



网页抓取(Web scraping)和网页爬取(Web crawling)听起来相似,但其实不同。网页抓取是从网站收集特定数据;而网页爬取是沿着互联网“走一遍”看看都有什么,就像在森林里走来走去熟悉路径。这些过程对企业很重要,因为它们帮助企业理解并利用海量线上信息。
下面我们来进一步了解它们如何工作以及彼此有哪些不同。
快速回答
简单来说,我所说的网页抓取是从网站获取数据,而网页爬取是在线发现链接或 URL。抓取就像从需要的信息书籍里做笔记;而爬取则是寻找我想要浏览的网页或链接,就像先列出想读的书单。
尽管它们看起来相似,但两者之间有重要差异。不过它们更像一个团队,在数据收集过程中协同工作。通常我做其中一个,也会做另一个。这就像先决定哪些书值得读,然后再进去做需要的笔记。
什么是数据抓取?
数据抓取是收集人人可见的信息。它不仅来自互联网,也可以来自你电脑上的文件。你会把这些信息保存到电脑中的文件里,有时也可能把这些信息发送到另一个网站。这是一种从互联网获取信息的有用方式,但有趣的是,并不总是需要联网才能完成。
什么是网页抓取?
网页抓取是指在线查找人人可见的信息,并将其保存到你的电脑里。进行这件事需要连接互联网。你可以使用 Python 程序等专用工具,或名为 Web Scraper API 的服务来简化流程。
什么是爬取?
网页爬取(也称数据爬取)是为了收集数据,可以来自互联网,也可以来自任何文档或文件。它通常是大规模进行的,需要一种名为爬虫代理(crawler agent)的专用工具。
Python 开发者 Bernardas Alisauskas 给出了一个理解爬虫的简单方式。他将爬虫描述为“一个找到网页并下载其内容的程序”。他说爬虫在网上会寻找两类东西:
-
用户想要的特定信息
-
更多可用于收集数据的网页位置。
爬取一个网站通常会这样进行:
-
爬虫从你选择的网站开始,例如 http://example.com.
-
它会寻找与产品相关的页面。
-
然后收集这些产品的详细信息,比如价格、名称和描述。
爬虫收集到的信息随后会被保存,这一步就是我们所说的网页/数据抓取。
爬取 vs. 抓取
谈到网页抓取与网页爬取的区别,关键在于它们在做什么以及如何去做。这里有一个简单的方式来理解主要差异:
爬取 是在互联网的各个部分中穿梭,例如点击网站链接。这就像探索不同区域,看看那里有什么。
抓取 发生在你找到所需数据之后——把数据提取出来并保存到你的电脑或你选择的其他位置。也就是说你已经明确目标并将其取回。常见的抓取内容包括产品详情、价格、标题和描述。
尽管爬取与抓取不同,它们通常协同工作来从互联网收集数据。爬取帮助你发现数据;抓取则是获取并保存数据的方式。
我们用一张表来拆解这些差异:
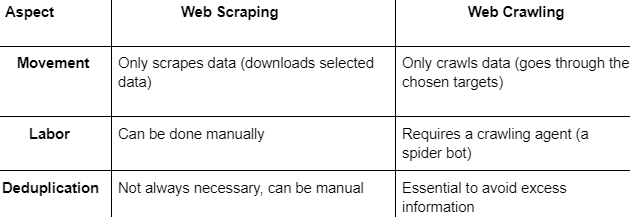
简单来说,网页抓取关注保存特定数据;网页爬取关注在网上各处探索以发现数据。抓取可以手动完成,而爬取通常需要专用工具。抓取不一定需要去重,但爬取往往会自动进行去重。
面向业务的数据抓取
数据抓取对发展我的业务非常重要。它帮助我更好地了解客户,并做出更明智的决策。专家表示,像我这样的善用数据的公司,更有可能获取新客户并保持他们的满意度,而且还能赚到更多钱!
每年都有许多企业在数据方面变得更聪明,平均增长约 30%。到 2025 年,他们的盈利可能会远超竞争对手。
我可以用数据抓取以多种方式改进业务:了解竞争对手的做法并制定合适的定价;用于营销与销售,例如寻找新客户、了解人们在网上喜欢什么;在开发新产品时,从其他网站获取灵感并查看我的产品是否有货。
关注品牌与风险至关重要。我可以通过数据抓取来确保广告有效、并监测人们对我品牌的评价。当我进行未来规划时,也可以用数据抓取来了解趋势与行业动态。
但这不仅仅是抓取数据,我还需要确保我的网站能在搜索引擎中被发现——人们就是这样在网上找到我的!因此,我要确保网站便于搜索引擎抓取与理解。这样就会有更多人找到我的业务,我也能获得更大发展。
结论
现在我们更清楚地理解了网页爬取与网页抓取的区别。爬取涉及在数据中“浏览穿行”,而抓取则是把这些数据下载下来。若与 Web 相关就离不开互联网,但如果谈的是数据,则不一定总是需要联网。
数据抓取对于企业获客与增加收入至关重要。随着公司越来越依赖互联网来获取情报,企业需要抓取更多数据才能保持领先!


















 1285
1285

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









