



🌐 社群导航
🔗 点击加入➡️【AIGC/LLM/MLLM/3D/自动驾驶】 技术交流群
数源AI 最新论文解读系列

论文名:Neighboring Autoregressive Modeling for Efficient Visual Generation
论文链接:https://arxiv.org/pdf/2503.10696
开源代码:https://github.com/ThisisBillhe/NAR

导读
以自回归“下一标记预测”目标进行训练的大语言模型(Large language models,LLMs)在处理基于自然语言的任务中展现出了前所未有的能力。基于这些进展,许多研究探索了用于视觉生成甚至统一多模态生成的自回归模型。通常,为了将“下一标记预测”范式应用于视觉生成,图像被标记化为图像标记,并按光栅顺序展平为一维视觉标记序列。在推理过程中,模型必须顺序生成数千个标记才能生成一张高分辨率图像,与基于扩散的模型相比,效率显著降低。
简介
视觉自回归模型通常遵循光栅顺序的“下一标记预测”范式,该范式忽略了视觉内容固有的空间和时间局部性。具体而言,与距离较远的视觉标记相比,视觉标记与其在空间或时间上相邻的标记之间的相关性明显更强。在本文中,我们提出了邻域自回归建模(Neighboring Autoregressive Modeling,NAR),这是一种新颖的范式,它将自回归视觉生成表述为一个渐进式的外部绘制过程,遵循从近到远的“下一邻域预测”机制。从一个初始标记开始,其余标记按照它们在时空空间中与初始标记的曼哈顿距离升序进行解码,逐步扩展解码区域的边界。为了实现对时空空间中多个相邻标记的并行预测,我们引入了一组面向维度的解码头,每个解码头沿着相互正交的维度预测下一个标记。在推理过程中,与已解码标记相邻的所有标记都被并行处理,从而显著减少了生成过程中的模型前向步骤。在ImageNet 和UCF101上的实验表明,NAR分别实现了 和 的更高吞吐量,同时在图像和视频生成任务中与PAR - 4X方法相比,获得了更优的FID/FVD分数。在文本到图像生成基准GenEval上进行评估时,参数为0.8B的NAR在仅使用0.4%训练数据的情况下,性能优于Chameleon - 7B。
方法与模型
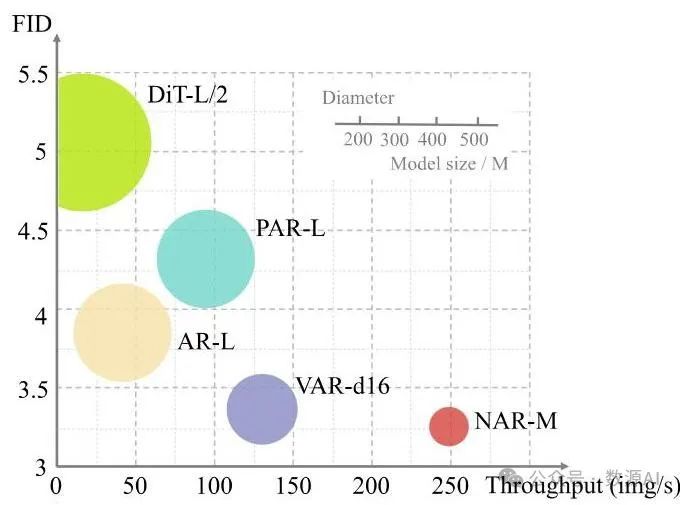
图 2. 各种视觉生成方法之间的生成质量和效率比较。数据是从 ImageNet 数据集上参数约为 的模型收集的。

图 3. 不同自回归视觉生成范式的比较。所提出的 NAR 范式将生成过程表述为一个外扩绘制过程,逐步扩展已解码标记区域的边界。这种方法有效地保留了局部性,因为在当前标记之前,起始点附近的所有标记始终会被解码。
1. 相邻自回归建模
受图像外扩绘制方法 [26, 38] 的启发,我们提出了一种关于自回归视觉生成的新视角。如图 3(e)-(f) 所示,我们的方法将该过程框架化为一个从头开始的外扩绘制过程,逐步扩展已解码标记区域的边界。在每个生成步骤中,预测与已解码标记相邻的所有标记,从而形成相邻自回归建模(NAR)范式。该范式有效地保留了局部性,因为在当前标记之前,始终会对起始点附近的所有标记进行解码。
然而,这种配置给以预测下一个标记(Next-Token Prediction,NTP)为目标训练的模型带来了重大挑战,因为在不同维度可能存在多个等距标记,但每一步只能生成一个标记。尽管某些方法允许在NTP框架内进行并行解码,但当同时预测过多标记时,其性能会显著下降。如表4中的实验结果所示,直接将非自回归(Non-Autoregressive,NAR)范式与下一个标记预测目标相结合会导致性能大幅下降。我们认为这个问题的产生是因为原始模型仅被训练用于按光栅顺序预测下一个标记的条件分布,而待预测的多个位置的标记分布可能会有很大差异。
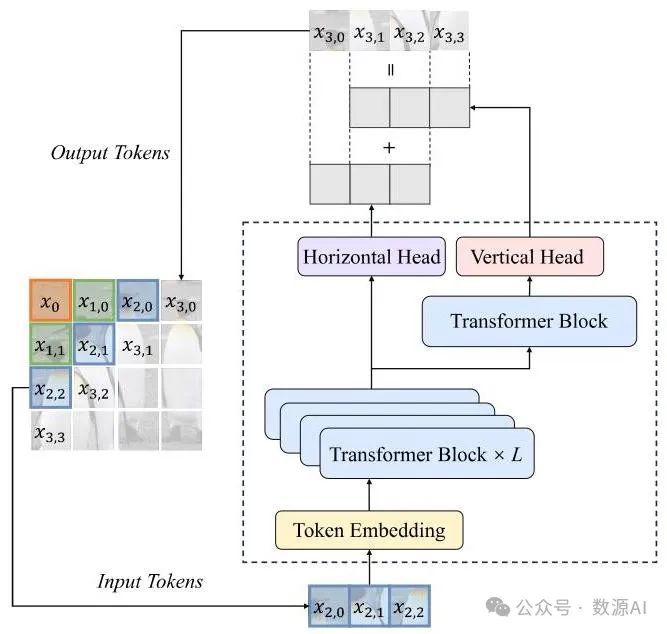
图4. 面向维度的解码头示意图。水平头和垂直头分别负责预测行和列维度中的下一个标记。这里,是骨干网络中Transformer块的数量。
为了解决这个问题,我们提出了面向维度的解码头,这是一种简单而有效的方法,用于对并行解码标记的不同条件分布进行建模。如图4所示,额外的解码头由一个Transformer块和一个全连接输出层组成,它们与Transformer骨干网络相连,以便沿着几个相互正交的维度进行并行解码。例如,图像可以被视为二维的,允许沿着两个正交维度进行解码:行和列。因此,我们为图像生成模型应用两个面向维度的解码头,每个头对一个维度中下一个标记的条件分布进行建模,即同一行中的下一个标记和下一行中同一列的标记。我们的方法也可以自然地扩展到视频生成。由于视频可以被视为三维的,即在图像的基础上增加了一个时间维度,因此可以沿着三个正交维度进行解码:时间、行和列。这种解耦设计避免了单个头预测多个混合条件分布,从而显著提高了生成性能。
2. 非自回归(NAR)的实现细节
使用非自回归(NAR)进行推理。通过使用一组解码头沿着多个维度预测下一个标记,我们可以在一次前向传播步骤中自然地预测已生成标记的所有相邻标记。具体来说,解码过程从位于图像特征图左上角的初始标记开始,与光栅扫描顺序一致。在后续步骤中,将上一步生成的标记输入到模型中,以自回归方式生成新的标记,如图4所示。对于每个输入标记,使用面向维度的头生成其在行和列维度上的两个相邻标记。值得注意的是,从第三步开始,输入标记的两个预测相邻标记之间会有重叠,例如图4中的和。在这种情况下,我们对重叠标记混合不同解码头的预测结果,类似于模型集成方法[30]。表5中的实验结果表明,与仅依赖单个解码头的预测相比,这种方法持续提高了生成性能。
形式上,给定初始标记,在步骤生成的所有标记的集合可以定义为:
其中表示曼哈顿距离。通过这种生成范式,非自回归(NAR)在步内生成具有个标记的高分辨率图像。对于由个标记表示的视频,非自回归(NAR)仅需步即可完成生成过程,显著少于普通的下一个标记自回归(AR)模型所需的步。
使用非自回归(NAR)进行训练。训练一个非自回归(NAR)模型与普通的下一个标记自回归(AR)模型共享相同的图像分词器和训练流程,只需要对模型架构和注意力掩码进行微小修改。与之前的自回归(AR)图像生成方法[44, 47]类似,所有解码头都使用交叉熵损失进行训练,沿着不同维度预测下一个标记。由于标记的解码顺序由它们与初始标记的接近程度决定,因此在解码过程中,离初始标记较远的标记仅依赖于离它较近的标记。因此,在训练非自回归(NAR)模型时采用了一种考虑接近度的因果注意力掩码,如图5所示。值得注意的是,在与初始标记距离相等的标记之间应用了双向注意力,以确保并行生成过程中具有更好的一致性。
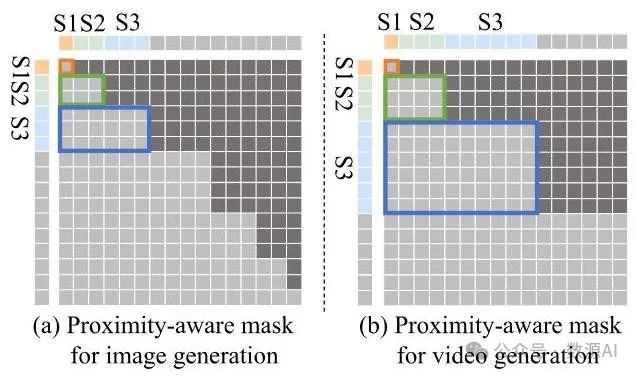
图5. 非自回归(NAR)范式的近邻感知注意力掩码。“S ”表示第个生成步骤。同一步骤内生成的标记用相同颜色表示。为了保持自回归特性,在不同生成步骤的标记之间应用因果掩码(与图3一致)。在每个步骤内,标记之间采用双向注意力,以增强并行生成过程中的一致性。
与变分自回归(VAR)范式相比,所提出的非自回归(NAR)范式显著降低了训练开销。首先,变分自回归(VAR)需要一个专门的多尺度分词器,该分词器需要大量数据进行训练才能达到最佳性能。相比之下,我们的方法可以利用开源社区中各种高性能的图像分词器。其次,变分自回归(VAR)的标记序列是通过连接多个尺度的视觉标记构建的,这比非自回归(NAR)中使用的单尺度视觉标记序列长得多。序列长度的减少显著降低了训练过程中的计算复杂度,因为复杂度与序列长度呈二次方关系。
实验与结果
1. 实验设置
模型架构。为了验证所提出的非自回归(NAR)范式的有效性和可扩展性,我们采用了仅解码器的Transformer架构,遵循先前的研究。通过实现面向维度的解码头,我们的非自回归(NAR)方法本质上适用于二维图像和三维视频生成,分别使用两个和三个解码头。类别条件图像生成。我们在广泛使用的ImageNet数据集上评估非自回归(NAR)方法。使用[44]引入的现成图像分词器对图像进行分词,下采样因子为16。所有模型都以的基础学习率和步长学习率调度器进行300个周期的训练。报告的Inception分数(IS)和Fréchet Inception距离(FID)结果是通过采样50,000张图像并使用ADM的TensorFlow评估套件[11]进行评估计算得出的。
类别条件视频生成。NAR在UCF - 101数据集[43]上进行训练和评估。我们采用了[54]提出的视频分词器,它将一个视频片段编码为个视觉标记。模型以的基础学习率训练3000个轮次,并使用步长学习率调度器。弗雷歇视频距离(Frechet Video Distance,FVD)[51]作为生成任务的主要评估指标。
文本到图像生成。我们从LAION - COCO [1]数据集和使用大型视觉 - 语言模型标注的开源高分辨率图像中精心挑选了一个包含400万图像 - 文本对的数据集[56]。采用了由[44]提出的在LAION - COCO上微调的图像分词器,下采样因子为16。使用预训练的FLAN - T5模型[8]提取文本嵌入,作为图像生成的条件输入。遵循先前的工作[44],训练过程分为两个阶段。在第一阶段,模型在400万LAION - COCO子集上以的分辨率训练60个轮次。在第二阶段,模型在高质量数据集上以的分辨率微调40个轮次。两个训练阶段均使用余弦退火学习率调度器。采用GenEval [15]作为公平且细粒度的基准进行比较。
2. 主要结果
2.1. 类别条件图像生成
在本小节中,我们评估了NAR模型在ImageNet 数据集上的性能,如表1所示。为了进行公平比较,我们采用了与LlamaGen [44]和PAR [58]相同的图像分词器、模型架构和训练流程。所使用的图像分词器仅有个参数,它仅在ImageNet数据集上进行训练,重建FID(rFID)为2.19。尽管之前的并行解码方法PAR与LlamaGen的标准下一个标记预测范式相比提高了生成效率,但其FID在相同模型大小下始终高于LlamaGen。相比之下,采用NAR范式的模型表现出更优的性能和效率。例如,具有3.72亿参数的NAR - L比具有14亿参数的LlamaGen - XXL实现了更低的FID(3.06对3.09),同时将模型前向传播步数减少了(31步对256步),并实现了更高的吞吐量(195.4张图像/秒对14.1张图像/秒)。
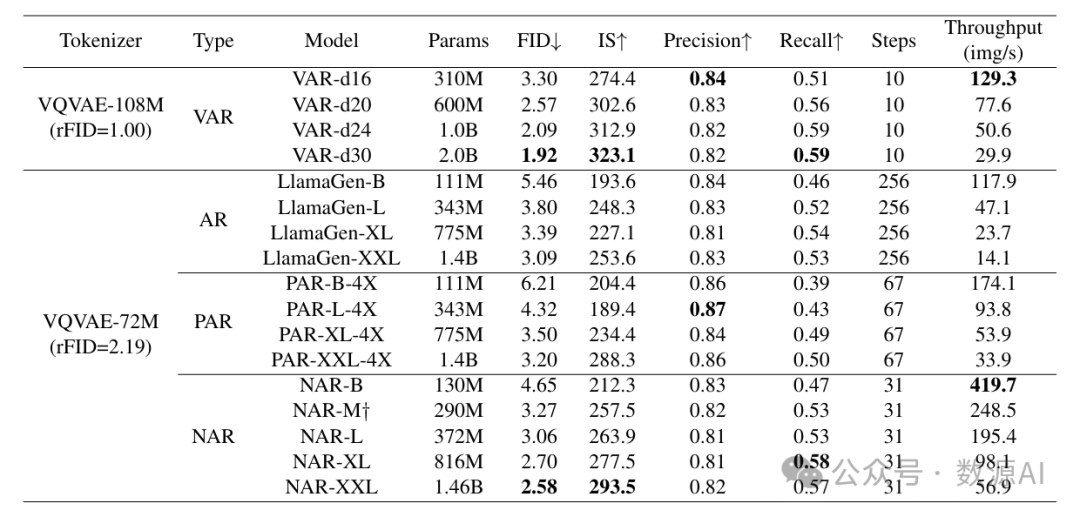
另一方面,VAR方法[47]采用了一个具有个参数的更大的图像分词器,它在大规模OpenImages数据集[22]上进行训练。这个分词器的重建FID(rFID)为1.00,为生成性能提供了更高的上限。尽管如此,参数更少的NAR - M比VAR - d16实现了更低的FID(3.27对3.30),同时提供了更高的吞吐量(248.5张图像/秒对129.3张图像/秒)。将NAR与更先进的图像分词器相结合将留作未来工作。
2.2. 类别条件视频生成
在本小节中,我们使用UCF - 101数据集[43]评估非自回归模型(NAR)在基于类别的视频生成中的有效性。如表2所示,我们的NAR模型通过显著减少生成步骤和实际耗时,同时实现更低的FVD(弗雷歇视频距离),超越了其他自回归模型。与采用相同视频分词器且参数数量相当的LARP - L - Long模型[54]相比,我们的NAR - L模型进一步提高了生成质量,将FVD降低了5.8,生成延迟降低了。此外,与专为并行生成设计的PAR模型[58]相比,我们的NAR - XL模型始终表现更优,FVD降低了,且无需进行超参数调整。总体而言,我们提高了自回归范式在图像/视频生成中的可扩展性,使其在使用更少参数和更低延迟的情况下,与基于扩散的和基于掩码的方法相媲美。
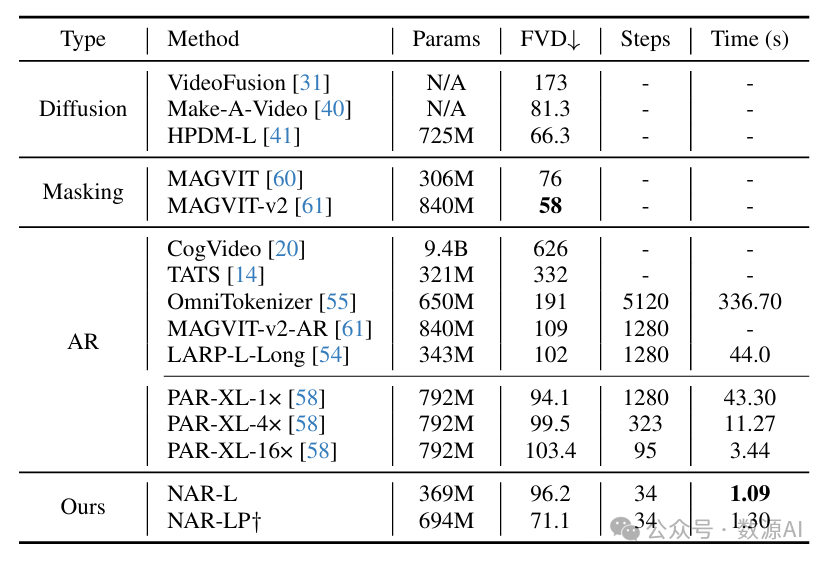
2.3. 文本到图像生成
为了验证NAR在文本引导图像生成中的有效性,我们训练了一个文本引导的NAR - XL模型,并在GenEval基准测试[15]上评估其性能,具体结果见表3。仅在600万个公开可用的文本 - 图像对上训练的NAR - XL模型,在GenEval基准测试中显著优于LlamaGen - XL模型[44](得分分别为0.43和0.32),尽管它仅使用了10%的训练数据,且吞吐量提高了。此外,NAR模型的总体得分超过了Chameleon模型[45],Chameleon是一个基于自回归的视觉生成模型,有70亿个参数,在14亿个文本 - 图像对上进行训练。与基于扩散的模型SDv1.5[37]相比,NAR在仅使用的训练数据的情况下实现了相当的性能。这些结果强调了NAR范式在使用最少训练数据的情况下生成高质量图像的能力。

补充材料中提供了展示类别条件图像生成、视频生成和文本引导图像生成的定量可视化结果。
3. 部署效率
在本小节中,我们详细比较了各种自回归生成范式的效率,评估了具有相似FID(弗雷歇初始距离)分数的模型的延迟、内存使用和吞吐量。如图6(a)所示,在生成延迟方面,当批量大小小于32时,VAR - d16的延迟低于NAR - M和LlamaGen - L。这可归因于原始下一个标记自回归和NAR范式在解码过程中的内存瓶颈。然而,随着批量大小的增加,NAR - M的延迟显著降低。例如,当批量大小为256时,与VAR - d16相比,NAR - M的延迟降低了(分别为1.13秒和2.02秒)。此外,如图6(b)所示,对于相同的批量大小,NAR - M始终比VAR - d16需要更少的GPU内存,这是由于NAR的序列长度更短。因此,在相同的硬件上,NAR范式可以容纳更大的批量大小,从而实现更高的吞吐量,如图6(c)所示。例如,在具有80GB显存的A100 GPU上,VAR - d16在推理期间支持的最大批量大小为256,每秒可生成129.3张图像。相比之下,NAR - M支持的批量大小为512,每秒可生成248.5张图像,比VAR - d16的吞吐量高92.1%。与原始下一个标记自回归模型LlamaGen - L相比,NAR - M在实现更优FID的同时,吞吐量提高了。这些结果凸显了NAR范式在延迟、内存使用和吞吐量方面的效率优势,使其成为高性能和高效图像生成的理想选择。
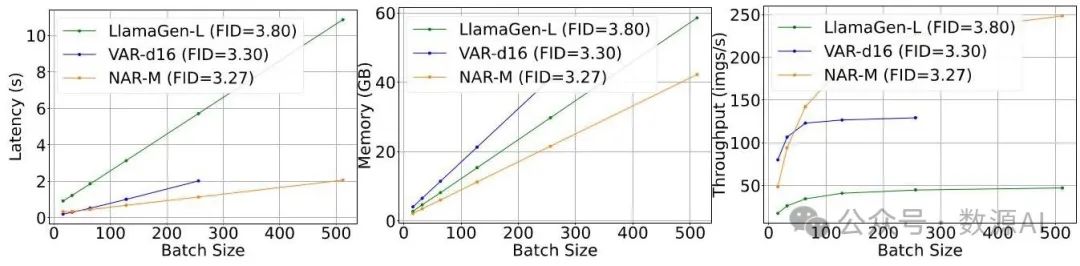
图6. 普通自回归(AR)、向量自回归(VAR)与所提出的非自回归(NAR)视觉生成范式之间的效率比较。当批量大小大于64时,NAR能以更低的延迟、更少的内存使用和显著更高的吞吐量实现更低的弗雷歇 inception 距离(FID)。
4. 消融实验
面向维度的解码头的效果。我们通过将所提出的面向维度的解码头的性能与采用单个头并行预测所有相邻标记的基线方法进行比较,来评估其有效性。为了进行公平比较,所有模型都使用相同的流程和超参数进行训练。如表4所示,没有面向维度的解码头的NAR - L(无维度导向解码头的非自回归语言模型)与具有下一个标记预测目标的LlamaGen - L(大语言模型生成器)相比,性能明显较差,导致FID(弗雷歇 inception 距离)显著提高至66.31。这种性能下降可归因于单个解码头无法充分捕捉不同位置的不同标记分布,对于空间距离较远的标记,这些分布可能会有很大差异。相比之下,配备了所提出的面向维度的解码头的NAR - L实现了显著更低的FID,为3.06,同时将模型前向步骤的数量减少了87.8%(从256步减少到31步)。这一改进凸显了面向维度的解码头在提高生成质量和效率方面的有效性。
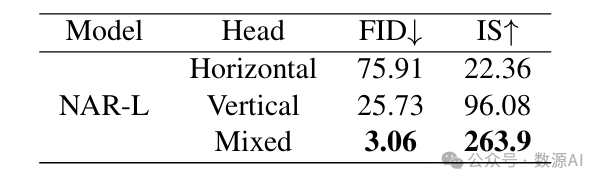
混合逻辑采样的效果。如图4所示,不同维度导向的解码头预测的相邻标记之间存在重叠。在推理过程中,这些重叠的标记可以从单个解码头的预测中采样,也可以从多个解码头的预测组合中采样。我们评估了各种解码头配置对类别条件ImageNet 基准测试的影响,结果如表5所示。结果表明,与仅依赖单个解码头相比,结合多个解码头的预测显著提高了生成质量。这一改进体现在FID(弗雷歇 inception 距离,Frechet Inception Distance)显著降低至3.06,IS( inception 得分,Inception Score)提高至263.9。


结论
在本文中,我们提出了邻域自回归建模(Neighboring Autoregressive Modeling,NAR),这是一种用于高效、高质量视觉生成的新型“邻域预测”范式。为了便于对多个等距令牌进行并行解码,我们提出了一组面向维度的解码头,每个解码头负责在时空空间中沿着相互正交的维度预测下一个令牌。在推理过程中,我们的方法能够在单个前向步骤中预测生成令牌的所有相邻令牌,显著减少了自回归视觉生成所需的模型前向步骤数量。大量实验结果表明,NAR在图像和视频生成任务中实现了最先进的生成质量和效率的平衡。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









