 复旦微软提出MagicMotion可控图生视频框架
复旦微软提出MagicMotion可控图生视频框架





🌐 社群导航
🔗 点击加入➡️【AIGC/LLM/MLLM/3D/自动驾驶】 技术交流群
数源AI 最新论文解读系列

论文名:MagicMotion: Controllable Video Generation with Dense-to-Sparse Trajectory Guidance
论文链接:https://arxiv.org/pdf/2503.16421
开源代码:https://quanhaol.github.io/magicmotion-site/
导读
虽然基于DiT的模型在生成高质量和更长视频方面表现出色,但许多文本到视频方法缺乏对物体运动和相机运动等属性的精确控制。细粒度的轨迹可控视频生成技术应运而生,这对于在现实场景中生成可控视频尤为关键。
简介
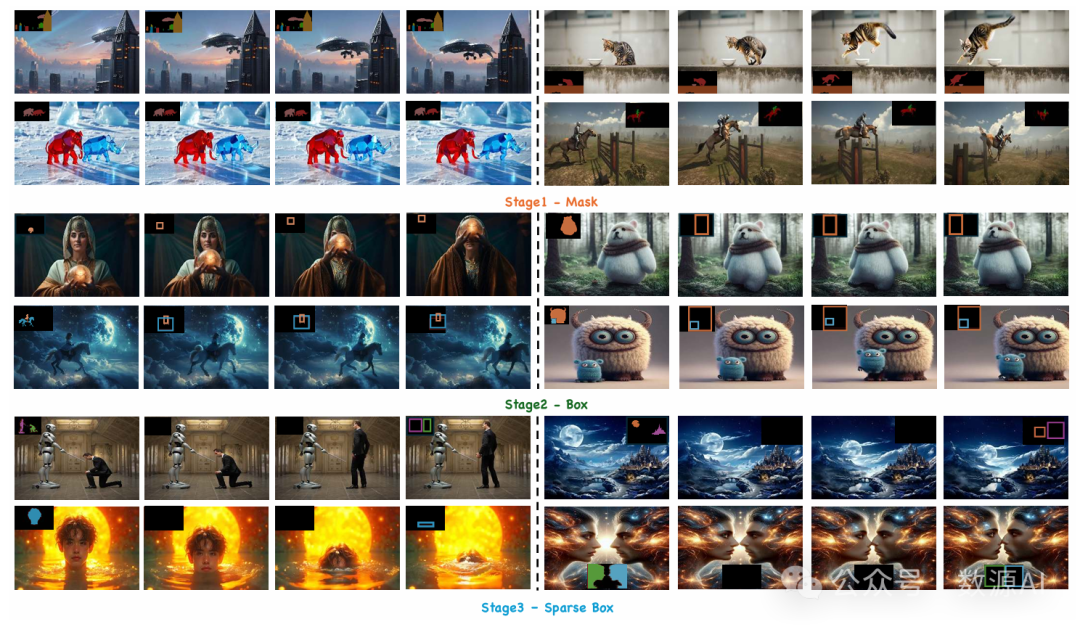
近年来,视频生成技术取得了显著进展,在视觉质量和时间连贯性方面有了显著提升。在此基础上,轨迹可控的视频生成技术应运而生,它可以通过明确定义的空间路径实现对物体运动的精确控制。然而,现有方法在处理复杂物体运动和多物体运动控制时存在困难,导致轨迹跟踪不精确、物体一致性差以及视觉质量受损。此外,这些方法仅支持单一格式的轨迹控制,限制了它们在不同场景中的适用性。另外,目前还没有专门针对轨迹可控视频生成的公开可用数据集或基准,这阻碍了模型的稳健训练和系统评估。为了解决这些挑战,我们提出了魔法运动(MagicMotion),这是一种新颖的图像到视频生成框架,它通过从密集到稀疏的三个级别的条件(掩码、边界框和稀疏边界框)实现轨迹控制。给定输入图像和轨迹,魔法运动可以使物体沿着定义的轨迹无缝动画化,同时保持物体的一致性和视觉质量。此外,我们还推出了魔法数据(MagicData),这是一个大规模的轨迹控制视频数据集,以及一个用于标注和过滤的自动化流程。我们还引入了魔法基准(MagicBench),这是一个全面的基准,用于评估不同数量物体的视频质量和轨迹控制精度。大量实验表明,魔法运动在各种指标上都优于以往的方法。
方法与模型
1. 概述
我们的工作主要聚焦于轨迹可控的视频生成。给定一张输入图像 和若干轨迹图 ,该模型能够生成一个符合所提供轨迹的视频 ,其中 T 表示生成视频的长度。在接下来的章节中,我们首先会在 3.2 节详细解释我们的模型架构。接着,我们会在 3.3 节概述我们的渐进式训练过程。在 3.4 节,我们会引入潜在分割损失(Latent Segmentation Loss),并展示它如何提升模型在细粒度物体形状方面的能力。然后,我们会在 3.5 节描述我们的数据集整理和过滤流程。最后,我们会在 3.6 节深入介绍 MagicBench。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









