




 本文详细介绍了如何处理机器学习作业数据,包括数据预处理、缺失值处理、特征提取、数据标准化、训练集划分以及模型训练。使用了标准差标准化方法进行数据规范化,并通过Adagrad算法进行梯度下降训练,最终实现对PM2.5含量的预测。通过训练集和验证集的损失函数比较,评估模型性能。
本文详细介绍了如何处理机器学习作业数据,包括数据预处理、缺失值处理、特征提取、数据标准化、训练集划分以及模型训练。使用了标准差标准化方法进行数据规范化,并通过Adagrad算法进行梯度下降训练,最终实现对PM2.5含量的预测。通过训练集和验证集的损失函数比较,评估模型性能。
Machine Learining —— hw01:Regression
1、hw01作业理解


作业数据给:数据集和测试集
大概内容是数据集中记录了12个月的前20天的24小时的18个数据,测试集是从剩余的数据中再取的
- CSV文件,包括台湾丰原地区240天(12x20)的气象观测资料(取每个月前20天的数据做训练集,每个月后10天数据用作测试,学生不可见)
- 每天的监测时间点为0时、1时、2时、…、23时,共24个小时
- 每天检测的指标包括CO、NO、PM2.5、PM10等气体信息,以及是否降雨、刮风等气象信息,共计18项
- 模型的输入是前9个小时的所有观测数据,即 9 ∗ 18 9*18 9∗18的参数值
- 模型的输出时一个值表示预测的第10个小时的PM2.5含量
使用Regression model
2、数据预处理
训练集中数据排列形式符合人类观看数据的习惯,但并不能直接拿来“喂”给模型进行训练,因此需要对数据进行预处理。
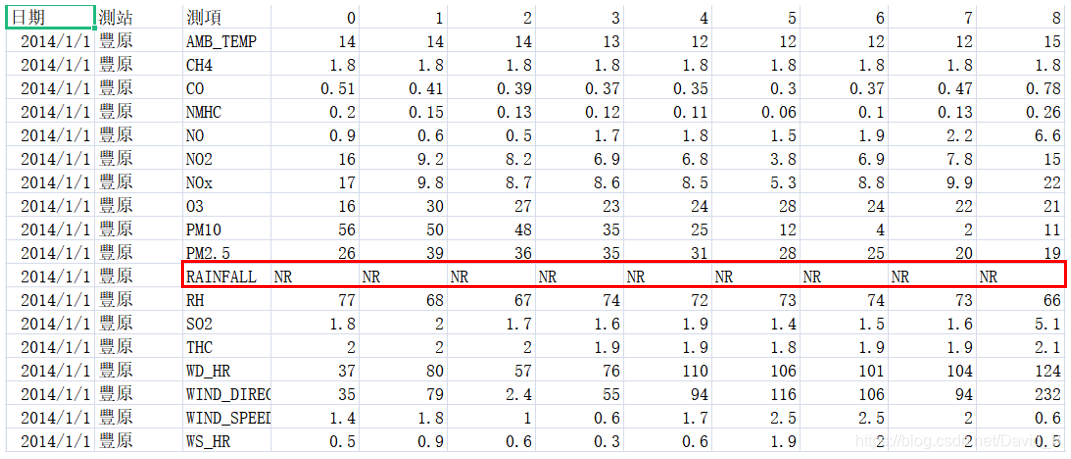
浏览数据可知,在train中存在一定量的空数据NR,且多存在与RAINFALL(降雨)一项。
对于空数据的处理方法:删除和补全。RAINFALL表示对应时间点是否有降雨,有降雨值为1,无降雨值为NR,因此可以采用补全法处理空数据,即将空数据NR全部补为0。
根据作业要求,需要用到连续9个时间点的气象观测数据,来预测第10个时间点的PM2.5含量。
对每一天来说,其包含的信息维度为(18,24)(18项指标,24个时间点)。
参考思路
- 将0-8时的数据截取出来,形成一个维度为(18,9)的数据帧,作为训练数据,将9时的PM2.5含量取出来,作为该训练数据对应的label
- 将1-9时的数据作为训练数据,10时的PM2.5含量作为label
- 以此类推,可将每天的信息分割为15个shape为(18,9)的数据帧和对应的15个label(9-23时)
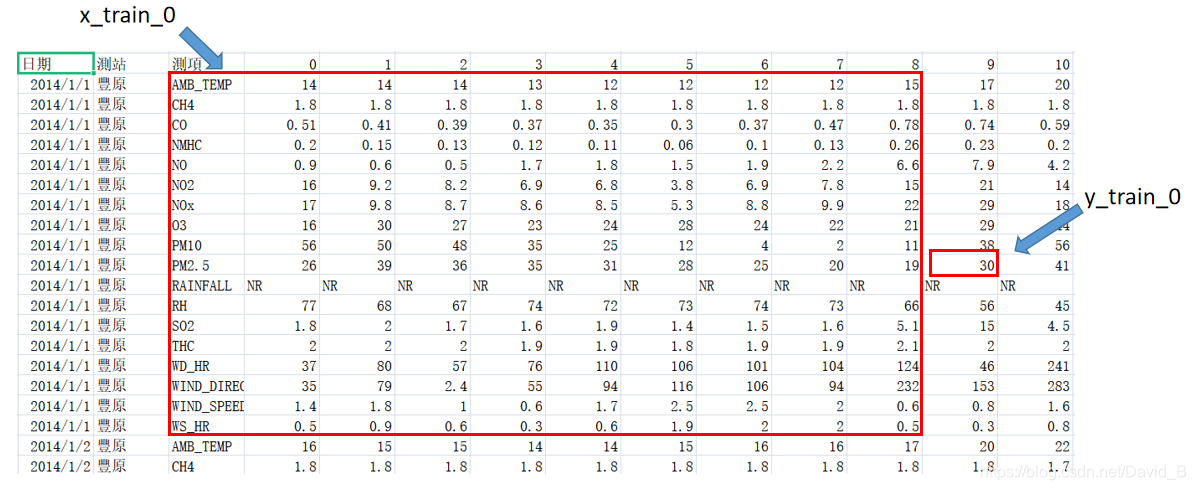
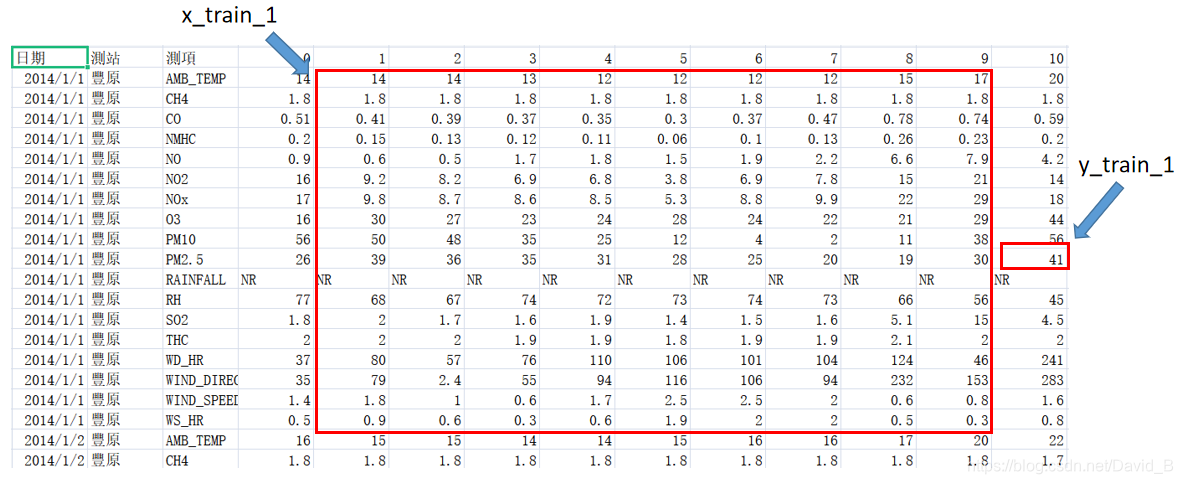
训练集中共包含240天的数据,因此共可获得240x15=3600个数据帧和与之对应的3600个label
python中的数据是通过矩阵来保存的,所以第一步就是删掉不需要的行和列,然后将其保存在矩阵中
#导入必要的包
import pandas as pd
import numpy as np
data = pd.read_csv('./hw1/train.csv', encoding = 'big5') #读取数据保存到data中
data = data.iloc[:, 3:] #保留所以行,从第三列开始往后才保存,去除掉文件中的时间、地点、参数等信息
#print(data)
data[data == 'NR'] = 0 #将所有的NR全部置为0
#print(data)
raw_data = data.to_numpy() #将data的所有数据转换为二维数据(数组)并用raw_data保存
以上步骤完后,已经将csv文件中的数据保存到矩阵中了
将一个月的第一天到第二十天横向排序,取大小为9的窗口,从第一天的0时一直划到第20天的第14时,这样每个月的数据量就会多9个,使整个数据集的利用率得到明显的提升。(参考)link
3、提取特征值
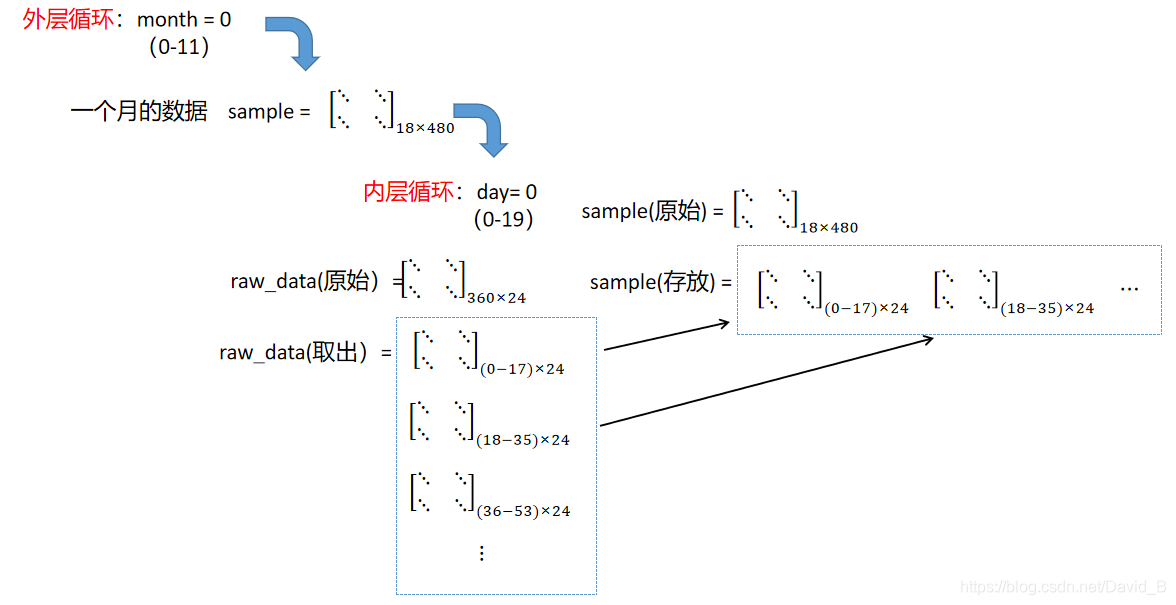
于是我们可以使用以下步骤将每一个月的数据放到一个大行中,如图所示


month_data = {
}#先创建一个空字典month_data来存储数据
for month in range(12): #从0-11共12个月,效果是:{0:“数据”,1:“数据”,...,12:“数据”}
sample = np.empty([18, 480])
#在内存循环开始前先使用empty()创建一个空的数组sample,用来保存一个月的数据(一个月20天24小时,18项参数)
for day in range(20): #day从0-19共20天
sample[:, day * 24: (day + 1)*24] = raw_data[18 * (20 * month + day): 18 * (20 * month + day +1), :]
#sample[]中“,”前表示行的内容全都要;“,”后的是列的内容,按照0-24-48-...这样将24个小时的数据提取出来保存
#raw的行每次取18行(0-18-36-...),列全取。送到sample中(18x480),行全给行,列只给24列,然后列往后增加
month_data[month] = sample
#一个月20天的数据全取完后保存到month_data字典中
将数据放出month_data,代码步骤图:
继续提取数据
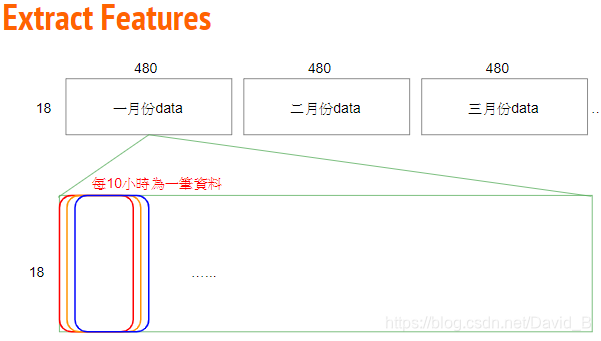
每个月有480小时,每9个小时为一个data,每个月就有471个data,12个月总共12*471笔数据
每小时18个参数
x = np.empty([12 * 471, 18 * 9], dtype = float)
#一共480小时,每9个小时一个数据
#需要9个小时的输入和第10个小时的PM2.5值作为结果
#480-9=471,471*12个数据集按行排列,每一行一个数据,一小时18个参数,每个参数9个小时,一共18*9列
y = np.empty([12 * 471, 1], dtype = float)
#结果是471*12个数据,每个数据一个结果,即第10个小时的PM2.5值
for month in range(12): # month :0-11
for day in range(20): # day: 0-19
for hour in range(24): # hour:0-23
if day == 19 and hour > 14:
#取到raw_data中的最后一(行为18、列为9)的快后,就不可以再取,再取就会超过界限
continue
x[month * 471 + day * 24 + hour, :] = month_data[month][:, day * 24 + hour : day * 24 + hour + 9].reshape(1, -1)
#取对应month:行全取,列取9个,依次进行,最后将整个数据reshape成一行数据,赋给x
y[month * 471 + 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 827
827

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









