







-
第一章 绪论
-
1.1 自然语言处理的概念
- 自然语言处理主要研究用计算机理解和生成自然语言的各种理论和方法,属于人工智能领域的核心分支。
-
1.2 自然语言处理的难点
-
1.2.1 抽象性
- 符号—>具体事物
-
1.2.2 组合性
- 组成形式过多,总数庞大
-
1.2.3 歧义性
- 一词多义
- 句子形式不同,但语义相同
-
1.2.4 进化性
- 新词诞生(新冠)
- 旧词翻新
-
1.2.5 非规范性
- 错别字
- 简写
- 同音转换
-
1.2.6 主观性
- 标准不统一
-
1.2.7 知识性
- 背景(生活常识),推理
-
1.2.8 难移植性
- 领域众多,差异较大
-
-
1.3 任务体系
-
1.3.1 层级
-
-

-
-
-
1.3.2 任务类别
- 回归
- 文本—>连续数值(作文评分)
- 分类(文本分类)
- 匹配(文本关系)
- 文本相似度检测(查重)
- 解析
- 文本标注
- 生成
- 根据输入要求,输出自然语言
- 回归
-
1.3.3 研究对象
-
-
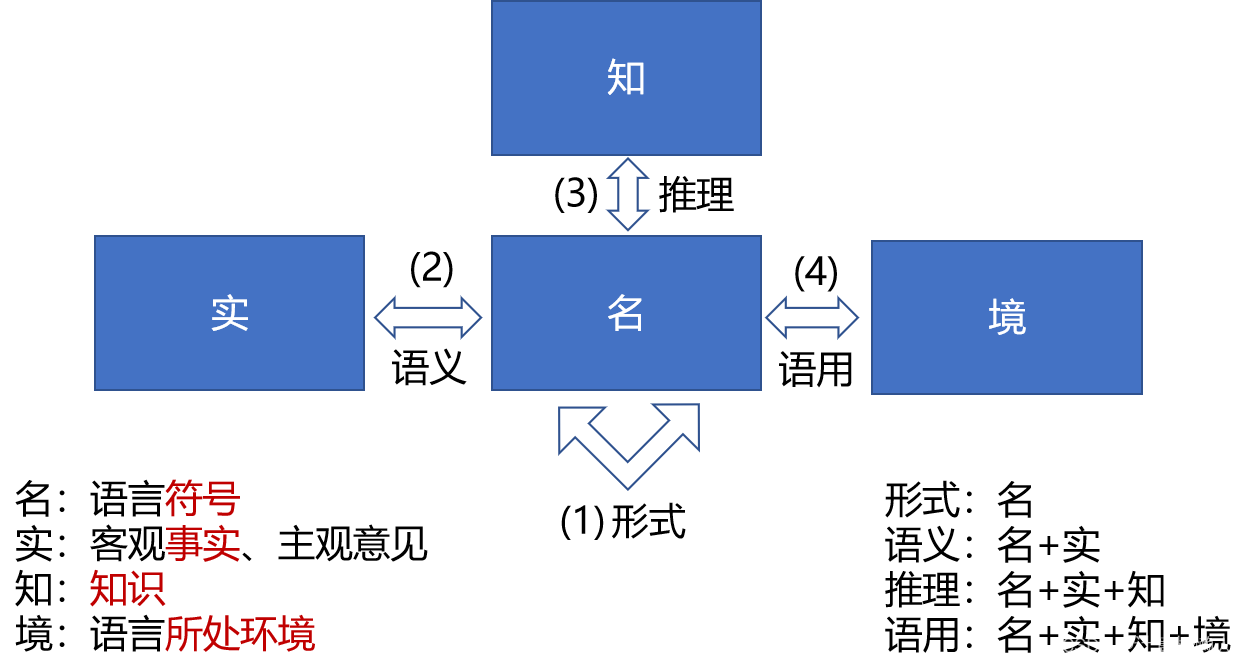
-
-
1.4 发展历史
- 统计学习——>深度学习——>模型预训练
-
-
第二章 自然语言处理基础
-
2.1 文本的表示
-
2.1.1 独热表示(独热编码)
- 概念:用一个词表大小的向量表示一个词,将词表中第i个词表示为向量,其中,第i个词的第i个数为1,其他位为0
- 缺点:1.语义相似,但是经过数学计算后,结果完全不同。2.数据稀疏:同义词众多,数据不完全。3.基于第二点,数据挖掘费时费力。
-
2.1.2 分布式表示
-
2.1.2.1 分布式语义假设
- 根据上下文, 对词表示(计算词出现频次)
- 缺点:因为高频共现,将原本无关联的词产生关联;只能分析直接关系,无法反应高阶关系;数据稀疏问题仍在
-
2.1.2.2 点互信息(针对上述缺点之一的高频误判问题)
- 点互信息:对词和上下文进行整体计算,得出PMI值。
-
-
-
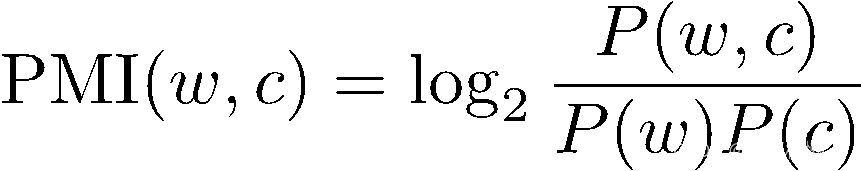
- 公式中,P(w,c)、P(w)、P(c)分别是w和c的共现频率,以及w和c分别出现的概率。
- PMI并不一直处于稳定,常用PPMI的形式。PPMI(w,c) =max(PMI(w,c),0)。
- 最大似然估计(MLE),可以计算上述概率值。
-
2.1.2.3 奇异值分解(针对上述缺点之一的无法反映高阶关系问题)

- 截断奇异值分解(对矩阵M的低秩近似): 在∑中仅保留d个(d<c)最大的奇异值(U和V也只保留相应的维度)。
-
2.1.2.4 分布式缺点
- 共现矩阵规模大时,奇异值分解速度很慢。
- 如果想要增加语料库的内容,需要重新进行分解,代价很大。
- 分布式无法有效表示长句(可以使用词袋)。
- 分布式一旦完成,无法修改。
-
2.1.3 词嵌入表示
- 共同点:连续,低维,稠密(和词的分布式特点类似)
- 不同点:赋值方式(向量值自行调整,可修改)
- 潜在语义索引:将文本与文档进行相似度判断,也是使用截断奇异值分解进行降维。
- 潜在语义分析:通过截断奇异值分解所得到的矩阵U的每一行就是对应词的d维向量表示,该向量一般具有连续、低维和稠密的性质。
-
-
2.1.4 词袋表示
- 词袋:无顺序的词的集合,将词用向量表示。
- 缺点:忽略词的顺序,产生误差;无法融入上下文
-
2.2 自然语言处理任务
-
2.2.1 语言模型(N元语言模型和神经网络语言模型)
-
2.2.1.1 N元语言模型
- 语言模型基本任务:基于之前出现的词,预测下一个出现的词。结合基本任务,将基本任务放大,便可以预测一句话的出现。利用条件概率进行计算,但是为了防止下一个词的出现概率几乎为0时,提出假设。
- 马尔可夫假设:下一个词出现的概率只取决于它前面的n-1个词(不在选取前面所有词作为依据,降低概率为0的可能性)
- N元文法(N元语法):满足马尔科夫假设。
-
2.2.1.2 平滑算法(折扣法)
- 加1平滑(拉普拉斯平滑):假设所有N元语法的频次比实际多一次。
- 加δ平滑(多δ次,0<=δ<=1):更自然,防止对低频词或零频次的事件过高估计。
-
2.2.1.3 语言模型性能评价
- 利用困惑度(PPL)来评价。
- 通过训练集和测试集计算PPL(若PPL越小,语言模型更有效)。
-
-

-
- 缺点:切分歧义问题(倾向于切分出长词);词定义不统一;词典无法收录全部词语。
-
2.2.2 基础任务
-
2.2.2.1 中文分词
- 词:最小的能独立使用的音义结合体,能够独立运用并能够表达语义或语用内容的最基本单位。
- 中文分词最简单的分词算法:正向最大匹配(FMM)分词算法。
- sentence为待分词的句子;lexicon为词典(所有单词的集合);max_len为词典中最长单词长度。
-
-
- 缺点:切分歧义问题(倾向于切分出长词);词定义不统一;词典无法收录全部词语。
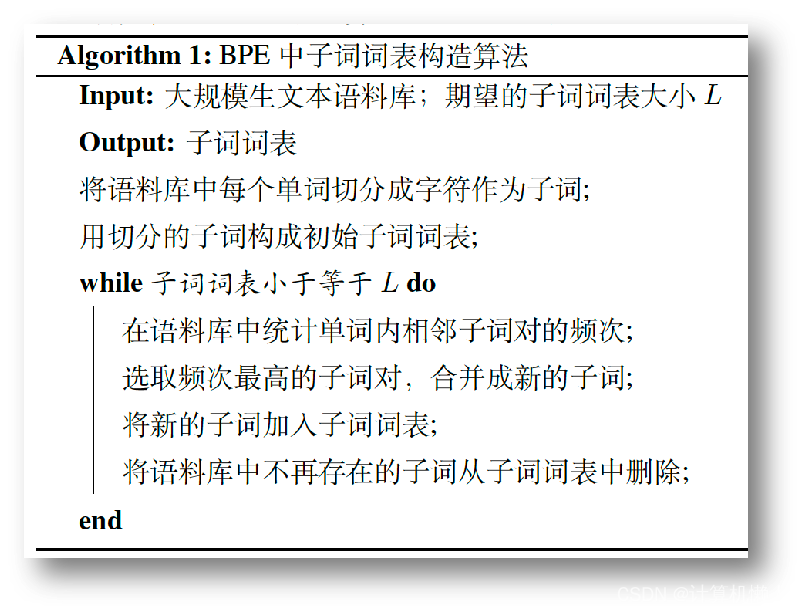
- 将单词依次进行切分,对每一个单词都进行一次子词词表检索,当子词是单词的子串是,对单词进行切分,若单词还有子串没被切分,对这些子串进行标记(用<UNK>替换)。
-
2.2.2.2 子词切分(字节对编码算法,BPE)
- 针对问题:印欧语系(英语)切分困难,因其单词形式变化莫测,无法通过简单的规则进行切分,反倒会产生其他困难。
- 基本原理:使用尽量长且频次高的子词对单词进行切分。
- BPE通过算法2.1构造子词词表。(为切分提供依据)
-
2.2.2.3 词性标注
- 对句子中的每一部分标注词性。
- 难点:根据上下文,同一个词的词性可能不同。
-
2.2.2.4 句法分析
- 分析句子成分,标注主谓宾定状补成分。
- 将词序列表示的句子转换成树状结构,助于理解含义,方便下游自然语言处理任务。
-
2.2.2.5 语义分析(通过离散的符号和结构表明语义)
- 词义消歧:根据词语出现的不同上下文,确定词语的具体含义。
- 语义角色标注:先识别谓语,为谓语确定所表达的意思,再识别其他语言成分,最后针对意思输出句子语义。
- 语义依存分析:利用图来对语义进行阐释。(语义依存图或概念语义图)
-
-
2.2.3 应用任务
-
2.2.3.1 信息抽取(从非结构化文本中提取结构化信息)
- 命名实体识别(搜索并提取文章中出现的被寻找词语,注明类型),实体链接(将文本实体与知识库中的具体实体相对应)
- 注:实体链接与词义消歧类似,但二者的最终目标和对象并不同。实体链接的对象是自然语言文本中表示实体的词语;词义消歧的对象是一个多义词在特定上下文中的正确意义。实体链接的目标是将词语实体与知识库链接,比如将词语和百度的解释相对应;词义消歧的目标是确定一个多义词在文本中的精确意思。
- 事件抽取(与语义角色标注任务类似):根据触发词提取关键信息,尤其是时间(时间表达式:提取的时间文本;时间表达归一化:将时间精确到特定时间)等信息。
-
2.2.3.2 情感分析
- 情感分类:对情感类型和程度进行识别。
- 情感信息抽取:抽取文本中有关表达情感的词汇、对象和对应关系。
-
2.2.3.3 问答系统
- 检索式问答系统(百度知道、Google);知识库问答系统(Wolfram Alpha、Freebase);常问问题集问答系统(企业客服、政府网站自动回复);阅读理解式问答系统(chatGPT)。
-
2.2.3.4 机器翻译
- 利用计算机,实现从源语言到目标语言的转变。
- 研究方法:(基于规则、语料库的方法)——>(基于深度学习,利用深度神经网络学习隐规则)
-
2.2.3.5 对话系统
- 自然语言为载体,用户与计算机进行交互,达到目的的智能系统。
- 开放域对话系统:社交为目的的系统。
- 任务型对话系统:具有明确任务,例如告知天气情况,车票查询。
- 自然语言理解:分析语义。
- 对话管理:对当前对话进行跟踪,判断用户现在的状态和预测即将想做的事情,并提前准备。
- 自然语言生成:语言生成,语音合成。
-
- 缺点:依据上述过程,发现对每一个单词进行切分时,都要重新检索子词词表,非常耗时。
-
2.3 基本问题
-
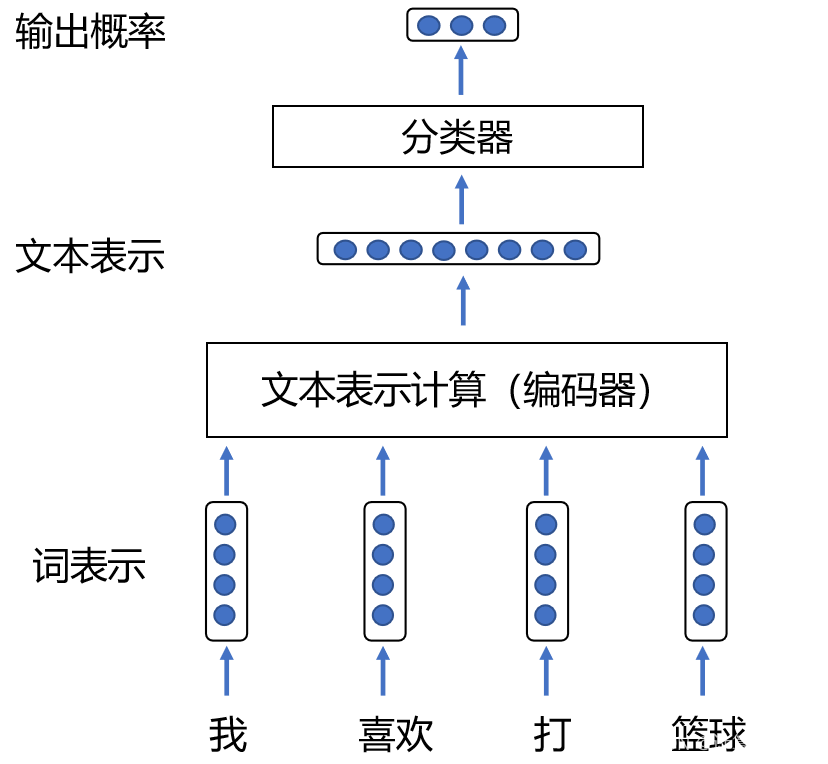
2.3.1 文本分类
- 过程:输入文本,输出文本所属的类别。
-
-
-
-
-
- 技术:利用文本表示技术,将文本转化为特征向量,再将特征向量与类别进行匹配,得出具体类别。
- 周边问题:文本匹配、复述、蕴含,都是先对文本进行分类处理,再进行匹配、相似性判断、包含关系判断等操作。
-
2.3.2 结构预测
-
2.3.2.1 序列标注
- 将输入文本序列中的每个词标注相应标签(与词性标注相同)
-
-
-

-
-
-
-
- 条件随机场模型,能够更好的利用上下文,计算每一个词属于某一标签的概率,并计算每一个标签之间的相互关系。
-
2.3.2.2 序列分割
- 将文本序列中的子序列切出,完成其他操作。
-
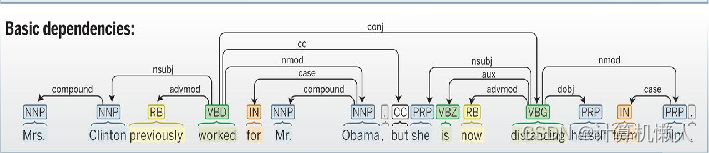
2.3.2.3 图结构生成
- 将图标代替自然语言,表达相同含义。
-
-
-
-
-
-
-
- 基于图的算法:通过赋值给图中两点之间的线段,来完成算法最后的结果。
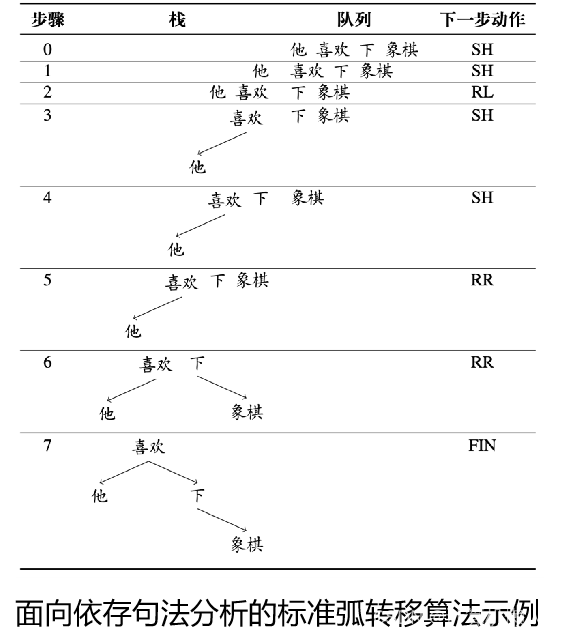
- 基于转移的算法:将图结构的创建过程转化为一个状态转移序列(从旧转移到新)。
- 三种转移动作
- 移进,SH:将队列中的第一个元素移入栈顶,形成一个仅包含一个节点的依存子树。
- 左弧归约,RL:将栈顶的两颗依存子树采用一个左弧S1<—S0进行合并,然后S1下栈。
- 右弧归约,RR:将栈顶的两颗依存子树采用一个左弧S1—>S0进行合并,然后S0下栈。
-
-
-
-
-
-
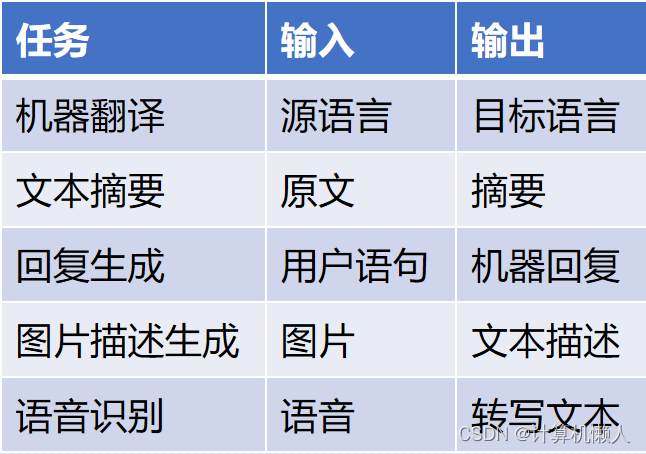
2.3.3 序列到序列问题
-
-
-
-
-
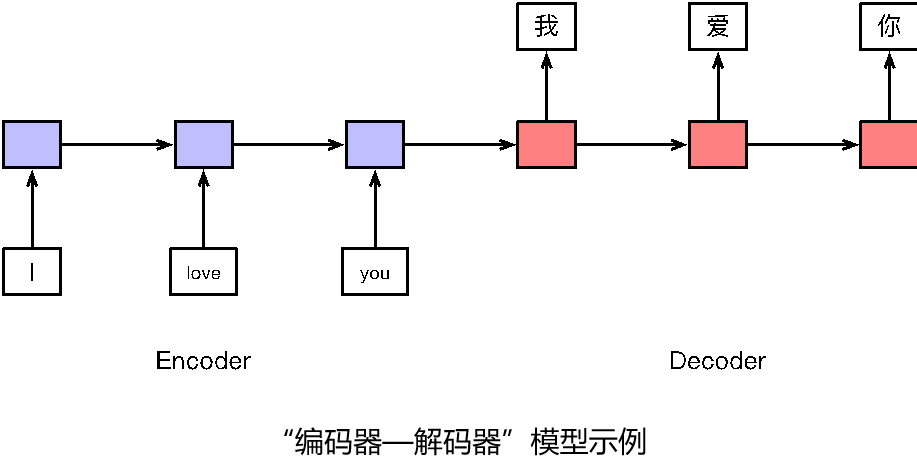
- 序列到序列模型(编码器—解码器模型)
- 序列到序列模型(编码器—解码器模型)
-
-
-
-
2.4 评价指标
- 准确率(文本分类)
- 准确率(文本分类)
-

-
-
- 准确率(序列标注)
- 准确率(序列标注)
-

-
-
- F值评价指标(精确率和召回率的加权调和平均)
- β是加权调和参数,P是精确率,R是召回率。
- F值评价指标(精确率和召回率的加权调和平均)
-
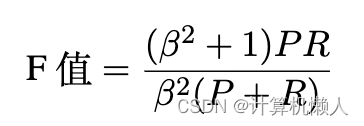
-
-
-
- 在命名实体识别中,P和R的定义。
-
-




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











