价高昂,而且受限于CPU模块的大小,它们的存储容量也越小。越是塔底的容量越大,造价相对便宜,访问速度相对比较慢。为了综合考虑性价比,于是就有了现代的多级存储结构。
如果让CPU直接从内存或磁盘读取数据,可想而知,CPU要数百次甚至上千次的循环周期才能等到数据从数据总线传送过来。也就是说两者的频率根本就不在一个数量级。硬件工程师们找到的解决方案是CPU缓存技术,所以也就有了那句“架构世界里,缓存为王”。
CPU缓存技术简单说来就是当芯片需要RAM中的数据时,它会自动将一整块连续的内存(通常在64到128字节之间)取出来并置入缓存中。加入下一个数据恰巧在这一块数据中,那么CPU就可以直接从缓存中拿到数据,这比命中RAM快多了。成功地在缓存中找到数据被称为一次命中。如果CPU没有在缓存中找到数据而去访问主存,那么就称之为缓存未命中。此时CPU就会因为缺少数据而无法执行下一条指令,空等N个周期后终于等来数据,于是赶紧接着处理数据。在CPU的时间视角来看,这样的空等是对时间的巨大浪费。如果这样的缓存不命中积累的足够多,就会累积直接影响我们应用程序的运行效率,最直观的就是出现卡顿。
CPU读取数据流程如下:
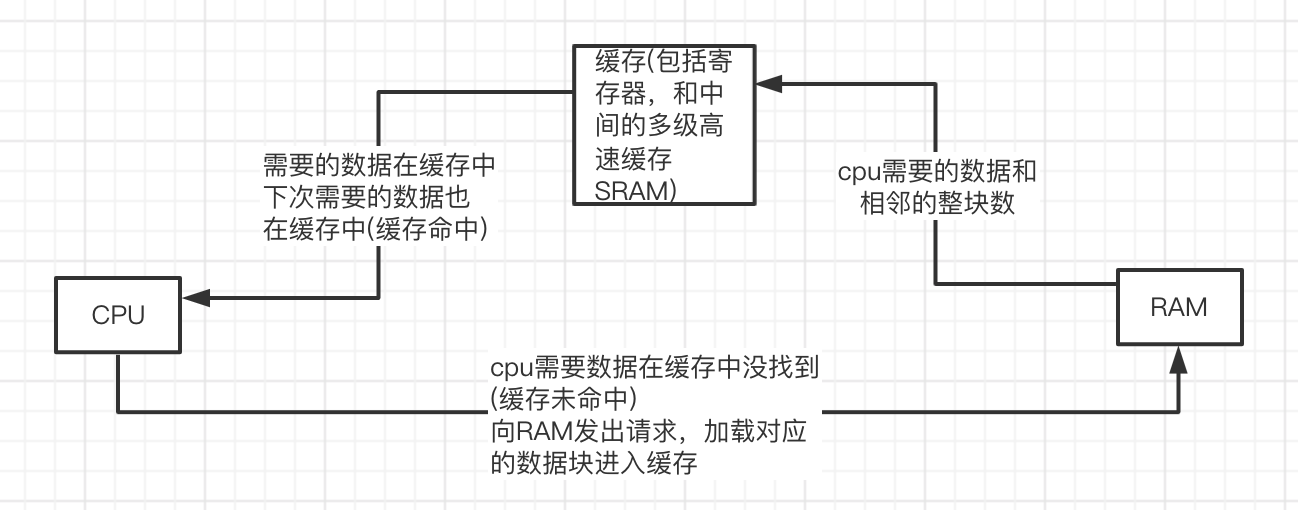
不论CPU何时读取多少内存,它都能整块的获取缓存线。CPU能在缓存线中使用的数据越多,程序就跑的越快。如果我们在程序设计时能将数据结构进行组织,使需要处理的数据对象在内存中两两相邻,这样就可以适应CPU的数据读取方式,进而优化我们程序的运行性能。
不过我们不要过度优化,不要在那些非频繁执行的代码块上浪费时间。要确实性能问题是否是由于缓存未命中引起的。我们可以通过手动在代码段中加入计时器来获取这段代码的执行时间,或者借助一些现成的工具,它能够帮你确知有多少次缓存未命中,并对它们进行定位。有事就算我们定位到了问题,受到精力的限制和我们的奖金绩效考评很难对代码做大的手术,因为它可能正在线上运行,而且有大量的迭代开发任务拖累你,大的修改耗时费力,也会让你承担过多的BUG风险。所以最好的解决方法就是在最初设计的过程中多想想如何让你的数据结构变得对缓存更加友好。
《Game Programming Patterns》一书中举了3个例子来帮我们理解数据局部性的优化。
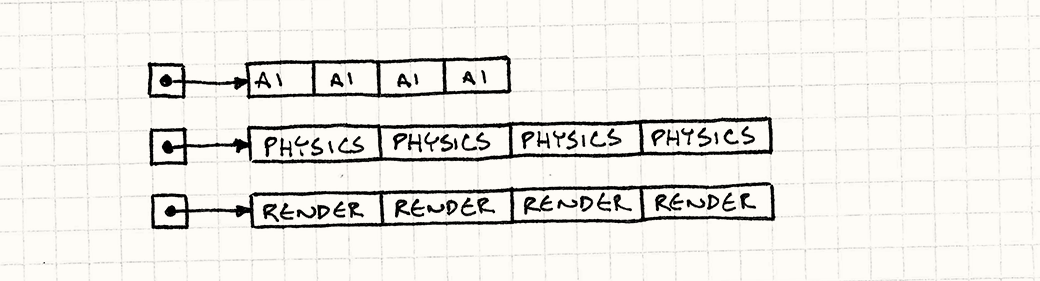
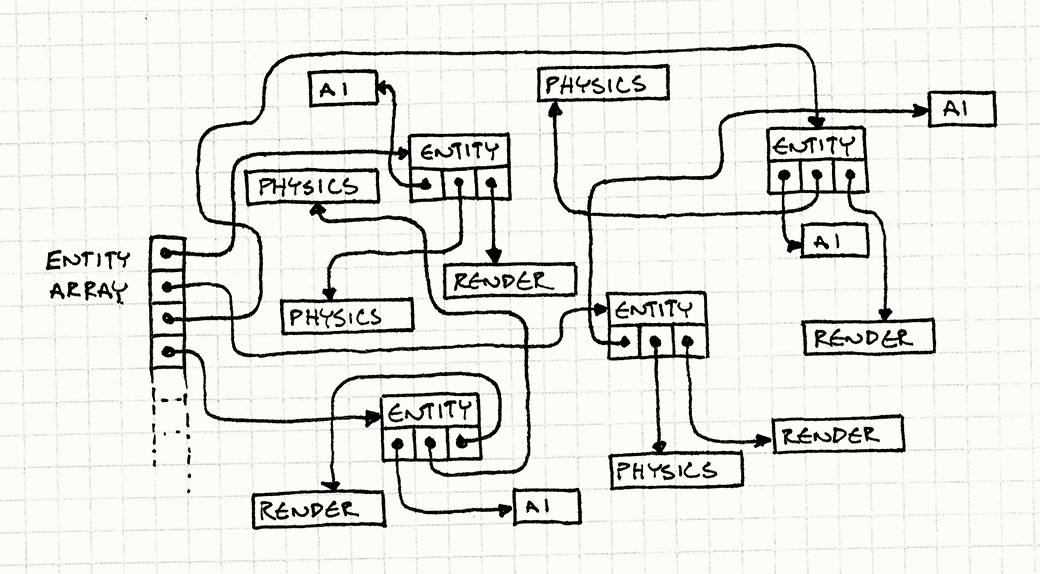
1.把组成游戏实体的组件分类放到数组中,数组中保存组件的实例对象而不是组件的指针。游戏引擎对组件更新时会对不同的组件类型按先后顺序依次更新。这样就可以保证同类组件依次更新时,CPU有更高的缓存命中率。想想如果通过指针来找到实例,在找到里面的组件,而每个实例和它引用的组件会由于内存分配系统的不可控,分配在内存中不连续的位置,这就会造成频繁的缓存未命中,就像是在颠簸内存,术语叫做“内存雕镂”。
两种程序实现方式对内存的访问图下图所示:
2.粒子系统对粒子对象操作时,保证激活的粒子和未激活的粒子在数据存储上进行空间分类分割。这样激活的粒子都在内存中紧挨着,加载到缓存中的粒子对象基本都是需要需要引擎系统更新处理的,这样就会有更高的缓存命中率。如下图所示:

当一个粒子激活时我们就把它换到前面,和激活的粒子紧挨着。让一个粒子回到未激活态时,就把它替换到后面去。
3.热/冷数据进行分割,也就是把经常需要更新的数据(如位置,能力,动画)放到对象中,把不长需要的数据(如:掉落物品数据)通过指针引用存放到另外的对象实例中。这样就能保住对象占用内存更小,缓存中一次性也就能加载更多的对象数据,相应的缓存命中率也会提高。如下图所示:
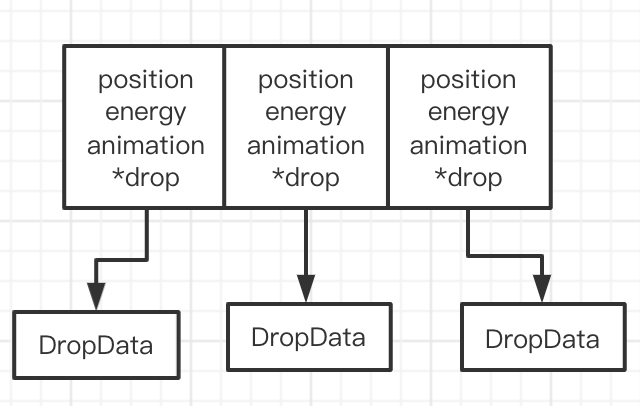
不过具体的开发中很少有这样鲜明的划分。比如某些实例在某个模式下需要这部分数据而在另一个模式下无需这些数据。再比如它们只是在某个等级阶段使用这些数据。
参考:《深入理解计算机系统》第六章-存储器层次结构
Data Locality · Optimization Patterns · Game Programming Patterns

















 14万+
14万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









