



Datawhale分享
谷歌:Gemini 2.0,整理:Datawhale
就在凌晨,谷歌正式宣布 Gemini 2.0 对所有人开放!
本次发布带来了一系列更新和新模型,正式推出了 Gemini 2.0 Flash、 Gemini 2.0 Flash-Lite 以及新一代旗舰大模型 Gemini 2.0 Pro 实验版本,并且还在 Gemini App 中推出了其推理模型 Gemini 2.0 Flash Thinking。
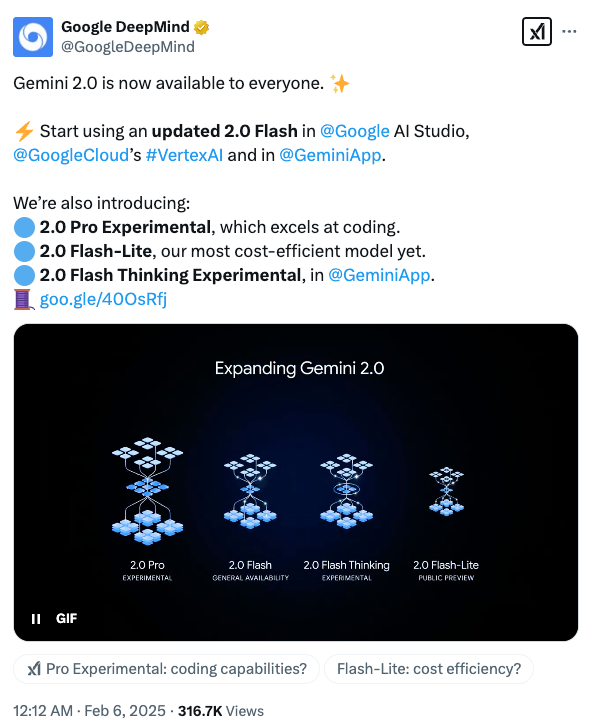
Gemini 2.0系列模型向所有人开放
最强 Pro 版本支持 2M 上下文,配备了谷歌搜索、代码执行能力,编码推理性能完全碾压 1.5 Pro。
Flash 版本被称为「高效主力模型」,支持 1M 上下文,低延迟构建应用。图像生成和文本转语音功能即将推出。
Flash-Lite 是最具性价比的模型,支持 1M 上下文和多模态输入,在相同速度和成本下性能超越 1.5 Flash。
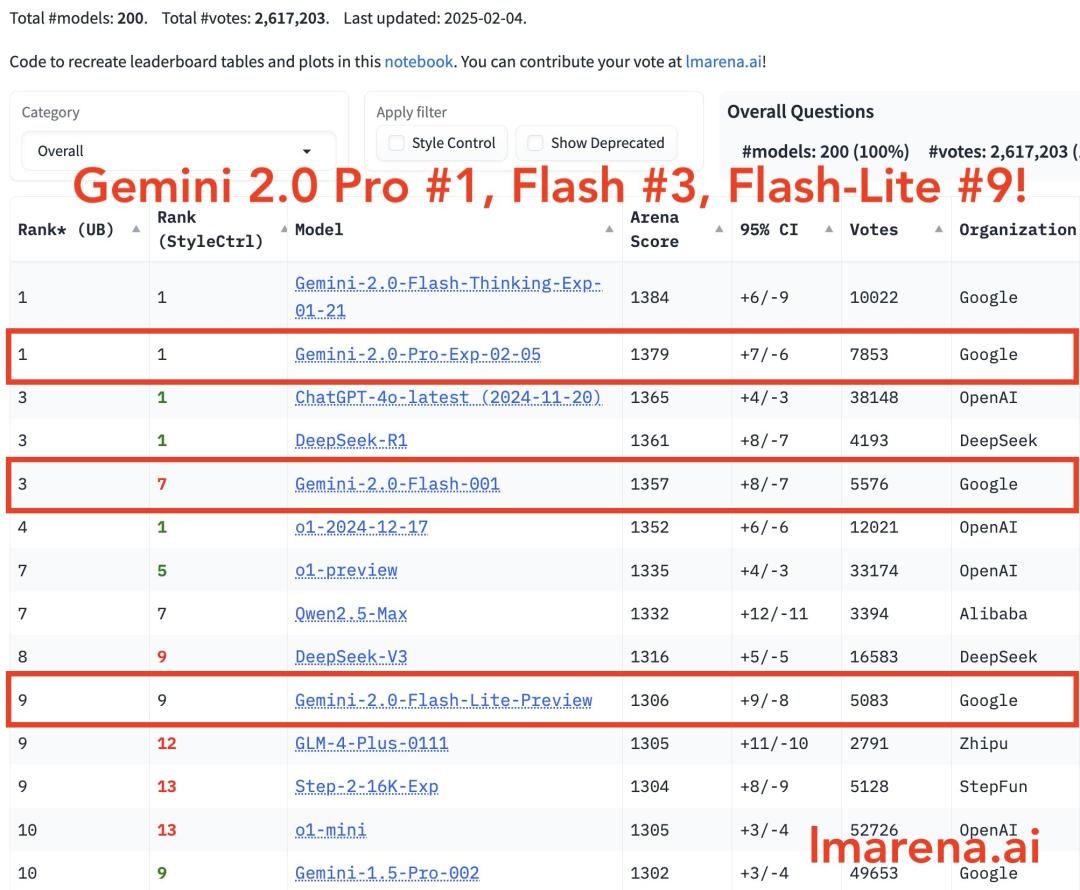
在大模型 LMSYS 排行榜中,Gemini 2.0 Pro 与四大模型并列第一,Flash 版本位列第三, Flash-Lite 位列第 9。
多模态能力仍是核心优势
从这张时间表来看,Google 的核心优势仍然在多模态能力上。

此前,Google DeepMind 的 CTO Koray Kavukcuoglu 在公司博客中写道:“这些模型在发布时将支持多模态输入(文本输出),并将在未来几个月内开放更多模态的全面使用。”
今天,谷歌在推理模型方面也发布了一些消息。
Google 首席执行官 Sundar Pichai 在社交网络 X 上宣布,Google Gemini 的 App 已经更新了 Google 自家的推理模型 Gemini 2.0 Flash Thinking。
令人惊讶的是,谷歌的推理模型支持上传图片,下面是一个测试示例:

于此同时,该模型可以连接到 Google 地图、YouTube 和 Google 搜索,从而实现一系列全新的 AI 驱动研究和交互。
相较而言,DeepSeek 和 OpenAI 目前专注在单一模态的大模型中,DeepSeek-R1 和 o3-mini 暂时还无法直接处理多模态输入(即无法解析图片、文件上传或附件)。虽然 DeepSeek-R1 在其网站和移动端支持图片上传,但它仅使用 光学字符识别(OCR) 来提取图片中的文本内容,而不是真正理解或分析图片的其他信息。
不过,谷歌能否将应用中的 AI 推理做得真正实用,还需要时间的检验。
谷歌 Gemini 2.0 三大模型:全方位加强
1. Gemini 2.0 Pro 实验版:最为出色
Gemini 2.0 Pro 实验版是谷歌迄今为止在编码和复杂指令任务中表现最好的模型。
在 Gemini 2.0 早期实验版本中(如 Gemini-Exp-1206),谷歌收到了来自开发者们的关于这些模型的优势和最佳用例的反馈,比如编码、复杂指令。
此次,Gemini 2.0 Pro 实验版本进一步强化了这些功能,具备了最强大的编码性能和处理复杂指令的能力,并且比谷歌此前发布的任何模型都具备更好的理解和推理世界知识的能力。
据官方博客介绍,该模型支持了谷歌最长的 200 万 tokens 上下文窗口,可以处理 2 小时视频、22 小时音频、6 万+ 行代码和 140 万 + 单词,从而能够全面分析和理解大量信息。同时,该模型还支持调用 Google Search 等工具和执行代码。
目前,Gemini 2.0 Pro 已经作为实验模型向 Google AI Studio 和 Vertex AI 的开发者以及桌面和移动设备上的 Gemini Advanced 用户提供。

2. Gemini 2.0 Flash:性能升级,全面可用
其次来看 Gemini 2.0 Flash,它是谷歌 Flash 系列模型的最新「成员」。
在 2024 年谷歌 I/O 大会上,Gemini 2.0 Flash(实验版本)首次亮相,此后便作为强大的主力模型而深受开发者的喜爱,并最适合大规模处理高容量、高频率任务,并能够通过 100 万 tokens 上下文窗口对海量信息进行多模态推理。
当前,Gemini 2.0 Flash 已经在谷歌的 AI 产品中向更多人全面开放使用。据介绍,该模型提供了全面的功能,包括原生工具使用。目前支持文本输出,并即将推出图像生成与文本转语音功能,未来几个月还将提供多模态 Live API。
目前,用户既可以在 Gemini App 中试用该模型,也可以在 Google AI Studio 和 Vertex AI 中使用 Gemini API。

3. Gemini 2.0 Flash-Lite:性价比最高
最后是 Gemini 2.0 Flash-Lite,它是谷歌目前为止性价比最高的模型。该模型针对大规模文本输出用例进行了成本优化。

谷歌表示,他们收到了关于 Gemini 1.5 Flash 在价格和速度方面的积极反馈,并希望在保持成本与速度优势的同时继续提升模型质量。因此,Gemini 2.0 Flash-Lite 在性能上更强,在大多数基准测试中均优于 1.5 Flash,并且速度和成本相当。
此外,与 2.0 Flash 一样,Gemini 2.0 Flash-Lite 支持 100 万 tokens 上下文窗口和多模态输入。比如,该模型可以为大约 4 万张不同的照片生成相关的单行字幕(或标题),在 Google AI Studio 付费套餐中仅花费不到 1 美元。
目前,Gemini 2.0 Flash-Lite 在 Google AI Studio 和 Vertex AI 中提供公开预览版。
下图为三个模型的一些参数汇总,可以看出图像和音频功能即将上线。

参考资料:
https://blog.google/technology/google-deepmind/gemini-model-updates-february-2025/
https://venturebeat.com/ai/google-launches-gemini-2-0-pro-flash-lite-and-connects-reasoning-model-flash-thinking-to-youtube-maps-and-search/
https://virtualizationreview.com/Articles/2025/02/05/Google-Opens-Up-Gemini-2-0-Touting-Multimodal-Capabilities.aspx
https://developers.googleblog.com/en/gemini-2-family-expands/


















 1146
1146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









