



Datawhale干货
作者:Jimmy.DU,Datawhale成员
1. Impressive Points
LLM模型推理能力提升
在LLM模型post-training中,仅使用强化学习(reinforcement learning,RL) 提升模型推理能力,不再依赖有监督微调训练(supervised fine-tuning,SFT)。
证明了LLM模型具有自行探索长思维链(chain-of-thought,COT) 的能力。
端侧模型(小模型)推理能力提升
相对于使用RL进行训练,基于大模型进行蒸馏(Distillation)的方式,是提升端侧模型推理能力更有效的途径。
2. 纯强化学习,LLM推理能力提升新范式?
2.1 DeepSeek-R1-Zero
核心问题: 当前的post-training流程对于大量监督数据的依赖,监督数据的收集非常耗时:
当前模型推理性能的提升,需要大量监督数据进行SFT,以作为模型post-training的冷启动。
当前一些研究已经验证了强化学习在模型推理性能上的有效性,但也依赖监督数据。
解决方案: 探索在没有任何监督数据的情况下,提升LLM模型的推理能力:
为了节省RL的训练成本,采用群体相对策略优化(GRPO),这个这里就不再多说了,后面专门出一篇文章讲一下GRPO。
在RL训练过程中,采用Rule-based奖励,主要由两种奖励构成:
Accuracy rewards:评估模型的输出是否正确。
Format rewards:强制模型将其思考过程置于指定标签之间。
设计训练模版,指导基模型在训练过程中遵守设定的指令:

成果:
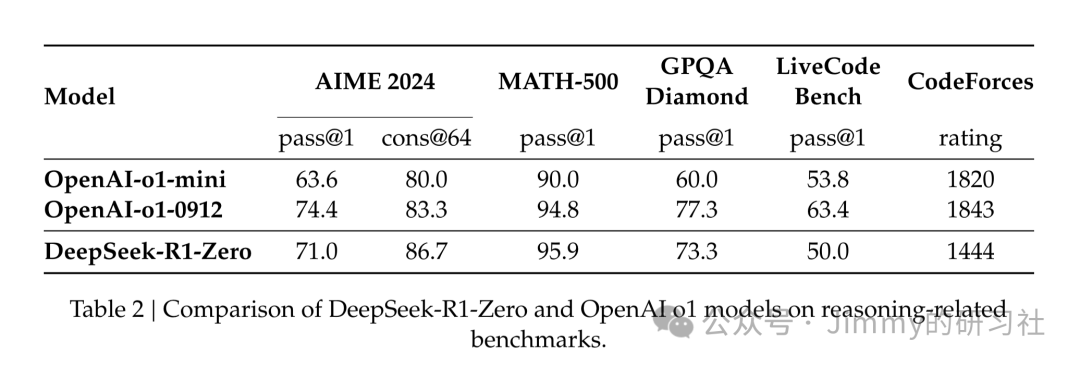
推出DeepSeek-R1-Zero模型,无需任何监督微调数据,仅通过RL进行模型的post-training,在AIME2024、MATH-500等多个Benchmark中达到并且超过OpenAI-o1-0912的水平。
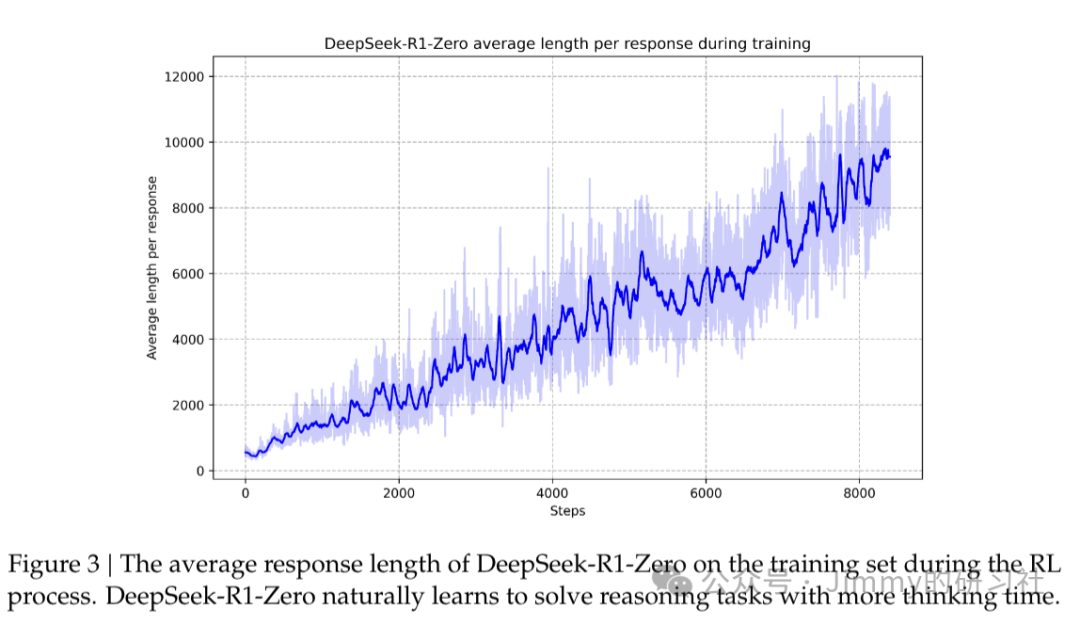
DeepSeek-R1-Zero展示出了自我进化(self-evolution) 能力,在没有监督数据的情况下,随着强化学习训练进程的深入,模型的思考时间在增加,并自发出现了诸如reflectio(反射,模型重新审视和重新评估其先前步骤)以及探索解决问题的替代方法等更加复杂的行为:
在DeepSeek-R1-Zero的训练过程中出现了Aha Moment(顿悟时刻),代表RL有可能在人工系统中解锁新的智能水平,为未来更加自主和自适应的模型铺平道路。

2.2 DeepSeek-R1
核心问题:
相对于完全不使用有监督数据,使用少量高质量数据作为冷启动,是否可以进一步提高推理性能或加速收敛?
针对DeepSeek-R1-Zero存在的输出内容可读性差的问题进行优化。
解决方案:
冷启动数据: 使用下述方法构建少量的(约几千条)长COT数据,作为冷启动数据对DeepSeek-V3-Base进行微调:
以few-shot的长COT prompt作为例子,让DeepSeek-R1-Zero通过反射和验证生成详细的答案;
将DeepSeek-R1-Zero的结果进行格式化;
让人工标注人员进行后处理。
Reasoning-oriented Reinforcement Learning: 完成冷启动数据微调后,采用与DeepSeek-R1-Zero一致的强化学习训练过程,同时针对DeepSeek-R1-Zero存在的语言混合,导致模型输出可读性差的问题,在RL训练期间引入语言一致性奖励(目标语言单词在 CoT 中的比例),将推理任务的准确性和语言一致性的奖励结合起来,直接相加作为最终的奖励。
Rejection Sampling and Supervised Fine-Tuning: 当2中的RL过程趋于收敛时,利用checkpoint生产用于下一轮训练的SFT数据。与1中的冷启动数据区别在于,冷启动数据针对推理能力提升,此阶段既包含用于推理能力提升的600k数据,也包含200k推理无关的数据。使用上述约800k样本的精选数据集继续对DeepSeek-V3-Base进行了两个epoch的微调。
Reinforcement Learning for all Scenarios: 为了进一步对齐模型和人类偏好,设计了二级强化学习阶段以同时提高模型的helpfulness(有用性) 和harmlessness(无害性):
helpfulness(有用性):只评估模型最终的结果,而不关注模型的推理过程。
harmlessness(无害性):既评估模型最终的结果,也评估模型的推理过程。
3. 端侧模型能力提升:蒸馏>强化学习
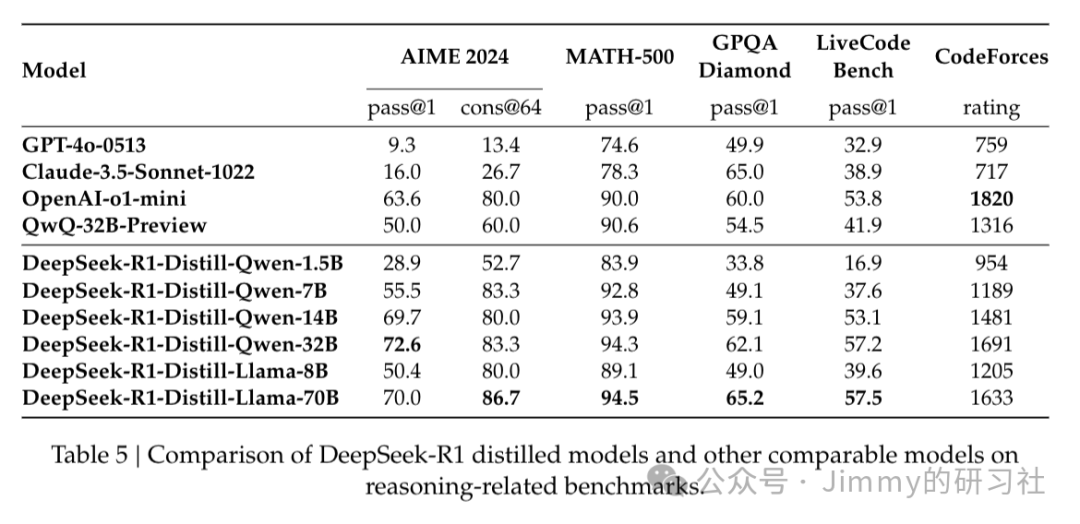
基于DeekSeek-R1,文中仅使用SFT对小模型(Qwen、Llama等)进行蒸馏训练得到的模型,性能全面优于GPT-4o-0513等大参数量非推理模型:
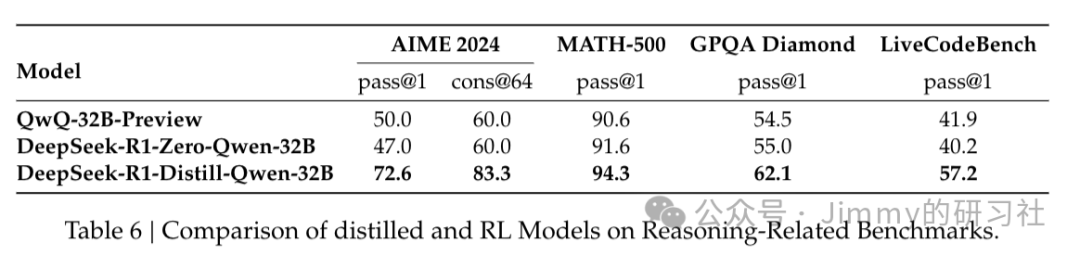
同时,直接对小模型进行DeepSeek-R1-Zero同款的强化学习,得到的DeepSeek-R1-Zero-Qwen-32B模型性能弱于蒸馏模型:
Tips:文中提到将RL应用于蒸馏模型会产生显著的进一步收益,应用方法文中没有详细说明,留给学术界去进一步探索。
作者:Jimmy.DU,Datawhale成员

一起点赞三连↓



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









