




摘要
TPUv4(张量处理单元)是谷歌用于机器学习训练的第三代加速器,采用定制的三维环形互连,部署为 4096 节点的超级计算机。在本文中,我们将介绍设计和运行软件基础设施的经验,这些软件基础设施使 TPUv4 超级计算机能够大规模运行,包括自动故障恢复和硬件恢复功能。
我们采用软件定义网络(SDN)方法来管理 TPUv4 的高带宽芯片间互连(ICI)结构,利用光路交换来动态配置路由,以应对机器、芯片和链路故障。我们的基础设施可检测故障并自动触发重新配置,以最大限度地减少对运行工作负载的干扰,同时启动受影响组件的补救和修复工作流程。类似的技术还可与硬件和软件的维护和升级工作流程对接。我们的动态重新配置方法使我们的 TPUv4 超级计算机实现了 99.98% 的系统可用性,能够从容应对约 1% 的训练任务所遇到的硬件中断。
注:本文为翻译文章,原文为:Resiliency at Scale: Managing Google’sTPUv4 Machine Learning Supercomputer,由于字数过长,文章将分为两期发布,本片涵盖原文1~3节。
1、引言
机器学习(ML)模型的规模和复杂性不断增长[9, 24],这得益于异构超级计算机的大规模计算能力,其中 CPU 负责运行时任务协调和 I/O,而 TPU [18-20] 和 GPU 等加速器则提供模型训练所需的计算性能。扩大超级计算机的节点数能使模型功能更强,因为训练过程可以在批次、张量和流水线维度上有效地并行化[17, 33]。
大规模 ML 超级计算机的硬件/软件生态系统面临两个挑战:第一,有效并行化模型训练工作负载;第二,也是本文的重点--保持计算资源的高可用性,从而为 ML 训练工作提供高产出。近年来,后者变得越来越困难,因为
- 松耦合分布式应用(如 Map-Reduce[12])可以有效地容忍动态变化的资源分配,而 ML 训练作业则不同,它更多地使用静态(编译时)分片策略和帮派式计划执行,要求所有计算资源同时处于健康状态;
- 现代 ML 模型(如大型语言模型 (LLM))需要前所未有的大量硬件(传统计算、加速器、网络和存储)[2],从而将预期 MTBF 降至数小时甚至数分钟[15];
- 在云或共享集群环境中,许多用户都在争夺超级计算机资源的不同子集,这使得能够随着时间的推移重新配置或重新平衡资源分配变得格外重要。
谷歌的 TPUv4 机器学习超级计算基础设施旨在应对这些挑战。它包括以下硬件和软件组件:
- 多个cubes:一个cube是一个硬件单元,包含 64 个 TPU 芯片,以 4x4x4 的三维网格排列;每个超级计算机或 pod 有 64 个cube,共计 4096 个 TPU。
- 专有的芯片间互联(ICI):这是一种高速网络结构,可直接与 TPU 互联,从而实现设备与设备之间的直接通信(即 RDMA),而无需涉及 CPU。
- 光路交换机(OCSes)[25]:用于动态交叉连接(xconnect)不同cube的 ICI,以形成用户要求的环形拓扑结构。
- Borg [31]:集群管理服务,用于受理、调度和管理 TPUv4 作业(及其他作业)。
- Pod 管理器:集群级软件服务,根据 Borg 的调度决定启动 OCS xconnect 设置,从而管理多cube连接。
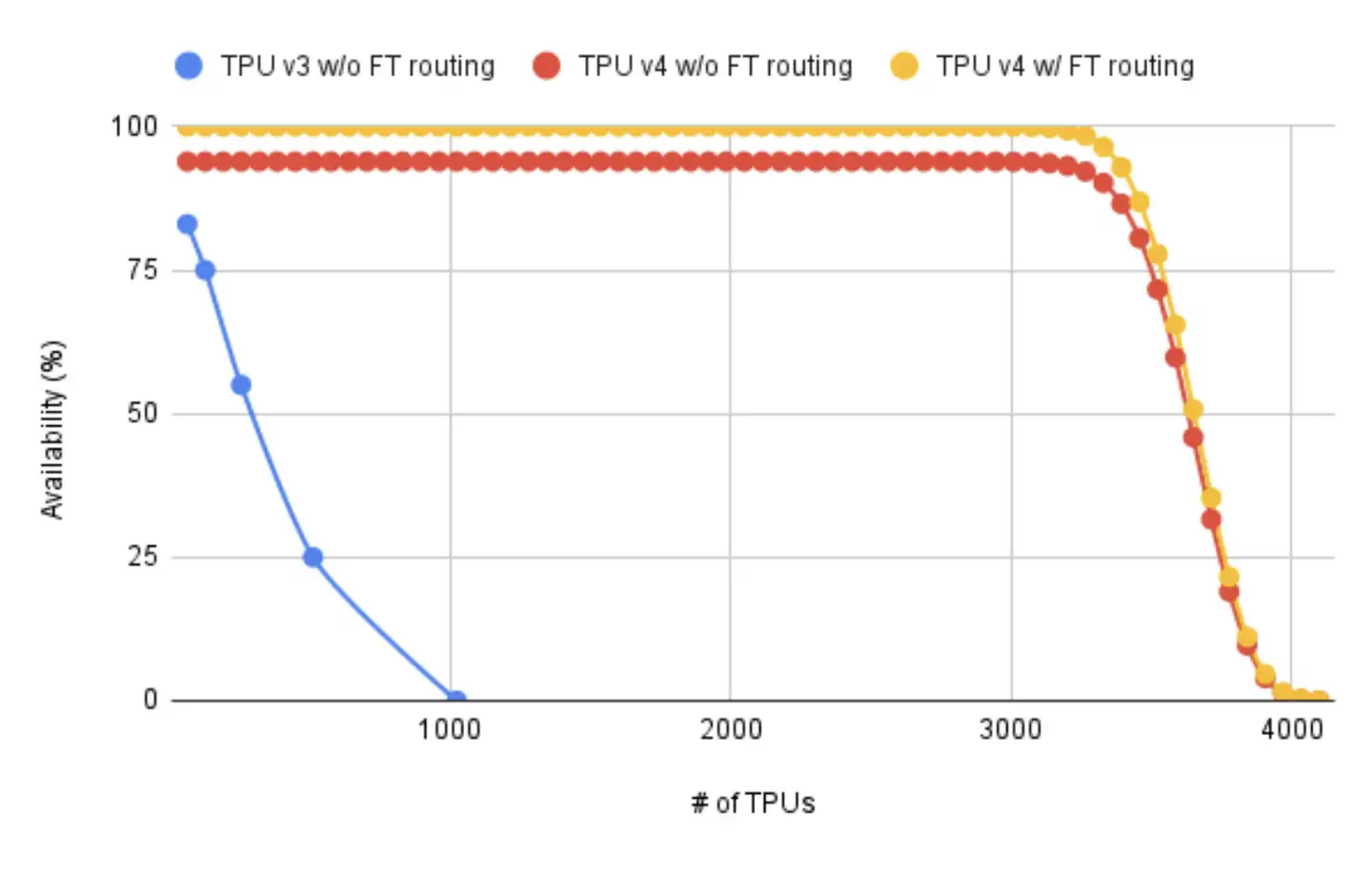
图 1:通过 TPUv'4 cube的可配置性和容错 ICI 路由,作业规模的可用性得到了大规模提高。
- libtpunet:一个软件库,用于为每个 TPUv4 用户作业设置所需的 ICI 网络拓扑。
- healthd:在 pod 中的每台主机上运行的软件守护进程,可持续监控机器硬件健康状况并向集群级软件系统报告。
在 TPUv4 pod 中,硬件和软件是共同设计的。硬件提供了一个可配置的计算基板(4x4x4 cube),带有由 OCS 交换机和片上 ICI 交换机实现的可编程 ICI 协议栈。软件通过配置 OCS 将多个cube组合成更大的 pod 切片,并通过 libtpunet 对 ICI 路由策略进行编程,从而动态管理硬件。当 Borg 将作业调度到不同cube时,连接关系会根据用户要求的环形拓扑重新配置。Pod 管理器按照新的配置进行调整,并监控 ICI 和 OCS 相关的健康状况,一旦发现故障,立即将cube从资源池中排除。
在本文中,我们将介绍如何使我们的 TPUv4 超级计算机自动抵御大规模故障。具体来讲,我们将:
- 解释 TPUv4 超级计算机的可配置系统架构,该架构基于带有 OCS 和 ICI 交换机的可编程 ICI 协议,优化了大规模系统的可用性和弹性;
- 描述调度、配置和优化 TPUv4 资源的软件基础设施,重点介绍我们的可配置性和模块化设计原则;
- 概述我们对加速器侧多跳 RDMA 路由的优化策略,以便在规则和扭曲环形拓扑上进行弹性集体操作;以及
- 分享我们迄今为止在生产中运行 TPUv4 超级计算机的经验。
2、可重构的 ML 超级计算机系统架构
TPUv4 可重构超级计算机是专为可扩展性、可用性、弹性和成本而设计的[18]。它的核心是一个可重新配置的 ICI 结构拓扑,连接不同的 TPUv4 芯片,每个 pod 都有一组可编程的 OCS。如果没有 TPUv4 基于 OCS 的可重构性,随着计算资源规模的扩大,作业可用性会迅速下降。图 1 利用已部署的 TPUv3 静态 pod 和 TPUv4 可重构 pod 的测量数据显示了这种效果。
对于像 TPUv3 [19]这样计算资源静态互连的传统超级计算机,当所需计算资源增加到 1024 个芯片时,作业的整体可用性会急剧下降。这是因为在静态 pod 中,一组连续节点中的所有资源必须同时处于健康状态,才能分配给用户,而随着系统规模的扩大,这种可能性越来越小。利用 TPUv4 的cube级可配置性,可用性可保持在 94% 左右的高水平,相当于约 50 个cube或 3200 个 TPUv4 芯片。
之后可用性下降的原因是不同cube之间偶尔会出现机器故障和 ICI 链路故障。正如我们将在第 4 节中展示的那样,利用容错路由来容忍偶尔发生的 OCS 故障或维护事件,可将可用性进一步提高到 99.98%,因为即使在这些罕见的事件中,用户仍可访问各个cube。
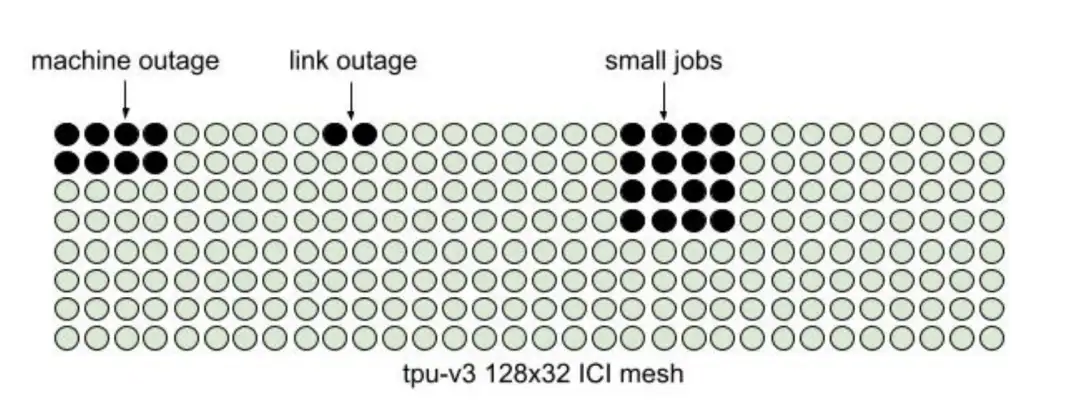
图 2:静态 pod 面临资源碎片问题。
2.1 静态 pod 架构的经验教训
在 TPUv4 ML 超级计算机之前,最先进的是 TPUv2 和 TPUv3 静态 pod [19]--“静态 ”是因为它们具有不可重新配置的固定 ICI 网格。TPUv2 pod 有 256 个 TPU,连接在一个 16x16 ICI 环上,而 TPVv3 有 1024 个 TPU,连接在一个 32x32 环上。TP
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 17万+
17万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











