 批量统计DOCX表格数
批量统计DOCX表格数





 本文介绍了一种使用Python批量读取指定文件夹内所有DOCX文件并计算每个文件中表格数量的方法,通过自定义函数判断文件类型,实现了对文件后缀的检查,确保了仅对DOCX文件进行处理。
本文介绍了一种使用Python批量读取指定文件夹内所有DOCX文件并计算每个文件中表格数量的方法,通过自定义函数判断文件类型,实现了对文件后缀的检查,确保了仅对DOCX文件进行处理。
最近在做学校的srt,需要数据清洗,清洗后的word里面有6张表格,为了判断word里面是否都有6张表格,写了段python代码来判断。
能实现批量读取某个文件夹内的所有docx文件,然后计算docx里的表格数量。
import os
import docx
# 判断文件后缀
def endWith(s, *endstring):
array = map(s.endswith, endstring)
if True in array:
return True
else:
return False
#待分析文件夹是D:/Files
log_d = 'D:/Files'
logFiles = os.listdir(log_d)
#在D:/Files内遍历文件
for filename in logFiles:
#判断文件是否是docx格式
if endWith(filename, '.docx'):
#建立文件绝对路径
filePath = log_d+'/'+filename
#根据绝对路径读取文件
doc = docx.Document(filePath)
#输出文件名称和表格数量
print(filename + " " + str(len(doc.tables)))
输入结果如下:
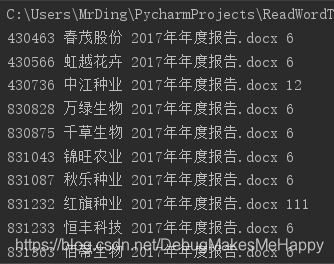

















 1344
1344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









