



到 2025 年,命令行仍然是开发者不可或缺的工具,尤其是在用 cURL 做网页抓取时。用 cURL 抓取网页既简单又强大。cURL 是一个免费的命令行工具,它能帮我“和”Web 服务器对话,轻松获取数据。它能做很多事,比如代替用户登录、抓取会变化的网站内容,同时还可以使用代理服务器。它支持所有主流协议,比如 HTTP 和 HTTPS。接下来我会从简单到复杂,演示如何使用 cURL。

网页抓取中的 cURL 是什么?
cURL 是 “Client URL(客户端 URL)” 的缩写,是一个用于在 Web 服务器之间传输数据的工具。它可以通过不同协议工作,比如 HTTP、HTTPS,以及 FTP.cURL。它让我通过命令与 Web 服务器沟通。借助 cURL,我可以用不同协议(如 HTTP 和 HTTPS)从网站发送和接收数据。无论是从 API 获取数据还是远程管理文件,cURL 都可靠又直观。它是我最喜欢的工具之一,因为它能顺畅地处理各种任务。
cURL 的强大之处在于其简洁的命令。我喜欢它的易用性以及覆盖的广泛用例。人们喜欢它,是因为它不复杂,而且可以根据需要进行调整。它是我数据提取工具箱中值得信赖的一员,能帮我处理各种与 Web 数据相关的任务。
先决条件
在使用 cURL 进行网页抓取之前,请确保你的电脑已经安装了它。根据操作系统,安装方式如下:
A)Linux:打开终端并输入命令:
apt-get install curl
B)Mac:通常已预装,但如果你想要最新版本,可使用 Homebrew:
brew install curl
C)Windows:如果你使用的是 Windows 10 或更新版本,通常已自带 cURL。更早的版本请访问官网,下载最新发行版并安装到你的电脑上。
安装完成后,在终端中输入 “curl” 测试。如果设置正确,你会看到类似的信息:
curl: try 'curl - help' or 'curl - manual' for more information
就这样!你已经准备好用 cURL 开始抓取网页了。
如何使用 cURL 进行网页抓取
用 cURL 发送请求,只需在终端输入 “curl” 加上目标 URL。这样就能开始!
终端
curl https://httpbin.org/anything
你会立刻在屏幕上看到该网页的 HTML 内容。
要发起更高级的请求,你可以在 URL 前添加更多参数:
{
"args": {},
"data": "",
"files": {},
"form": {},
"headers": {
"Accept": "*/*",
"Host": "httpbin.org",
"User-Agent": "curl/7.86.0",
"X-Amzn-Trace-Id": "Root=1–6409f056–52aa4d931d31997450c48daf"
},
"json": null,
"method": "GET",
"origin": "83.XX.YY.ZZ",
"url": "https://httpbin.org/anything"
}
cURL 允许你在目标 URL 之前添加额外选项来实现更多功能。你可以使用 HTTP、HTTPS、FTP 等协议进行数据传输。只需输入 “curl”,然后添加选项和网站地址即可。
curl [options] [URL]
如果你想提交表单,需要使用 POST 方法,用 “-d” 参数表示。比如,要提交用户名 “David” 和密码 “abcd”,可输入:
curl -d "user=David&pass=abcd" https://httpbin.org/post
如下所示:
{
"args": {},
"data":
11 11
"
"files": {}, "form": {
"pass": "abcd",
"user": "David"
},
"headers": {
"Accept": "*/*".
},
"Content-Length": "20",
"Content-Type":
"application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "curl/7.86.0",
"X-Amzn-Trace-Id": "Root-1–6409f198–2ddef75220b12fb80be07a3b"
},
如何在不被封禁的情况下进行网页抓取
使用 cURL 进行网页抓取时,避免被封禁可能有些棘手。为此,你可以学习两种方法:使用轮换代理和自定义请求头。
轮换代理
从同一 IP 地址短时间内向网站发送大量请求,会让你看起来像机器人,从而可能被封禁。代理服务器可以帮助解决这个问题。它充当中间人,用另一个 IP 隐藏你的真实 IP。
例如,你可以在网上找到免费的代理列表,选择一个 IP 在下一次请求中使用。但请注意,免费代理大多存在风险。使用 cURL 的方式如下:
curl - proxy <proxy-ip>:<proxy-port> <url>
将 替换为代理的 IP,将 替换为端口号。例如:
curl - proxy 198.199.86.11:8080 -k https://httpbin.org/anything
不幸的是,使用免费代理有时会导致错误,比如出现 “Received HTTP code 500 from proxy after CONNECT.”。为了解决这个问题,你可以把一组代理存到文本文件里,并用 Bash 脚本自动测试每一个。这样就能轮换不同的代理,避免被封。
curl - proxy 8.209.198.247:80 https://httpbin.org/anything\
你可以把一堆代理地址保存到一个文本文件中,然后编写一个 Bash 脚本自动测试每个代理。工作原理如下:脚本会逐行读取 proxies.txt 文件,每读取一行,就把这一行设置为 cURL 请求的代理。
#!/bin/bash
# Read the list of proxies from a text file
while read -r proxy; do
echo "Testing proxy: $proxy"
# Make a request through the proxy using cURL
if curl - proxy "$proxy" -k https://httpbin.org/anything
>/dev/null 2>&1; then
curl - proxy "$proxy" -k https://httpbin.org/anything
echo "Success! Proxy $proxy works."
else
echo "Failed to connect to $proxy"
fi
# Wait a bit before testing the next proxy
sleep 1
done < proxies.txt
如果请求成功,且我们能通过该代理访问网站,脚本会显示网站内容并停止。如果不成功,我们就尝试列表中的下一个代理,直到找到可用的为止。
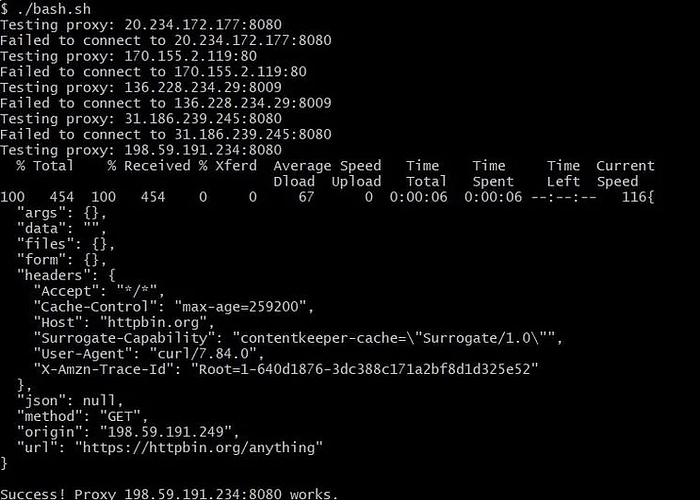
免费的代理池往往不稳定。更好的选择是购买带住宅 IP 的优质代理,或者使用能为你管理代理的更简单方案。
添加自定义请求头
当你浏览网页时,HTTP 请求头就像数字签名,在每个页面上标识你的身份。所以,即使你隐藏了 IP,如果不更改请求头,网站仍可能识别出你像个机器人。
在网页抓取中,最重要的请求头是 User-Agent 字符串。它告诉网站你使用的浏览器和设备。示例如下:
Mozilla/5.0 (Macintosh; Intel Mac OS X 13_2_1) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.3 Safari/605.1.15
要更改 cURL 抓取器的 User-Agent,可使用 “-A” 选项并跟上想要的字符串。例如:
curl -A "Mozilla/5.0 (X11; Linux x86_64; rv:60.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36" https://httpbin.org/headers
注意:随意更换 User-Agent 可能导致封禁,因为各项数据可能不匹配。为避免这种情况,你可以参考适合用 cURL 进行网页抓取的常见 User-Agent 列表。
结论
无论是简单任务还是稍复杂的任务,cURL 在从网站收集信息方面都非常好用。不过,我也注意到,单靠 cURL 抓取数据在一些网站上变得越来越难。因此,我开始把它和其他工具配合使用,以绕过更强的防护。这样,即使网站提高了门槛,我也能持续获取所需数据。关键在于不断探索新方法,保持领先,持续收集有价值的信息!



















 259
259

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









