 使用TextCNN进行心电图智能诊断的实战解析
使用TextCNN进行心电图智能诊断的实战解析





Datawhale干货
作者:阿水,北京航空航天大学,Datawhale成员
本文以世界人工智能创新大赛(AIWIN)心电图智能诊断竞赛为实践背景,给出了数据挖掘实践的常见思路和流程。本项目使用TextCNN模型进行实践,全文代码及思路如下。后台回复 211114 可获取完整代码。
代码地址:
https://aistudio.baidu.com/aistudio/projectdetail/2653802

赛题背景及任务
心电图是临床最基础的一个检查项目,因为安全、便捷成为心脏病诊断的利器。由于心电图数据与诊断的标准化程度较高,相对较易于运用人工智能技术进行智能诊断算法的开发。本实践针对心电图数据输出二元(正常 v.s 异常)分类标签。
比赛地址:http://ailab.aiwin.org.cn/competitions/64
赛题数据
数据将会分为可见标签的训练集,及不可见标签的测试集两大部分。其中训练数据提供 1600 条 MAT 格式心电数据及其对应诊断分类标签(“正常”或“异常”,csv 格式);测试数据提供 400 条 MAT格式心电数据。
数据目录
DATA |- trainreference.csv TRAIN目录下数据的LABEL
|- TRAIN 训练用的数据
|- VAL 测试数据数据格式
12导联的数据,保存matlab格式文件中。数据格式是(12, 5000)。
采样500HZ,10S长度有效数据。具体读取方式参考下面代码。
0..12是I, II, III, aVR, aVL, aVF, V1, V2, V3, V4, V5和V6数据。单位是mV。
import scipy.io as sio
ecgdata = sio.loadmat("TEST0001.MAT")['ecgdata']trainreference.csv格式:每行一个文件。格式:文件名,LABEL (0正常心电图,1异常心电图)
实践思路
TextCNN 模型是由 Harvard NLP 组的 Yoon Kim 在2014年发表的 《Convolutional Neural Networks for Sentence Classification 》一文中提出的模型,由于 CNN 在计算机视觉中,常被用于提取图像的局部特征图,且起到了很好的效果,所以该作者将其引入到 NLP 中,应用于文本分类任务,试图使用 CNN 捕捉文本中单词之间的关系。
本实践使用TextCNN模型对心电数据进行分类。
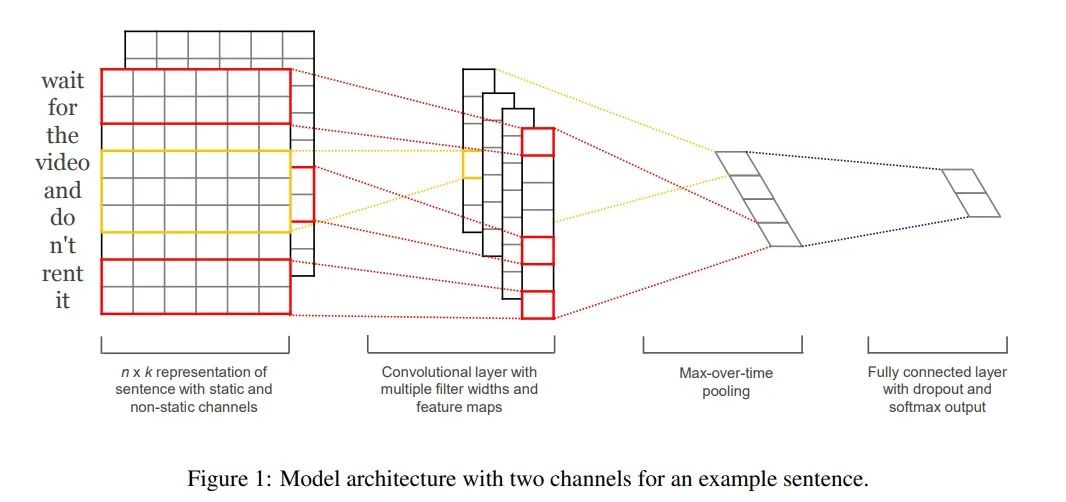
改进思路
使用多折交叉验证,训练多个
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 470
470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









