



Datawhale热点
最新进展:DeepSeek,来源:新智元
就在今天凌晨,新版DeepSeek-R1正式开源了!
DeepSeek-R1-0528模型权重已上传到HuggingFace,不过模型卡暂未更新。
项目地址:https://huggingface.co/deepseek-ai/DeepSeek-R1-0528/tree/main
时隔4个月,DeepSeek-R1完成了超进化,编码能力强到离谱,而且思考时间更长了。
据称,新模型基于DeepSeek-V3-0324训练(参数为660B)。

经典物理模拟测试中,DeepSeek-R1新旧版本的对比
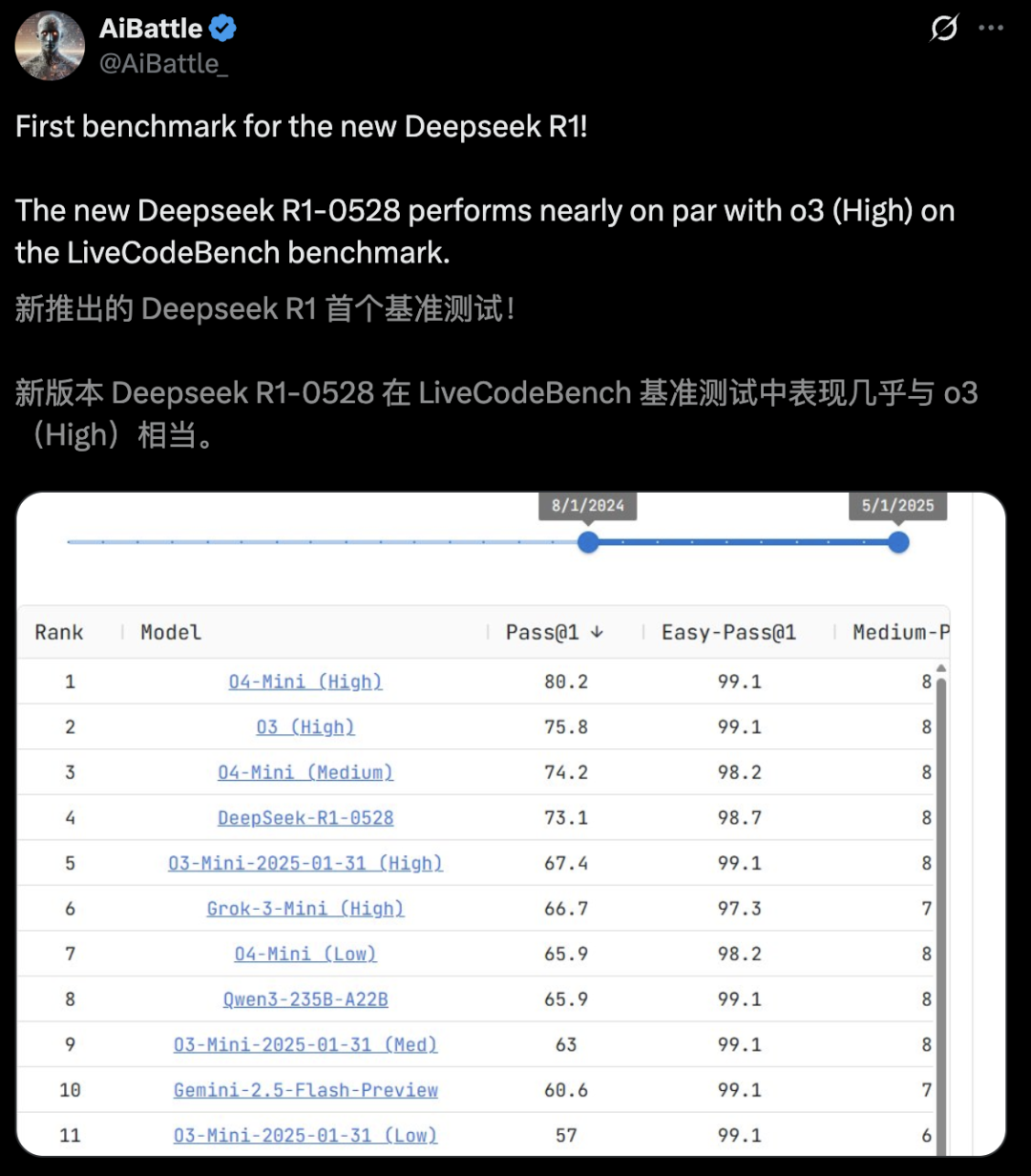
在LiveCodeBench基准上,DeepSeek-R1-0528性能几乎与o3-mini(High)和o4-mini(Medium)实力相当,一举超越了Gemini 2.5 Flash。
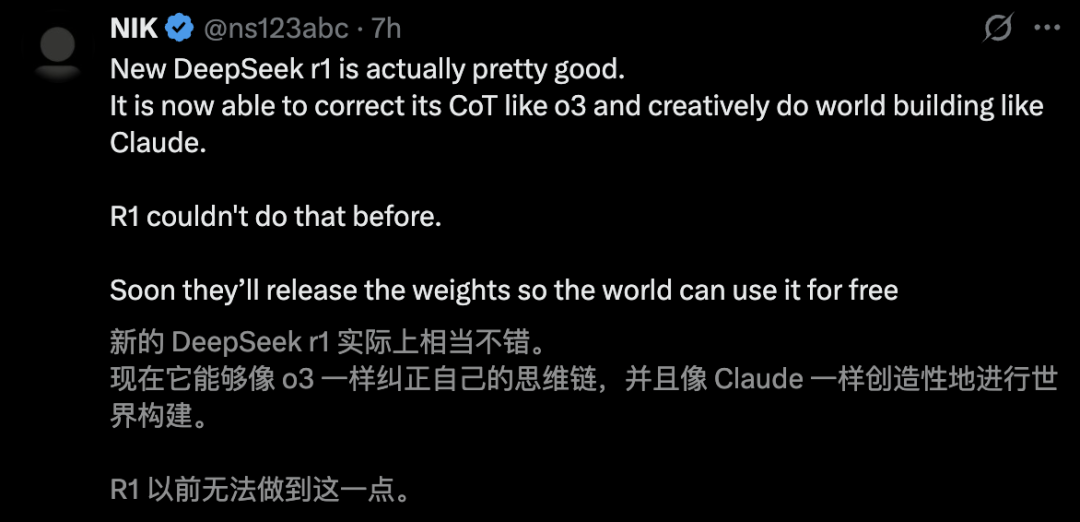
有网友称赞,DeepSeek-R1能够像o3一样纠正思维链,并且像Claude一样创造性进行世界构建。
可以说,这是属于开源模型的巨大胜利!
01
不用R2,直接对标SOTA
此次,DeepSeek-R1-0528更新核心亮点,网友做了一个浓缩版的总结:
能像谷歌模型一样深度推理
文本生成优化:更自然,格式更佳
独特的推理风格:不仅快,而且更缜密
支持长时思考:单任务处理时长可达30-60分钟

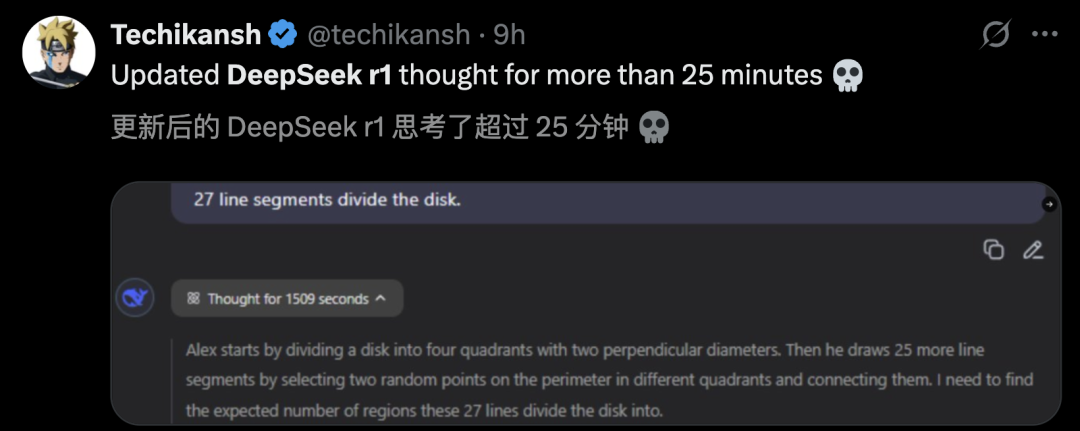
思考时间更长,成为了全网讨论最多的一点。有网友实测后,R1思考时长超过了25分钟。
另外,这似乎是唯一一个能持续正确做对「9.9 - 9.11是多少」的模型。
1. 编程能力强到爆
网友实测显示,新版DeepSeek-R1在编程方面简直不可思议!
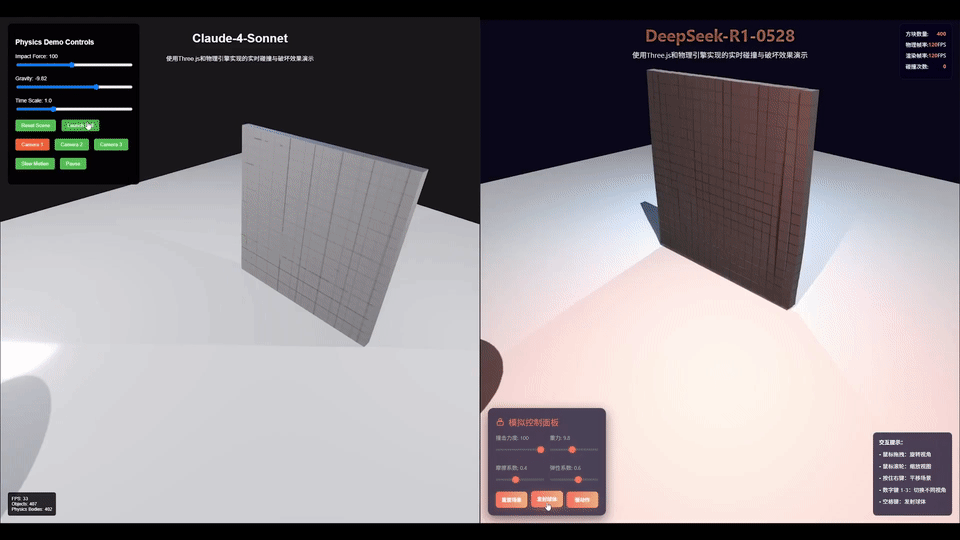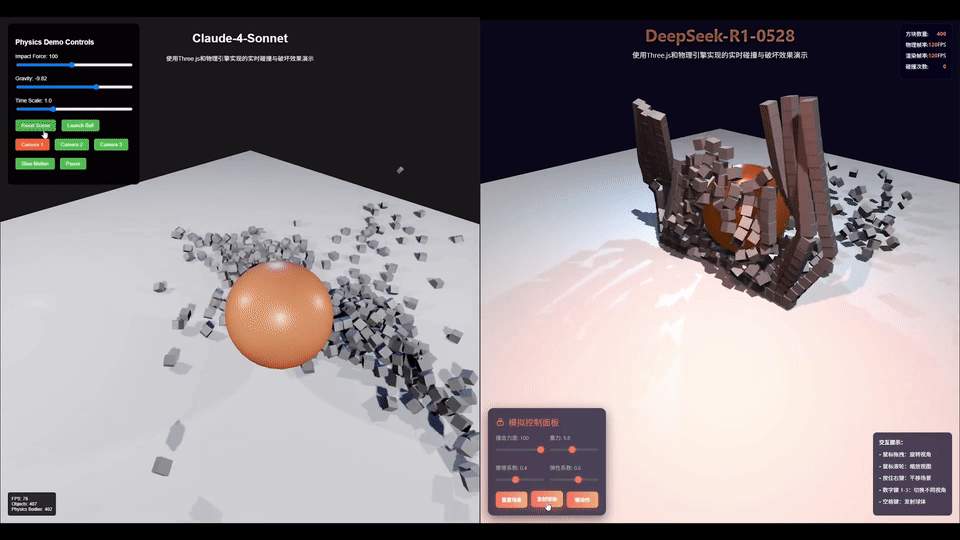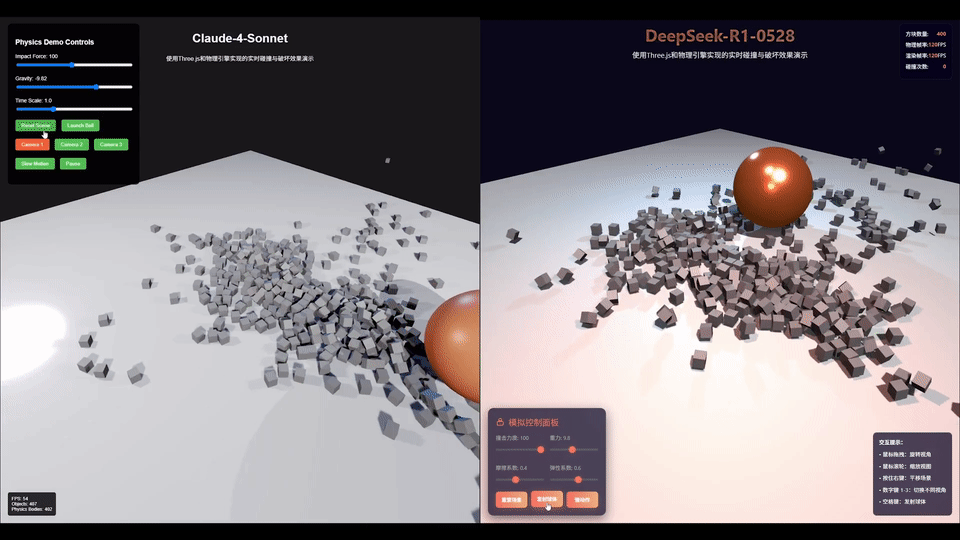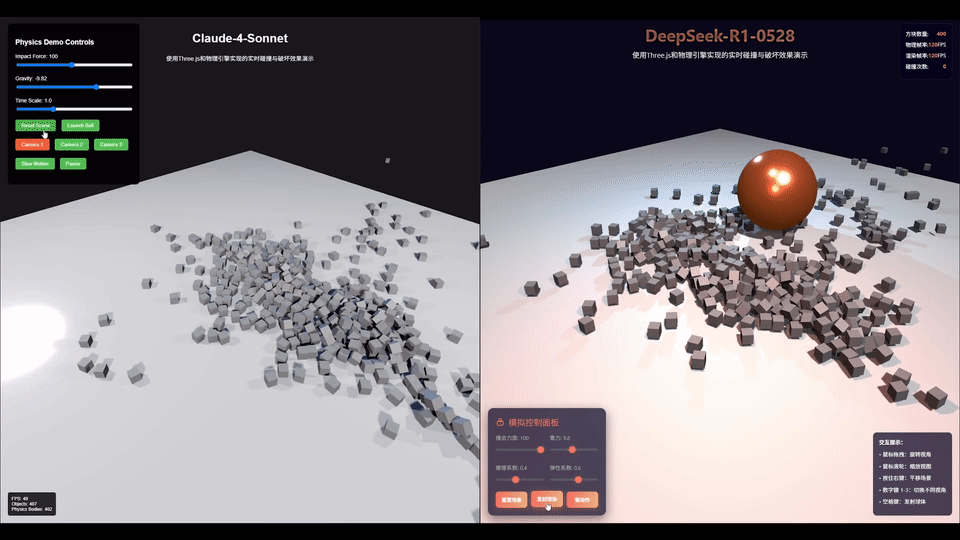
AI圈大佬「karminski-牙医」用同一个prompt测试了DeepSeek-R1-0528和Claude 4 Sonnet后发现。
不管是光线照射在墙上形成的漫反射,还是球在撞击后的运动方向,亦或是控制面板的美观程度,这一把R1稳赢。

网友Alex的测试也显示出,DeepSeek-R1在前端编码的能力上超越了Claude 4 Sonnet。

|
|

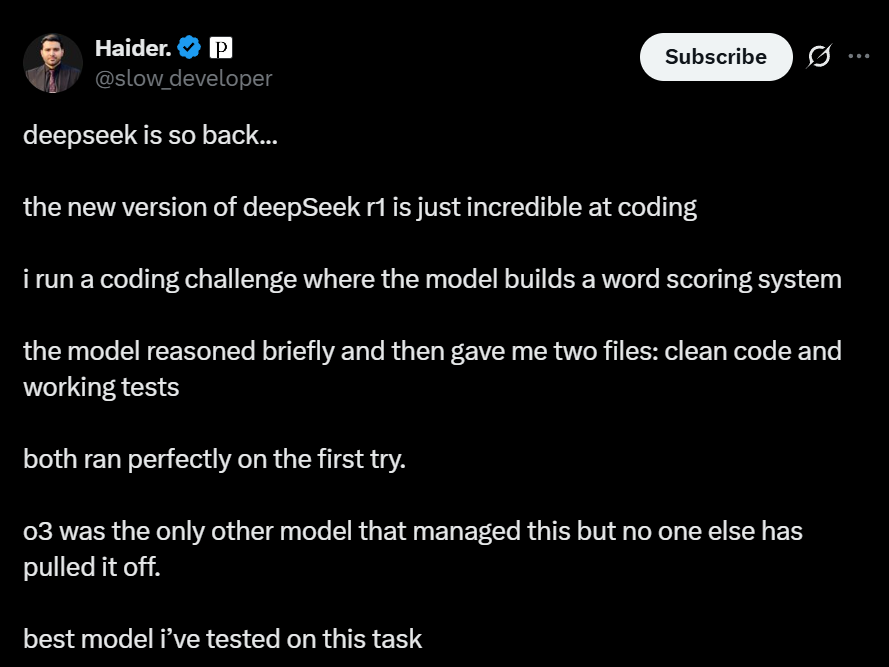
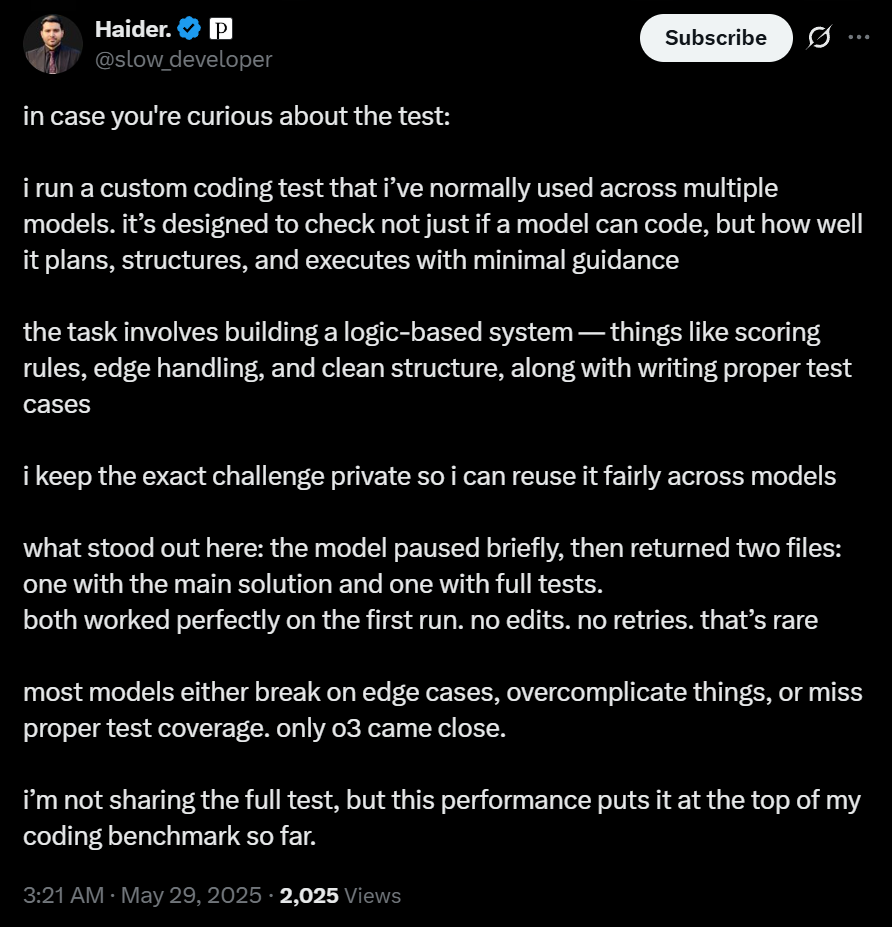
网友Haider.则是让模型构建一个单词评分系统。R1简要思考后,就立刻出了关于代码和工作测试的两个文件,第一次运行就完美无瑕。
此前,o3是唯一能完成这个任务的模型。而如今,R1堪称是完成这个任务的最佳模型。
注意,R1的表现之所以如此惊人,是因为它返回的两个文件在第一次都能运行良好,不用编辑,不用重试,这极其少见。
因为此前的大多数模型,要么会在边缘情况下终端,要么会做得太复杂,要么缺少适当的测试覆盖率。
2. 和Gemini高能PK
还有人将DeepSeek-R1与Gemini 2.5 Pro进行了对标。同一个提示下,它们各自的表现如何?
首先是深度研究的能力,给出「研究微剂量服用裸盖菇素对长期认知的影响,需引用学术来源」提示。
这一把Gemini的响应更快,引用了可靠的研究文献,并且答案结构清晰。
再来看看它们搜索+对比能力如何?提示模型用实时来源列出全民基本收入(UBI)的五大优点和缺点。
这时,Gemini 2.5 Pro和DeepSeek R1表现都不错,打成平手。
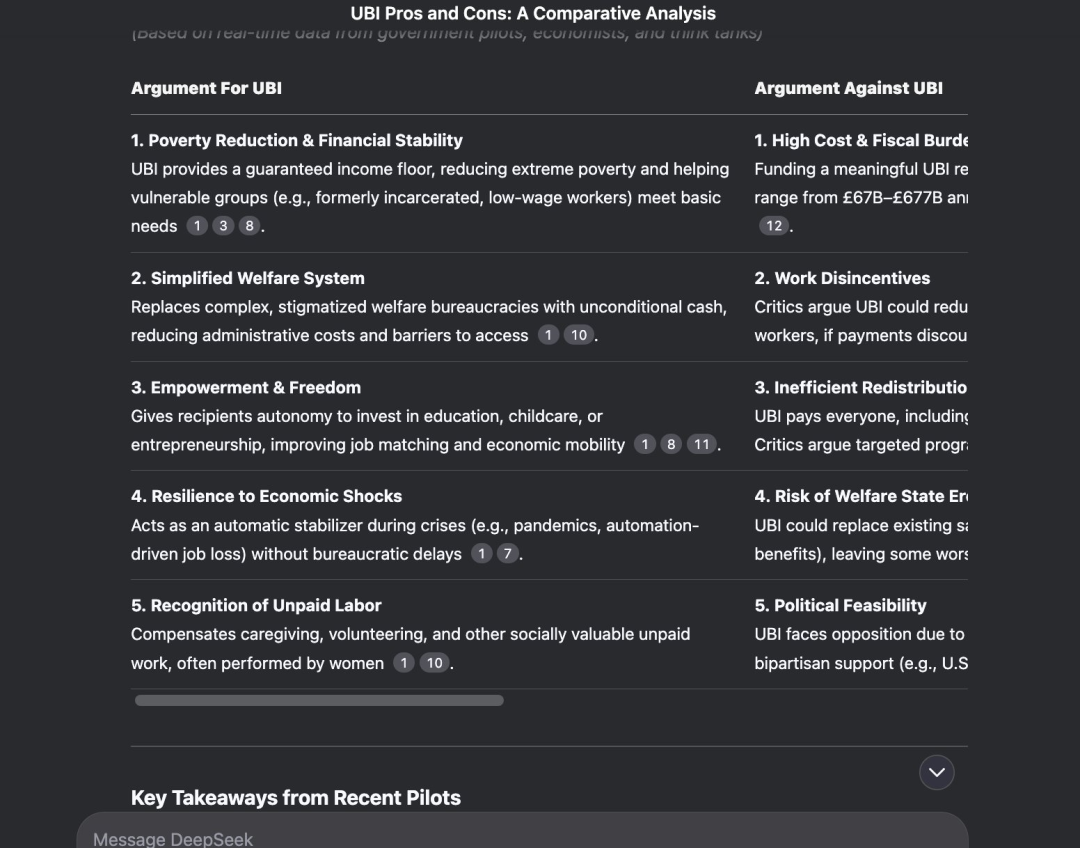
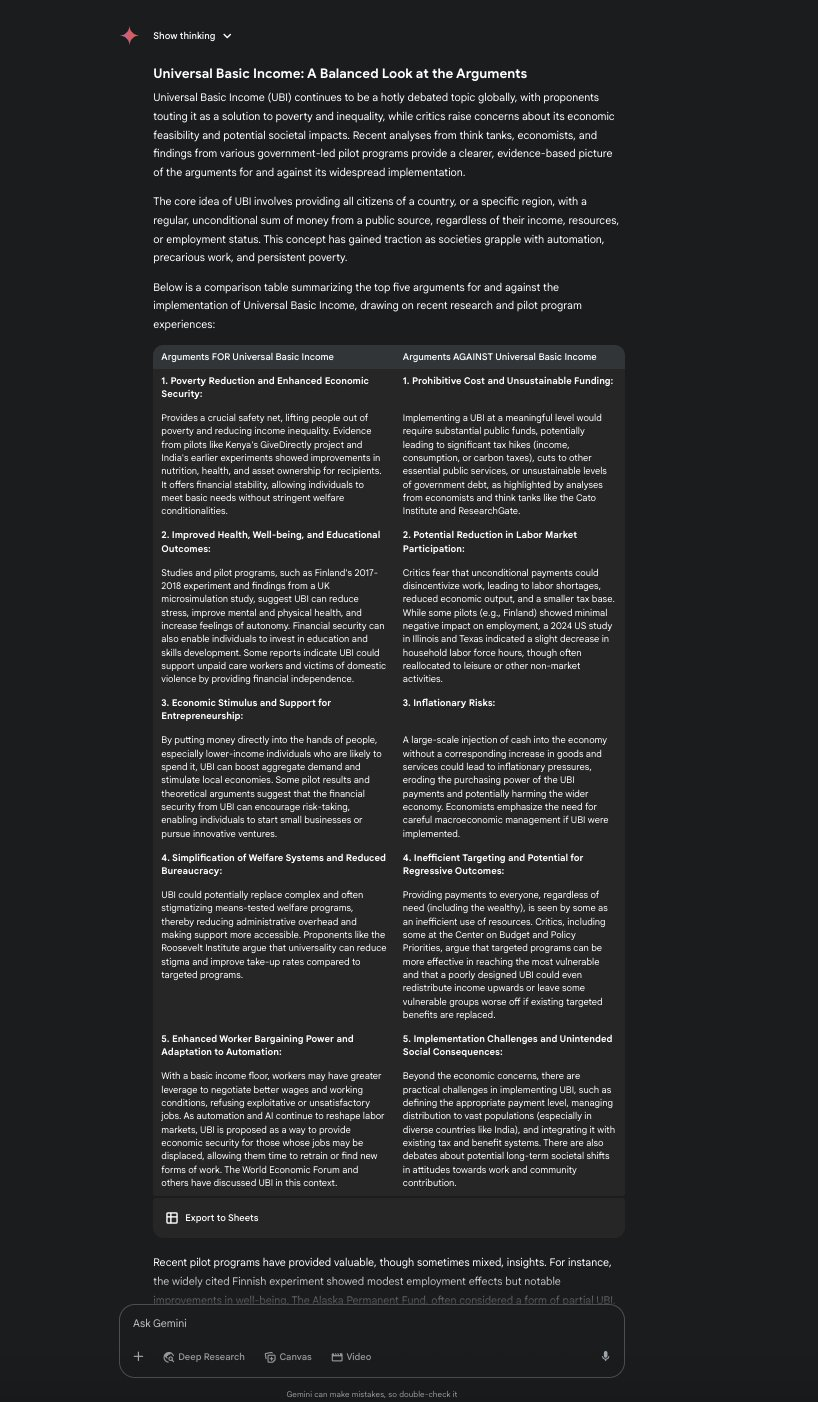
Prompt: List top 5 pros/cons of Universal Basic Income using live sources.
上下滑动查看
再让模型为AI SaaS工具制定TikTok增长策略,两款模型再次打成平局。
在智能体任务规划方面,让Gemini和DeepSeek一同设计一个完整的市场调研智能体,包含工具链、用户角色和流程交接,结果是Gemini生成一张信息图,而DeepSeek稍逊一筹。
由此,大家对DeepSeek-R2的期待值也是拉满了。
3. 一手实测来了
新版DeepSeek-R1的能力经过我们实测,虽然是一次「小版本」更新,但是性能得到了「史诗级」的加强。
尤其是编程能力,感觉已经超过或者足以媲美Claude 4和Gemini 2.5 Pro,可以说所有提示都是「一把过」,不需要任何修改!并且可以在网页端直接运行,展示效果。
首先是制作一个「新智元」字体在宇宙中旋转的3D动画,完成度相当之高。
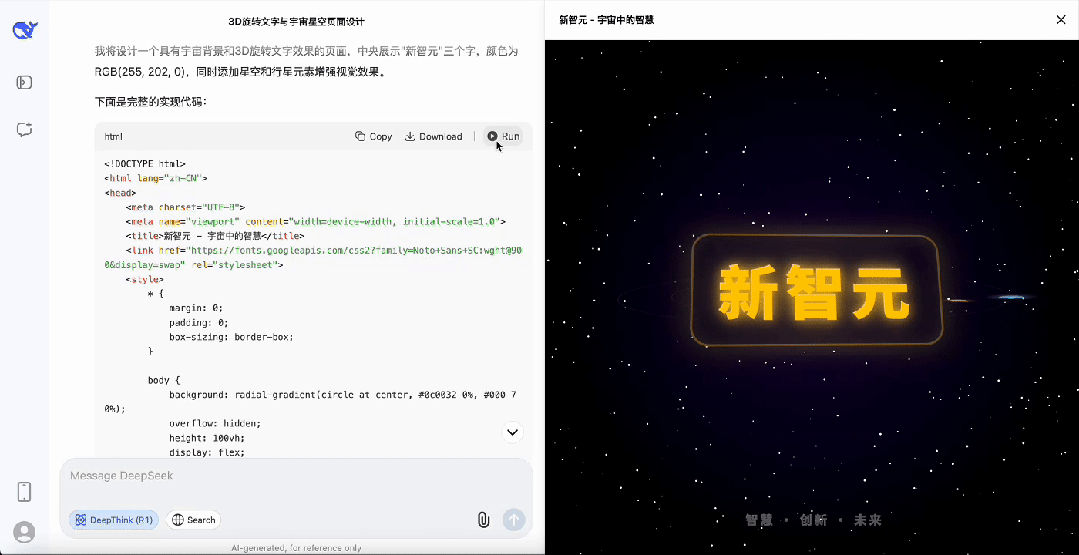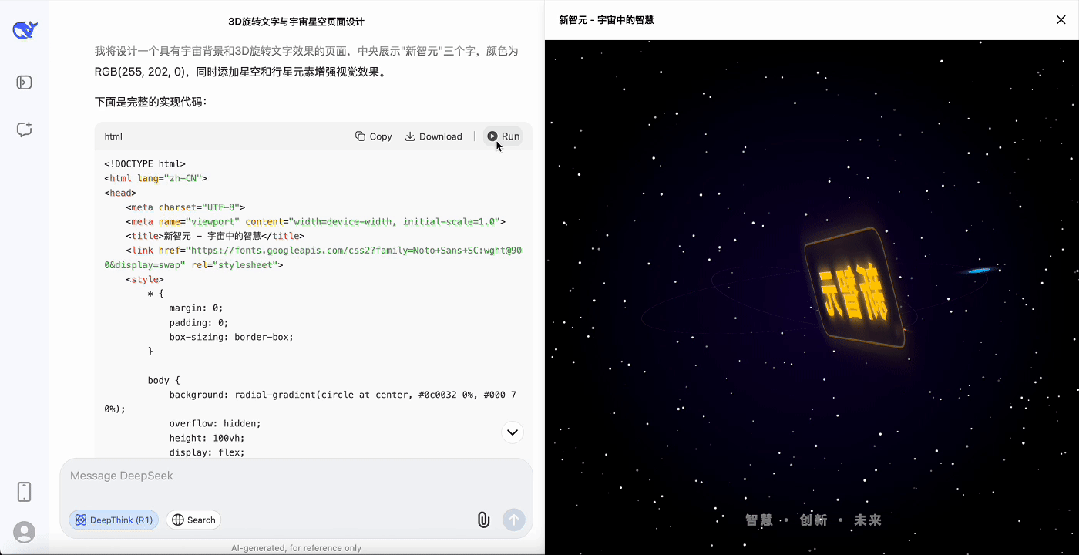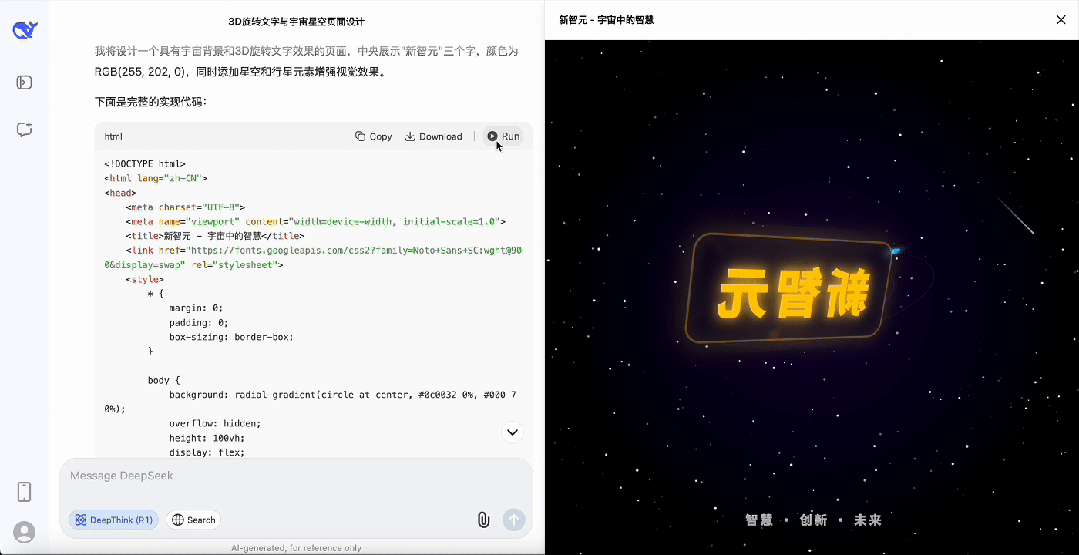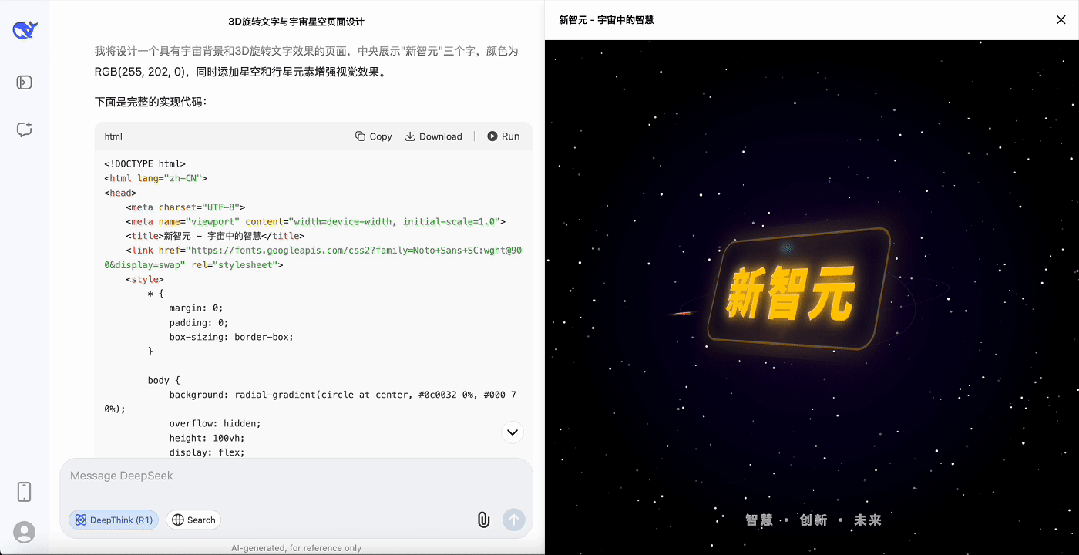
对于简单任务,DeepSeek-R1的思考时间明显缩短,不再像以前对简单任务也疯狂思考。
设计一个新智元的官方网站,对于这种相对容易的任务,DeepSeek-R1-0528只需要10s的思考时间。
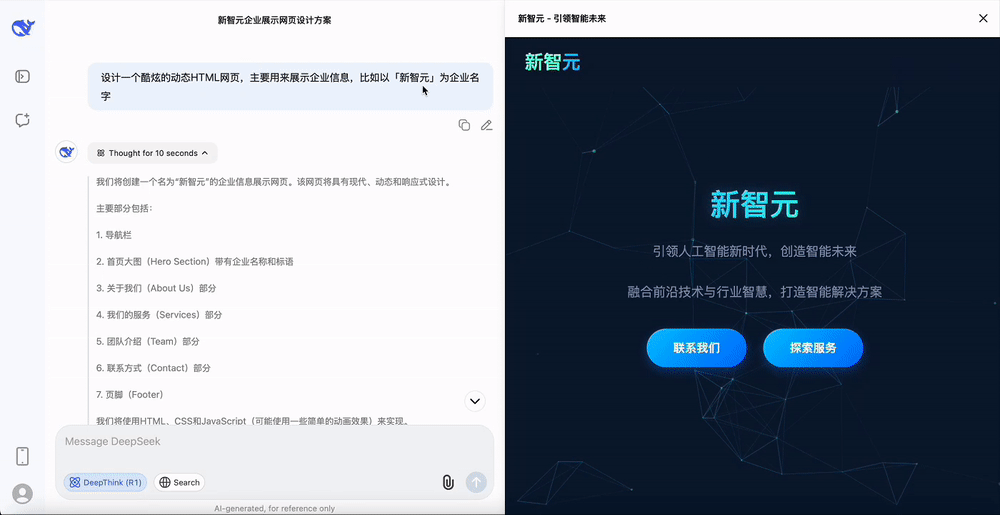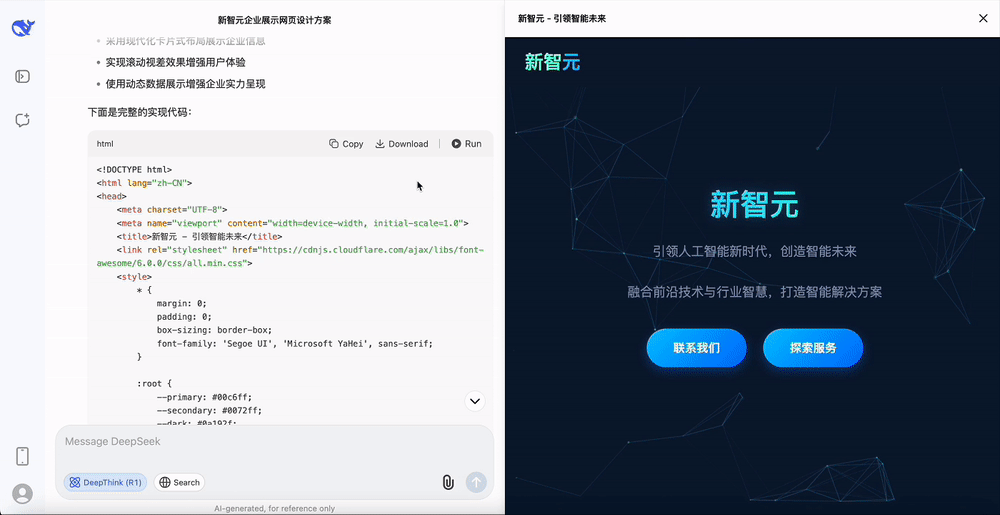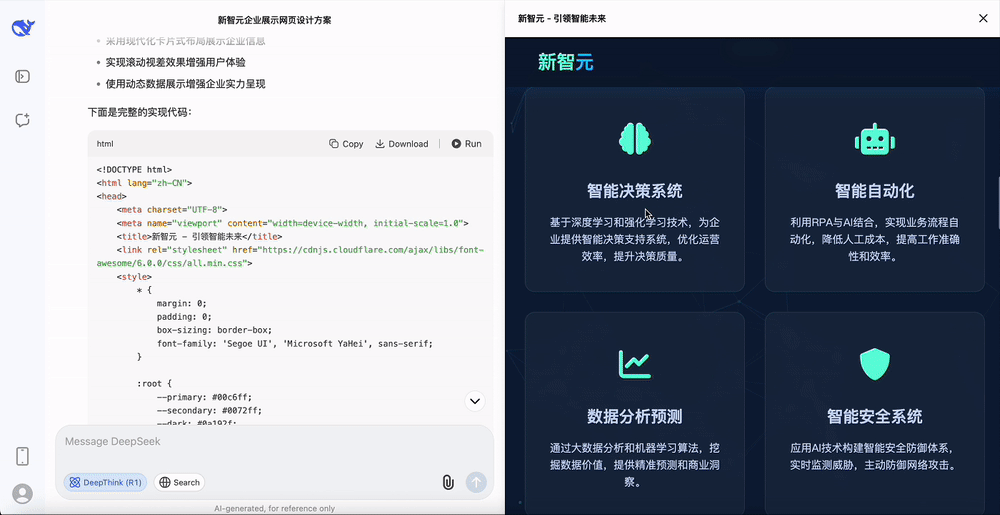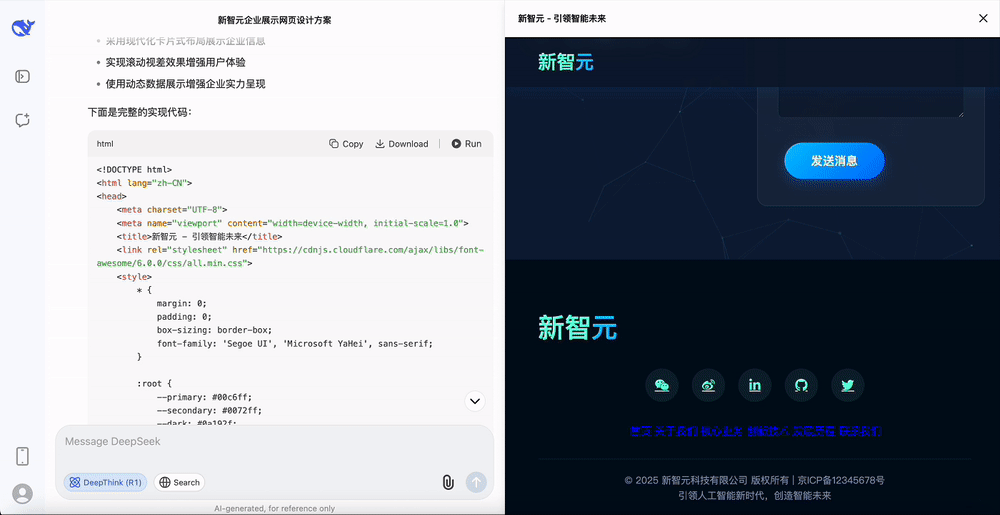
能够明显感觉到,这次DeepSeek-R1新版本的思考过程更加稳定。
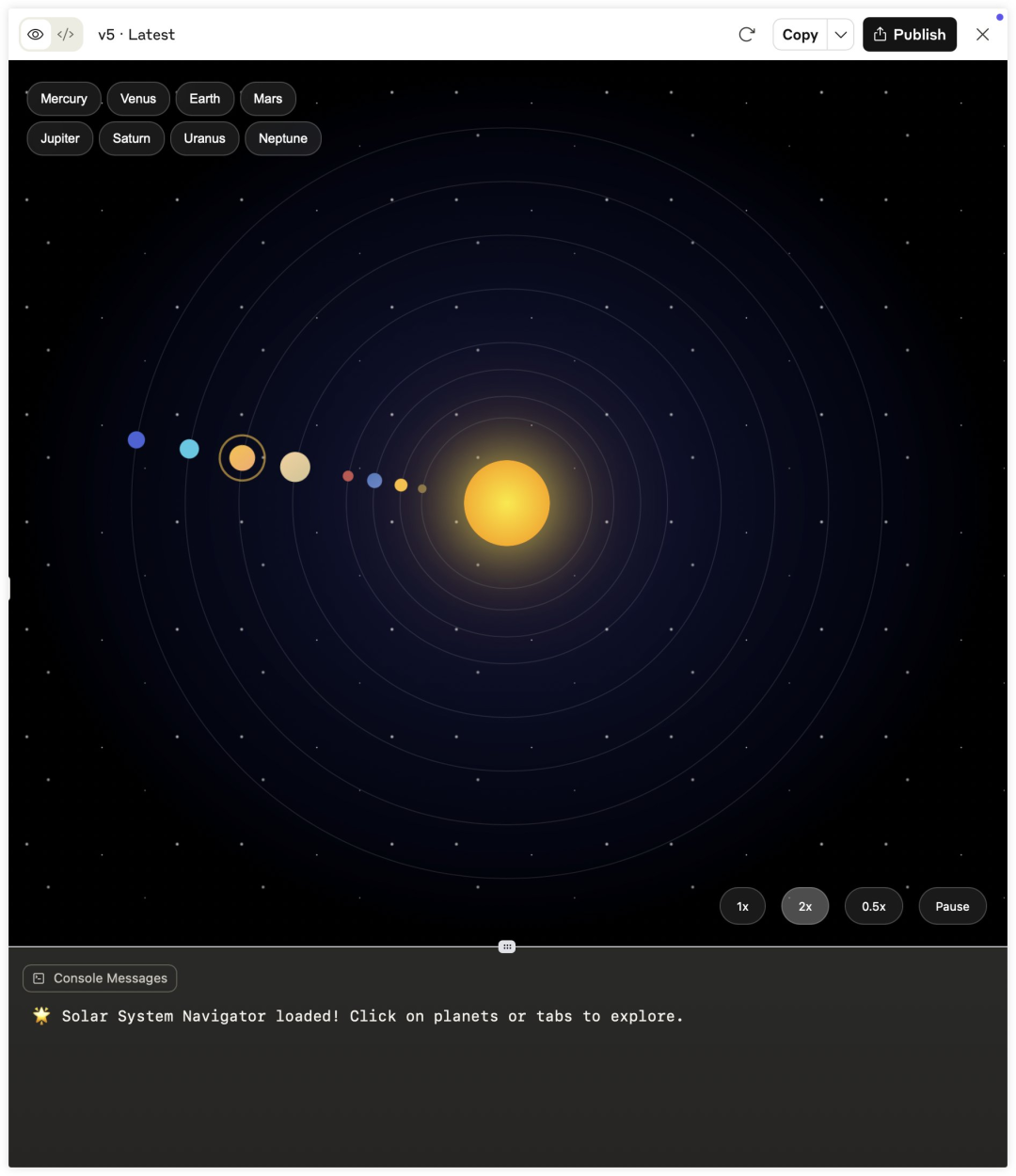
以模拟一个太阳系运行为例,还要求行星比例大小与实际相同,能看到DeepSeek-R1-0528的思考过程已经趋近于「完美」。
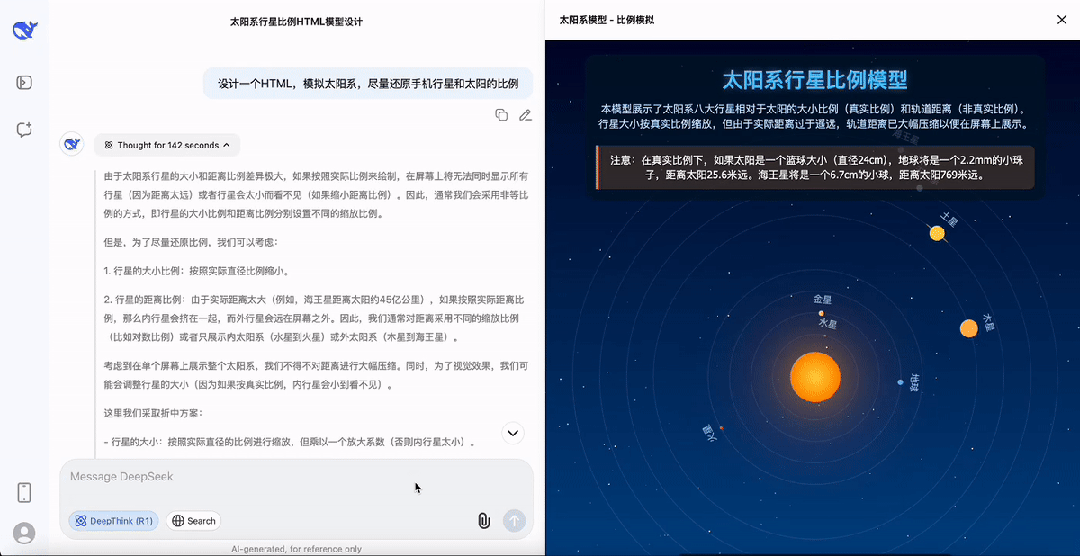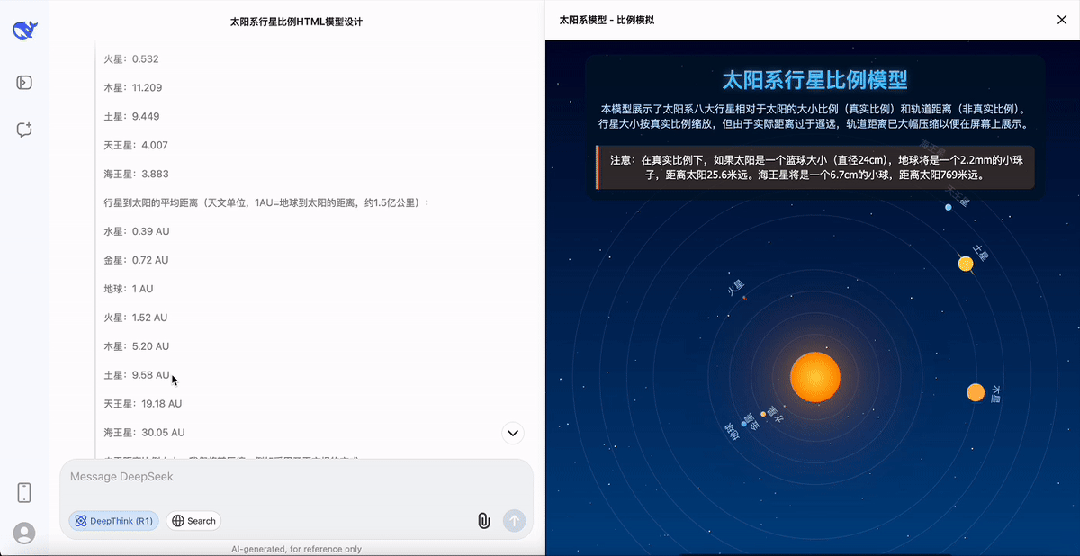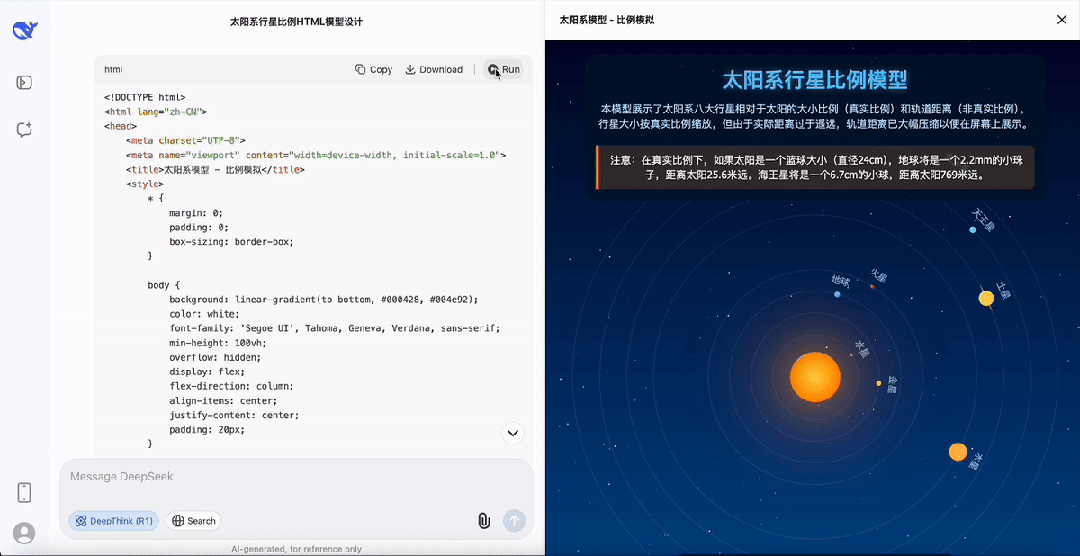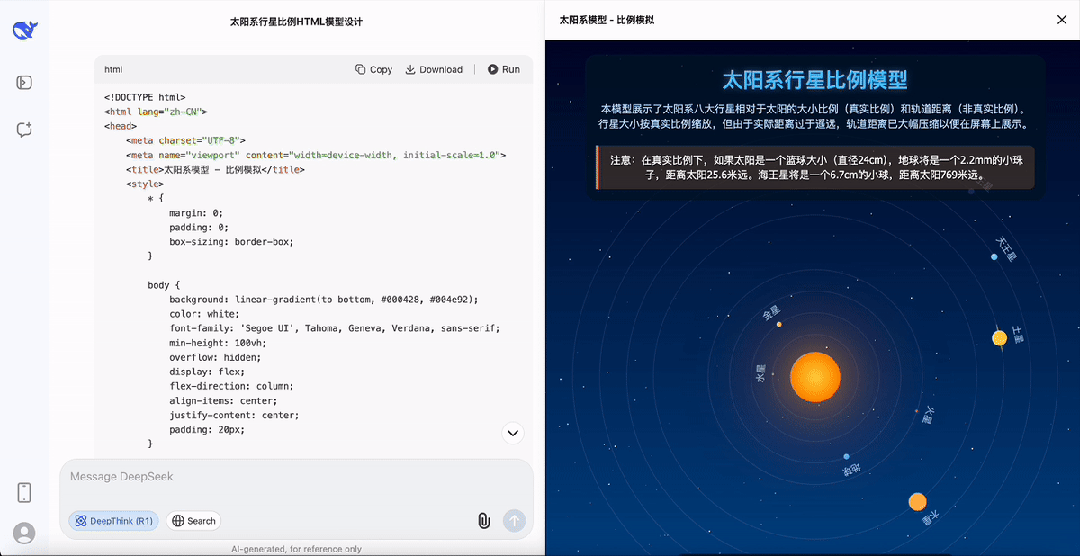
最后,再给DeepSeek-R1-0528上点强度,要求演示篮球落地后的弹跳过程,并且要完美遵循现实中物理规律。
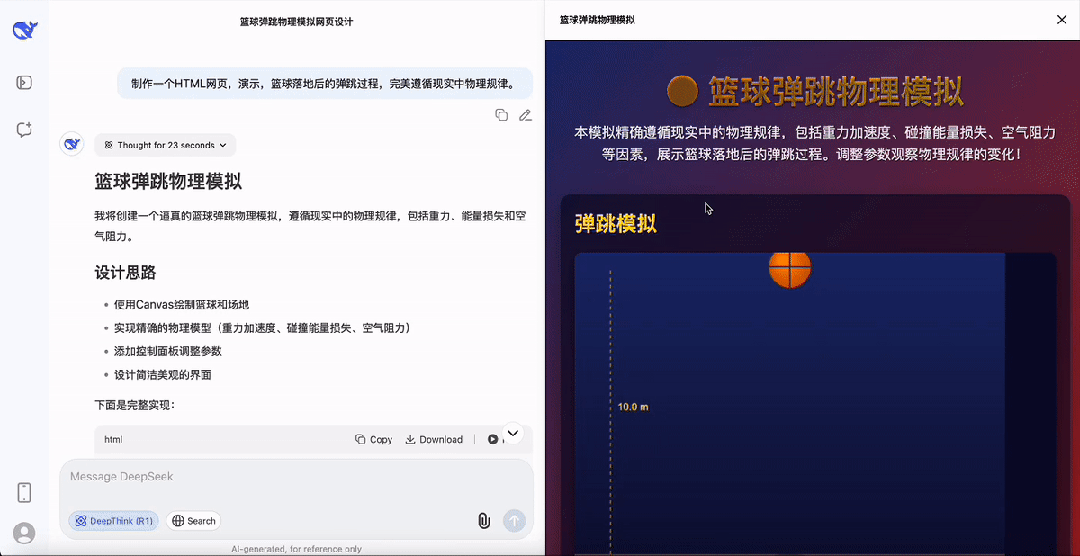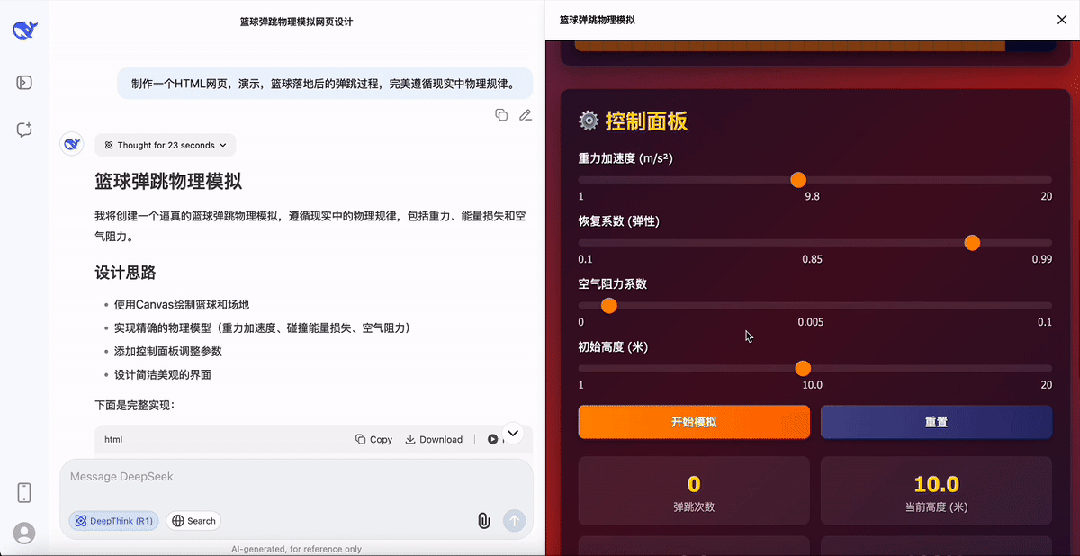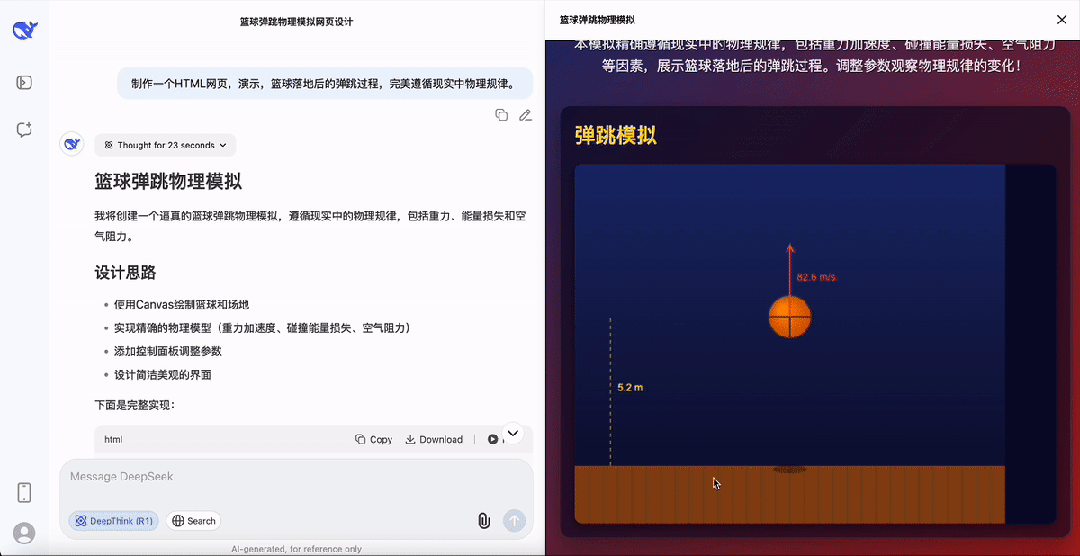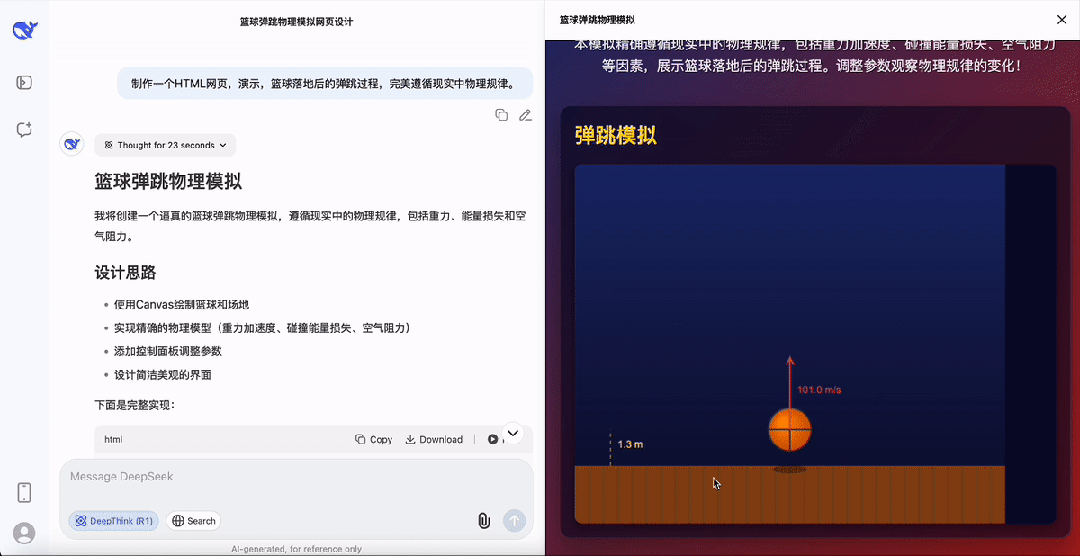
最终DeepSeek的成果还贴心的设计了参数控制面板,以及速度方向指示,是真的很强,以上所有代码都是提示之后一遍过,没有任何的Debug过程。
对于类似「华容道」的多步骤思考问题,DeepSeek-R1-0528的表现也非常完美,
比如「一位农夫要带一只狐狸、一只鹅和一袋豆子过河。船每次只能载他和一样物品。如果农夫不在场,狐狸会吃掉鹅,鹅会吃掉豆子。请问农夫该如何安排过河,才能确保所有物品安全?」这种复杂推理问题,DeepSeek-R1还可以给出核心问题所在。

最令我感到震惊的是,这次的「思考」能力似乎进行了秘密加强。
我给他了一个非常无厘头的族谱问题:「我的妈妈的爸爸的儿子的侄女的孙子的爷爷的舅舅的外孙女的姑姑,是我的谁,你能画出关系族谱图吗?」
以下过程经过3倍加速,可以看到DeepSeek-R1真的在通过数学的符号化方式在进行思考。

并且最后还真让他分析出了结果,简直震惊!这么长的思考链条都没有断。

另外值得一提的是,这次的思考过程并没有遇到服务算力不够的情况,看来DeepSeek有针对性的提高了算力,毕竟现在是模型刚发布后的高峰「测评」期。
参考资料:
https://chat.deepseek.com/
https://x.com/i/status/1927770337170592033
https://x.com/Yuchenj_UW/status/1927828675837513793
https://x.com/chetaslua/status/1927716608384094545
https://x.com/AiBattle_/status/1927824419478536405
https://huggingface.co/deepseek-ai/DeepSeek-R1-0528/tree/main
 一起“点赞”三连↓
一起“点赞”三连↓


















 528
528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









