



结构化 vs. 非结构化数据对比
你是否想过,为什么有些数据看起来井井有条,而有些则像一团乱麻?那是因为数据并不相同。有些数据被很好地组织,称为结构化数据;而更多的数据分散无序,被称为非结构化数据。它们的采集与处理方式不同,且通常存放在不同类型的数据库中。本文将为你解释这两类数据,展示它们的差异,以及如何高效使用每一种类型。我们开始吧!

什么是结构化数据?
结构化数据是经过组织、可归入记录或文件中具体类别的数据。它通常存储在关系型数据库(RDBMS)中。这类数据既包括文本也包括数字。只要遵循 RDBMS 的格式,结构化数据即可通过自动或手动方式收集。要搭建结构化数据,需要先建立数据模型,用于定义包含的数据类型以及其存储与处理方式。
SQL(结构化查询语言)是管理结构化数据的编程语言。IBM 于 1974 年开发了 SQL 来处理关系型数据库。它简单易用,不需要高级编程技能。结构化数据的例子包括姓名、地址、信用卡号,以及 Microsoft Excel 或文本文件中的信息。
什么是非结构化数据?
非结构化数据是不符合特定类别的所有数据。不同于结构化数据,非结构化数据不遵循特定格式。它没有既定模型,而是按原样存储。
非结构化数据的例子包括图片、文本、社交媒体帖子、视频、音频录音以及许多其他类型的文件。
非结构化数据在所有数据中占比很大,甚至超过结构化数据。据估计,它约占企业全部数据的 80% 或更多,而且还在不断增长。因此,如果公司不重视非结构化数据,可能会错失对业务至关重要的洞见。
什么是半结构化数据?
半结构化数据是结构化与非结构化数据的混合。它具备一定结构,但并不能很好地放入传统数据库。相反,它通过标签和标记来组织信息,使之更易于检索。
智能手机照片就是一个很好的例子。每张照片包含图像本身(非结构化),以及时间、位置等标签(结构化)。这有助于在不采用正式数据库结构的情况下对数据进行组织。
在文件类型方面,JSON、CSV 和 XML 归为半结构化数据。这些格式能在一定程度上保持组织性,尽管并不完美。因此,虽然没有结构化数据那样整齐,但由于标签与标记,半结构化数据仍具备一定的秩序。
结构化与非结构化数据的并排对比
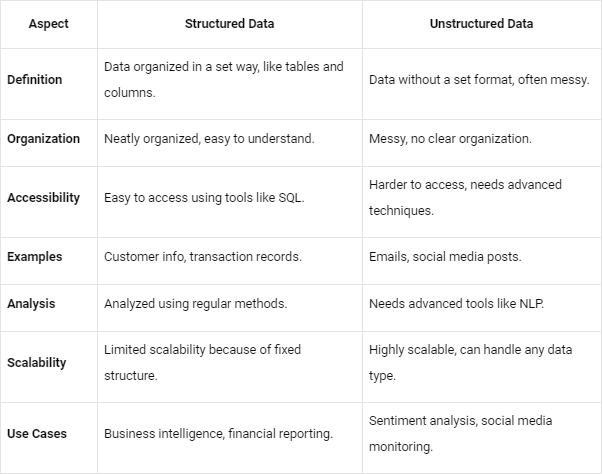
结构化与非结构化数据的关键差异
结构化数据像表格一样整齐,而非结构化数据更像邮件或社交媒体帖子般杂乱。下面我们来看看它们的主要区别。
已定义 vs. 未定义的数据
结构化数据是整齐地保存在行与列中的信息,易于理解和访问。相反,非结构化数据更像是以原始形态保存、没有清晰结构的一堆内容。因此,结构化数据定义明确,可以放入具有特定字段的数据库;而非结构化数据没有固定模型、形态各异、分散无序。
定性 vs. 定量数据
结构化数据类似于数字或可计数的内容,例如客户系统中的数据。它是定量的,因为与数字和统计相关。数据研究者常用回归、分类、聚类等方法去理解它,并据此为业务发现重要信息。
将 Data Journal 的文章发送到你的收件箱
非结构化数据则不同,它更偏向于文字与描述。这类数据来自客户调研、访谈和社交媒体。它比结构化数据更难理解。数据研究者需要使用更先进的数据挖掘与集成(stacking)方法来解析它们。这些方法帮助从非结构化数据中提取有用信息,对企业非常重要。
分析的易用性
一个关键差异在于结构化数据的易分析性。结构化数据非常容易搜索,这对数据分析师和各类算法都很友好。相反,非结构化数据更复杂,通常需要先进行处理才能理解。
用于结构化数据的分析工具非常多。然而,谈到非结构化数据,情况会更棘手。用于整理与分析非结构化数据的工具(如基于自然语言处理 NLP 与机器学习 ML 的工具)仍在发展之中,尚不够成熟,因此这一领域还有很多工作要做。
数据仓库 vs. 数据湖中的数据存储
数据仓库与数据湖是两种不同的企业信息存储方式。在数据仓库中,整洁有序的数据在入库前会经过处理流程。相反,数据湖则像一个大池子,可以把杂乱的数据原样存储,或稍作清洗后再存。
存放在数据仓库中的数据通常更整齐,占用空间更少;数据湖可容纳各种杂乱的信息,可能需要更多空间。
就数据库而言,能很好映射到表结构的结构化数据通常存储在一类数据库中;而杂乱、无序的数据则存储在另一类数据库中。
预定义格式 vs. 多样化格式
结构化数据通常遵循通用格式,主要是文本与数字,且基于预先设定的数据模型进行组织。
然而,非结构化数据则完全不同。它可以以多种形式出现,如音频、视频、图片、电子邮件,甚至传感器数据。非结构化数据没有特定的数据模型,你可以按其原样存储,单独保存或放入数据湖,无需更改。
为什么要管理你的非结构化数据
管理非结构化数据非常重要,因为企业每年都会累积更多数据。这些数据在 30 天后往往不再被访问,我们称之为“冷”数据。这些冷数据会占用昂贵的硬盘空间并推高存储成本。
非结构化数据对企业尤其棘手:难以分类,且难以适配常见的 XML、键值或 JSON 数据库。企业通常需要使用不同的系统来处理这类数据,这意味着需要在系统间搬移数据,从而占用更多存储并增加成本。
一些公司忽视对非结构化数据的管理,而是在主存储系统上不断扩容。但这种做法并不可取:它会耗尽最昂贵的主存储空间,因为主存往往需要高成本的闪存。
此外,企业通常每三到五年需要升级存储系统,并纳入所有非结构化数据。在此过程中必须考虑数据迁移成本以及备份所需的额外存储。
同时,企业还必须遵守全球数据法规。这些法规要求公司检查非结构化数据的内容,尤其是其中是否包含个人信息。
通过有效管理非结构化数据,企业可以提升效率并节省成本。云存储、磁带或其他二级存储选项能更轻松地处理非结构化数据,帮助企业更好地管理数据并控制成本。
结语
作为数据从业者,我想最后再总结一次结构化、非结构化与半结构化数据的关键差异。
先说结构化数据。这类数据包括姓名、地址、信用卡号等。它整齐地存放在数据库表中,便于大数据程序处理。
然后是非结构化数据,截然不同。它包括音频文件、视频、监控数据等。通常按原样存储,直至需要分析。虽然由于格式多样而更具挑战,但必须重视。事实上,它占企业使用的全部数据的 80% 以上,并以每年 55%–65% 的速度增长。
最后是半结构化数据,处于两者之间。它具备一定的组织性(如标签),但无法整齐地融入传统数据库结构。
总之,虽然结构化数据更易于分析,但海量的非结构化数据蕴含着我们正借助新技术逐步解锁的宝贵洞见。我们必须综合利用所有类型的数据,确保不遗漏任何有助于做出更好决策的关键信息。

















 2028
2028

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









