 TPUv4超级计算机管理
TPUv4超级计算机管理





本文为翻译文章,原文为:
Resiliency at Scale: Managing Google’sTPUv4 Machine Learning Supercomputer。
由于字数过长,文章分为两期发布,本片涵盖原文后半部分4~9节,前三章节请参考文章:规模弹性:管理谷歌的TPUv4机器学习超级计算机
4、ICI 路由
我们在高带宽 ICI 链路上使用多跳数据包路由,以提供快速的 TPU RDMA 和集合。ICI 路由允许在 pod 中任意一对 TPU 之间发送 RDMA 数据包,并能绕过某些 ICI 故障。libtpunet 会在作业启动时对 ICI 转发表进行一次编程,并在作业生命周期内保持不变。每个源-目的配对会沿着 ICI 拓扑中的一条预定路径发送数据包。
这种方法虽然简单,但足以在 ML 模型并行分解过程中出现的典型集体通信模式(如all-gather, reduce-scatter, all-reduce, all-to-all)上实现高性能[33]。
在本节描述的两种情况下,libtpunet 必须在多个候选路径中谨慎地选择一条路径,以满足 ICI 转发表的约束条件:平局破译和容错 wild-first路由。我们使用整数线性规划方法进行离线路径选择,并将优化结果缓存起来。这样,libtpunet 就能在 ICI 网络设置过程中快速加载预先计算出的解决方案。
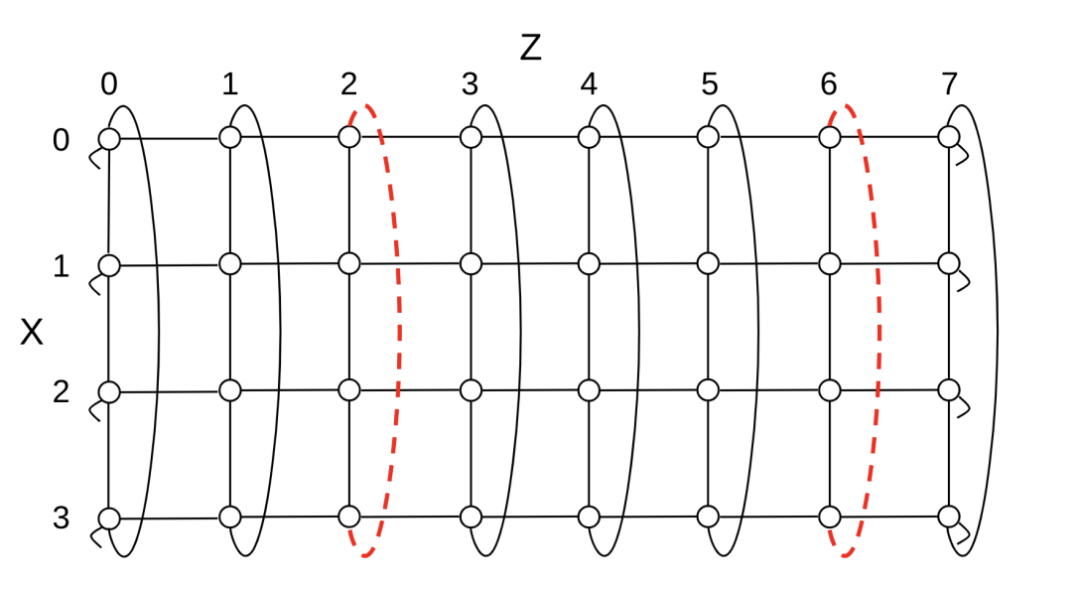
图 10:沿 4x4x8 环形的 X 维不可用 OCS 影响 ICI 链路的示例。不可用的 OCS 导致环的一个 XZ 平面上有两个 X 链路不可用,其他 XZ 平面则不受影响。不可用链接用红色虚线标出。OCS 的连通性产生了周期性故障模式,即沿 Z 每 4 跳重复出现不可用链接。
4.1 无故障路由
为常规环形拓扑配置时,ICI 使用维序路由(DOR)[11]:所有数据包按照环形中从源点到目的地的最短路径,以固定顺序(如先 X 后 Y 再 Z)一次路由一个维度。如 [8] 所述,选择的维度顺序是环中较长的维度先路由。DOR 足以平衡 ML 作业常见流量模式的负载。只需两个虚拟通道[10],它就能实现无死锁,因此实施成本很低。
当数据包需要在一个维度上走完全部路程时,就会出现一个复杂问题,因为在这种情况下,有两条最短路径可供选择。例如,在一个 8x8x8 的环中,将一个数据包从源点(x = 1,y = 0,z = 0)路由到目的地(x = 5,y = 0,z = 0),在 X + 或 X - 方向上可以走 4 跳。
我们通过算法来处理这种平局的情况:当相关源节点坐标沿该维度为偶数时,数据包会沿正向移动,否则会沿负向移动。在我们的例子中,源节点(x = 1,y = 0,z = 0)的 X 坐标为奇数,因此断线选择 X -。这种方案可以平衡常见的全对全流量模式的负载。
扭转环中的路由也使用 DOR,并通过两个虚拟通道实现无死锁。不过,在扭曲环中打破平局更为复杂,因为其维度不像常规环那样可分离:图 9 使用两个维度进行了简单说明。我们决定将处理扭曲环形中的平分问题纳入一个更通用的整数线性编程框架,该框架还能处理容错路由(第 4.3 节)。这样就无需在这种情况下开发明确的平局打破算法。
4
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1305
1305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











