







 本文围绕Python列表展开,介绍了列表数据类型,包括获取表项、负数索引、切片等操作,还阐述了列表的使用方法,如用于循环、in和not in操作符等。同时讲解了列表的增强赋值、方法,对比了可变和不可变数据类型,介绍了元组及类型转换,最后通过康威生命游戏展示列表应用。
本文围绕Python列表展开,介绍了列表数据类型,包括获取表项、负数索引、切片等操作,还阐述了列表的使用方法,如用于循环、in和not in操作符等。同时讲解了列表的增强赋值、方法,对比了可变和不可变数据类型,介绍了元组及类型转换,最后通过康威生命游戏展示列表应用。
4.1 列表数据类型
列表简单来说就是包含一个及以上个数的值的序列,用逗号间隔,用中括号包含([])。列表值不是指列表中众多数据的值,而是列表本身整体的值。例如:
spam = ['cat', 'bat', 'rat', 'elephant'] 将众多数据赋值给spam列表类型,当要求输出spam变量时,会输出:
['cat', 'bat', 'rat', 'elephant'] 即可得知,列表数据类型变量输出时,将列表值输出,而不是列表中的表项。
4.1.1 获取表项
以上面的spam变量来说,spam[0]代表‘cat’,spam[1]代表‘bat’,依次可知列表的序号从0开始,此例中有4个数据,则序号从0-3。如下:
>>> spam = ['cat', 'bat', 'rat', 'elephant']
>>> spam[0]
'cat'
>>> spam[1]
'bat'
>>> spam[2]
'rat'
>>> spam[3]
'elephant'
>>> ['cat', 'bat', 'rat', 'elephant'][3]
'elephant'
❶ >>> 'Hello, ' + spam[0]
❷ 'Hello, cat'
>>> 'The ' + spam[1] + ' ate the ' + spam[0] + '.'
'The bat ate the cat.'在序号1,2处,“+”号在之前的章节中有所介绍,表示字符之间的连接,而spam[0]表示字符‘cat’,所以两者连接变成‘Hello,cat’。
注意:
1.列表中若有n个数据,则列表序号从0-(n-1),不能超过n-1的范围,否则程序将会报错。
2.列表序号只能是int类型,即整数,浮点数(如,1.0)不能当作序号,否则程序将会报错。
另外,列表也可以进行嵌套,即列表也可以包含列表,如下:
>>> spam = [['cat', 'bat'], [10, 20, 30, 40, 50]]
>>> spam[0]
['cat', 'bat']
>>> spam[0][1]
'bat'
>>> spam[1][4]
50spam变量中包含两个列表值,分别是[‘cat’,‘bat’]和[10,20,30,40,50]。若spam[0],则表示spam变量中第一个表项,则为[‘cat’,‘bat’]。若spam[0][1],则是spam变量中第一个表项(列表)中的第二个表项,为‘bat’,以此类推。
4.1.2 负数索引
负数索引和普通索引大致相同,一个从-1开始递减,从列表尾部开始,一个从0开始,从列表头部开始。负数索引,即-1,-2等以1递减,从列表的倒数第一个数据开始读取。以上例(四个单词的spam变量,cat等),spam[-1],则代表spam变量中列表的最后一个数据,即‘elephant’。如下:
>>> spam = ['cat', 'bat', 'rat', 'elephant']
>>> spam[-1]
'elephant'
>>> spam[-3]
'bat'
>>> 'The ' + spam[-1] + ' is afraid of the ' + spam[-3] + '.'
'The elephant is afraid of the bat.'
4.1.3 切片得子列表
有的时候,我们想要在列表中选取几个相连的数据,而使用索引太过于繁琐,所以就要利用到切片。切片,可以在列表中任意截取一段数据,作为原列表的子列表。如下:
>>> spam = ['cat', 'bat', 'rat', 'elephant']
>>> spam[0:4]
['cat', 'bat', 'rat', 'elephant']
>>> spam[1:3]
['bat', 'rat']
>>> spam[0:-1]
['cat', 'bat', 'rat']对于两个索引来说,若都是>0,则[m:n]的切片序号范围为[m,n),即大于等于m,且小于n(小于等于n-1)。若第二个索引出现<0,如[0:-1],则范围为[m,n+4),即[0:-1]相当于[0:3]。
当然,有些时候两个索引也是可以隐藏的,可以作为默认条件。如下:
>>> spam = ['cat', 'bat', 'rat', 'elephant']
>>> spam[:2]
['cat', 'bat']
>>> spam[1:]
['bat', 'rat', 'elephant']
>>> spam[:]
['cat', 'bat', 'rat', 'elephant']1.隐藏第一个索引,即[:2],默认从0开始,范围[0,2)。
2.隐藏第二个索引,即[1:],默认到列表结尾,范围[1,4)。
3.两个索引全部隐藏就是代表切片整个列表,即列表本身,范围[0,4)。
4.1.4 len()函数
len()函数可以用来测量列表长度,即列表中表项的个数,如同len()函数测量字符串中字符个数一样。如上述spam变量,即len(spam)=4。
4.1.5 改变列表值和列表变化
如果想要改变列表中某个数据呢?那么利用索引就可以做到。因为索引可以提取列表中任意一个值,所以可以将新数据直接赋值给对应索引,如:
>>> spam = ['cat', 'bat', 'rat', 'elephant']
>>> spam[1] = 'aardvark'
>>> spam
['cat', 'aardvark', 'rat', 'elephant']
>>> spam[2] = spam[1]
>>> spam
['cat', 'aardvark', 'aardvark', 'elephant']
>>> spam[-1] = 12345
>>> spam
['cat', 'aardvark', 'aardvark', 12345]例,spam[1] = ‘aardvark’,即将新数据覆盖在原spam[1](即‘bat’)上,以此类推。
之前章节所介绍的“+”和“*”运算符,在列表中也同样适用,效果一致。
del语句表示删除,定义列表索引,运行del语句,就可以删除目标索引的数据,列表中数据-1。
如下:
>>> [1, 2, 3] + ['A', 'B', 'C']
[1, 2, 3, 'A', 'B', 'C']
>>> ['X', 'Y', 'Z'] * 3
['X', 'Y', 'Z', 'X', 'Y', 'Z', 'X', 'Y', 'Z']
>>> spam = [1, 2, 3]
>>> spam = ['cat', 'bat', 'rat', 'elephant']
>>> del spam[2]
>>> spam
['cat', 'bat', 'elephant']
>>> del spam[2]
>>> spam
['cat', 'bat']在此不过多赘述。
4.2 使用列表
4.2.1 引言
使用列表进行程序编写,有诸多方便,例如:想要输入很多猫的名字,最后再全部输出。一般的方法就是一个名字进行一次定义和赋值,最后将多个变量输出,这样如此麻烦,并且这样无法确定需要输入多少名字,不具有随机性。如果用列表来编写的话,就会简单很多,如下:
catNames = []
while True:
print('Enter the name of cat ' + str(len(catNames) + 1) +
' (Or enter nothing to stop.):')
name = input()
if name == '':
break
catNames = catNames + [name] # list concatenation
print('The cat names are:')
for name in catNames:
print(' ' + name)
以上代码中,catNames为猫的名字的列表。while True为无限循环,利用if条件中的break语句跳出循环,避免陷入死循环。定义catNames为空列表,len函数测量它为0,为了进行字符串拼接,将int类型转换为str类型。将输入的name变量加入catNames列表中,列表长度加1。经过循环,将多个名字加入catNames列表中,若输入完毕,则通过if语句判断,输入为空,自动执行if子句,跳出循环,执行print语句和for语句,将列表中的表项依次输出。
由此看出,列表再处理多个输入和输出时,具有很大的优势,将代码复杂程度降低。
4.2.2 列表用于循环
range()函数,在列表的角度来看,它与列表类似。例如range(4)就表示0-3这四个数字,类似于[0,3]。
如果某个列表已经确定了列表中数据的个数,那么可以用len()函数计算长度,再嵌套一个range()函数,即可很准确的调用列表中的每一个数据,即range(len(列表名))。如下:
>>> supplies = ['pens', 'staplers', 'flame-throwers', 'binders']
>>> for i in range(len(supplies)):
... print('Index ' + str(i) + ' in supplies is: ' + supplies[i])
#输出结果:
Index 0 in supplies is: pens
Index 1 in supplies is: staplers
Index 2 in supplies is: flame-throwers
Index 3 in supplies is: binders4.2.3 in 和 not in 操作符
从字面意思来看,in和not in表示“在”和“不在”,而在python中,它们可以检测某个目标对象在不在相应的列表中,返回值由布尔值输出,即True或False。如下:
>>> 'howdy' in ['hello', 'hi', 'howdy', 'heyas']
True
>>> spam = ['hello', 'hi', 'howdy', 'heyas']
>>> 'cat' in spam
False
>>> 'howdy' not in spam
False
>>> 'cat' not in spam
True而布尔值可以作为条件判断语句的条件,例如if语句,所以更多的也可以如下使用:
myPets = ['Zophie', 'Pooka', 'Fat-tail']
print('Enter a pet name:')
name = input()
if name not in myPets:
print('I do not have a pet named ' + name)
else:
print(name + ' is my pet.')由此,可以根据布尔值来通过if语句的判断,去执行相应的if子句,输出对应值。
4.2.4 多重赋值及特殊函数(列表)
用列表对目标对象进行赋值时,不用索引进行一个一个提取再赋值,可以观察目标对象的个数和列表中数据的个数是否一致,如果一致,可以直接将列表赋值给多个对象,默认按照顺序进行赋值,如下:
>>> cat = ['fat', 'black', 'loud']
>>> size, color, disposition = cat
如果目标对象的个数和列表中数据的个数不一致,则无法进行这一操作,会报错。
另外,三个函数也可以跟列表同时使用。
1.enumerate()函数
>>> supplies = ['pens', 'staplers', 'flame-throwers', 'binders']
>>> for i in range(len(supplies)):
... print('Index ' + str(i) + ' in supplies is: ' + supplies[i])
#输出结果:
Index 0 in supplies is: pens
Index 1 in supplies is: staplers
Index 2 in supplies is: flame-throwers
Index 3 in supplies is: binders在上述的代码中,也可以将range(len(supplies))换成enumerate(supplies),因为enumerate函数会返回两个值,一个是当时数据的索引序号(0-3),一个是对应的字符串,相当于原代码中的i和supplies[i]。
2.random.choice函数random.shuffle函数
>>> import random
>>> pets = ['Dog', 'Cat', 'Moose']
>>> random.choice(pets)
'Dog'
>>> random.choice(pets)
'Cat'
>>> random.choice(pets)
'Cat'
>>> people = ['Alice', 'Bob', 'Carol', 'David']
>>> random.shuffle(people)
>>> people
['Carol', 'David', 'Alice', 'Bob']
>>> random.shuffle(people)
>>> people
['Alice', 'David', 'Bob', 'Carol'] random.choice函数是在列表中随机取出一个表项,random.shuffle函数是将列表中的表项顺序打乱,重新排序,并且是覆盖原列表。理解简单,不作解释。
注:choice函数和randint函数有着相同的地方,random.randint函数是随机生成数函数,在0-3直接随机生成数字,放入列表中,即可随机提取表项。
4.3 增强赋值
增强赋值简单来说就是对一些运算进行化简,例如:
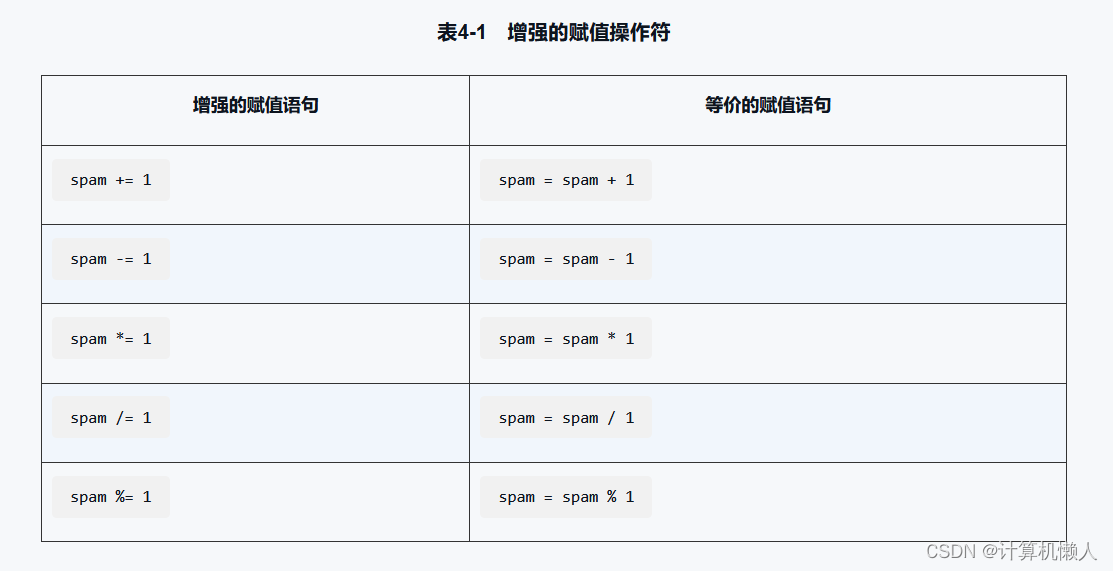
简而言之,就是对运算符的改进,简化代码,如下:
>>> spam = 'Hello,'
>>> spam += ' world!'
>>> spam
'Hello, world!'
>>> bacon = ['Zophie']
>>> bacon *= 3
>>> bacon
['Zophie', 'Zophie', 'Zophie']4.4 方法
方法其实在模板的格式上有些相似,例如:random.choice函数和spam.index,这两者格式差不多,但是意义却不一样。对于random.choice而言,random是一个模板库,choice是其中的一个函数,所以在调用这个函数时,需要提前说明import random;而spam.index不需要,因为spam只是一个变量,index()是数据类型的一个方法。
4.4.1 index()方法
spam变量的index()方法和in操作符很相似,都是判断目标字符是否存在于列表中。index()方法返回目标字符的索引,即序号(例如,0-3),而in操作符是返回布尔值,即True或False。对于大程序而言,index()方法更加适用。如下:
>>> spam = ['hello', 'hi', 'howdy', 'heyas']
>>> spam.index('hello')
0
>>> spam.index('heyas')
3
如果,列表中有两个相同的目标字符,则会返回第一次出现的索引。
4.4.2 append()方法和insert()方法
append()方法和insert()方法都是在列表中添加新的表项,但是两者有着明显的区别。append()方法可以添加表项,但是添加的表项会被自动放在列表得最后一项,如下:
>>> spam = ['cat', 'dog', 'bat']
>>> spam.append('moose')
>>> spam
['cat', 'dog', 'bat', 'moose']这个方法无法确定新表项在列表中的位置,如果需要置换位置的话,还需要进行索引提取置换操作,但是insert()方法可以指定位置。如下:
>>> spam = ['cat', 'dog', 'bat']
>>> spam.insert(1, 'chicken')
>>> spam
['cat', 'chicken', 'dog', 'bat']从格式可以看出,这两个方法有着明显区别。append()方法只有一个参数,就是需要插入的新数据;而insert()方法由两个参数,第一个参数就是插入列表位置的索引值,第二个参数才是新数据。由上述代码看,(1,‘chicken’)的“1”就是插入列表中的位置,即第二个位置;“chicken”就是新数据。两者相比,insert()方法相对更好。
注意,此处进行插入数据操作时,并没有如下代码:
spam = spam.append('moose')
spam = spam.insert(1, 'chicken')因为这两种格式是错误的,简单来说,这个方法操作是将原来的列表进行覆盖了,用新值将旧值覆盖,不存在“=”赋值这一操作。(append()方法和insert()方法的返回值是None,所以如果进行赋值操作,列表将会被删除,结果就会出错,所以不能运行该代码。)
同样,之前说到过,方法是属于数据类型的,并且只属于某一种数据类型,在其他的数据类型中,无法使用。append()方法和insert()方法是属于列表类型的,所以在int和str等其他数据类型中,是错误的。简单理解,不做过多赘述。
4.4.3 remove()方法
在4.1.5中,我们介绍了一个删除语句,del语句。del spam[n],表示删除索引为n的列表表项,同样,这时候介绍的remove()方法也是删除,不过两者参考的目标不一样。remove()方法参考具体的表项值,如下:
>>> spam = ['cat', 'bat', 'rat', 'elephant']
>>> spam.remove('bat')
>>> spam
['cat', 'rat', 'elephant']当不知道要删除的内容的位置时,就可以根据内容进行删除。当然,如果不知道内容,只知道其位置,就可以使用del语句。
另外,如果列表中有两个相同的要删除的表项,那么删除第一次出现的表项。
4.4.4 sort()方法
sort()方法时一种排序操作。对于包含数值和字符串的列表而言,可以用sort()方法进行排序。如下:
>>> spam = [2, 5, 3.14, 1, -7]
>>> spam.sort()
>>> spam
[-7, 1, 2, 3.14, 5]
>>> spam = ['ants', 'cats', 'dogs', 'badgers', 'elephants']
>>> spam.sort()
>>> spam
['ants', 'badgers', 'cats', 'dogs', 'elephants']从中可以看出,sort()方法对于数值来说,是从小到大排序。对于字符串来说是看字符的第一个字符,按照ASCII字符顺序来排序,所以所有小写字母要排在大写字母的后面。如:
>>> spam = ['Alice', 'ants', 'Bob', 'badgers', 'Carol', 'cats']
>>> spam.sort()
>>> spam
['Alice', 'Bob', 'Carol', 'ants', 'badgers', 'cats']当然,如果想要逆向排序的话,只需要将sort()方法那一行换成spam.sort(reverse=True)即可。
另外,就介绍一下reverse()方法。如果想将列表中表象的顺序进行翻转,即可使用spam.reverse()即可,所以sort()方法中逆向排序需要用到reverse。
4.5 示例
当初,在第三章介绍def定义语句的时候,写过一段代码,如下:
import random
def getAnswer(answerNumber):
if answerNumber == 1:
return 'It is certain'
elif answerNumber == 2:
return 'It is decidedly so'
elif answerNumber == 3:
return 'Yes'
elif answerNumber == 4:
return 'Reply hazy try again'
elif answerNumber == 5:
return 'Ask again later'
elif answerNumber == 6:
return 'Concentrate and ask again'
elif answerNumber == 7:
return 'My reply is no'
elif answerNumber == 8:
return 'Outlook not so good'
elif answerNumber == 9:
return 'Very doubtful'
r = random.randint(1, 9)
fortune = getAnswer(r)
print(fortune)当时运用def语句定义一个函数,利用函数进行随机输出。但是现在可以运用列表来写,因为可以把这9个句子全部放在列表中,相当于这每一个句子都是列表的一个表项。新方法如下:
import random
messages = ['It is certain',
'It is decidedly so',
'Yes definitely',
'Reply hazy try again',
'Ask again later',
'Concentrate and ask again',
'My reply is no',
'Outlook not so good',
'Very doubtful']
print(messages[random.randint(0, len(messages) - 1)])像这样,比利用def定义一个新函数要容易得多,复杂度降低很多。代码简单不多作解释。
4.6 序列数据类型
列表并不是唯一表示序列值的数据类型。例如,字符串、由range()返回的范围对象和元组都是序列数据类型。
4.6.1 可变和不可变数据类型
列表和字符串在数据类型上都是序列,但是还有一点不同。列表属于可变数据类型,字符串属于不可变数据类型。前面介绍的append()方法等,都可以对列表进行添加等操作,但是字符串无法被改变,如下:
>>> name = 'Zophie a cat'
>>> name[7] = 'the'
Traceback (most recent call last):
File "<pyshell#50>", line 1, in <module>
name[7] = 'the'
TypeError: 'str' object does not support item assignment
>>> name = 'Zophie a cat'
>>> newName = name[0:7] + 'the' + name[8:12]
>>> name
'Zophie a cat'
>>> newName
'Zophie the cat'
由此看出,想要改变字符串的内容,需要将要的部分留下,其他用新字符替换,加号连接。但是列表的改变却很容易。
除去使用那些方法以外,单纯的对列表多次赋值,也可以改变原列表, 如:
>>> eggs = [1, 2, 3]
>>> eggs = [4, 5, 6]
>>> eggs
[4, 5, 6]对eggs列表多次赋值,原列表的内容就会被新数据覆盖,达到改变列表的效果。
4.6.2 元组数据类型
元组和列表在作用上几乎一致,只是存在两者区别:
1.格式
元组的格式是使用圆括号,即“()”,而列表是方括号,“[]”。
2.可变与否
元组和上面说过的字符串一样,无法被改变。不能用索引赋值改变元组内的内容。如下:
>>> eggs = ('hello', 42, 0.5)
>>> eggs[1] = 99
Traceback (most recent call last):
File "<pyshell#5>", line 1, in <module>
eggs[1] = 99
TypeError: 'tuple' object does not support item assignment可见,元组赋值时会产生错误,所以需要注意,元组不可改变。
另外,如果元组内只有一个值,那么需要加点标志:(‘hello’,)。在第一个值的后面加上逗号,表示后面还有一个虚值(并不存在的);如果不加逗号,就会被定义为字符串类型。
4.6.3 类型转换
list函数和tuple函数:
>>> tuple(['cat', 'dog', 5])
('cat', 'dog', 5)
>>> list(('cat', 'dog', 5))
['cat', 'dog', 5]tuple函数,是把列表转换为元组。list函数,是把元组转换为列表。函数简单,不做解释。
4.7 引用
例如spam变量中保存字符串和数值,是一种存储和赋值的关系。如下:
>>> spam = 42
>>> cheese = spam
>>> spam = 100
>>> spam
100
>>> cheese
42
把42数值存入spam变量中,将spam变量等同于cheese变量,即spam变量内容复制进入cheese变量中,所以cheese变量中是42数值。再次将100数值放入spam变量中,对原先的42数值进行覆盖,即现在spam变量内存储的是100数值。
但是列表和上述两种不同,如下:
>>> spam = [0, 1, 2, 3, 4, 5]
>>> cheese = spam
>>> cheese[1] = 'Hello!'
>>> spam
[0, 'Hello!', 2, 3, 4, 5]
>>> cheese
[0, 'Hello!', 2, 3, 4, 5]从中看出,两个变量都发生了改变。因为此处的“cheese = spam”中不是赋值的意思,而是引用。简单来说,代码中只有一个列表,并没有产生第二个相同的列表,cheese变量中的列表就是引用spam变量中的列表,两者是一个列表。所以在对cheese变量中列表进行替换操作时,spam变量中的列表也会被改变。同时,spam变量中列表也是引用,只是它没有引用的对象,它只引用列表这个内容,如下图:
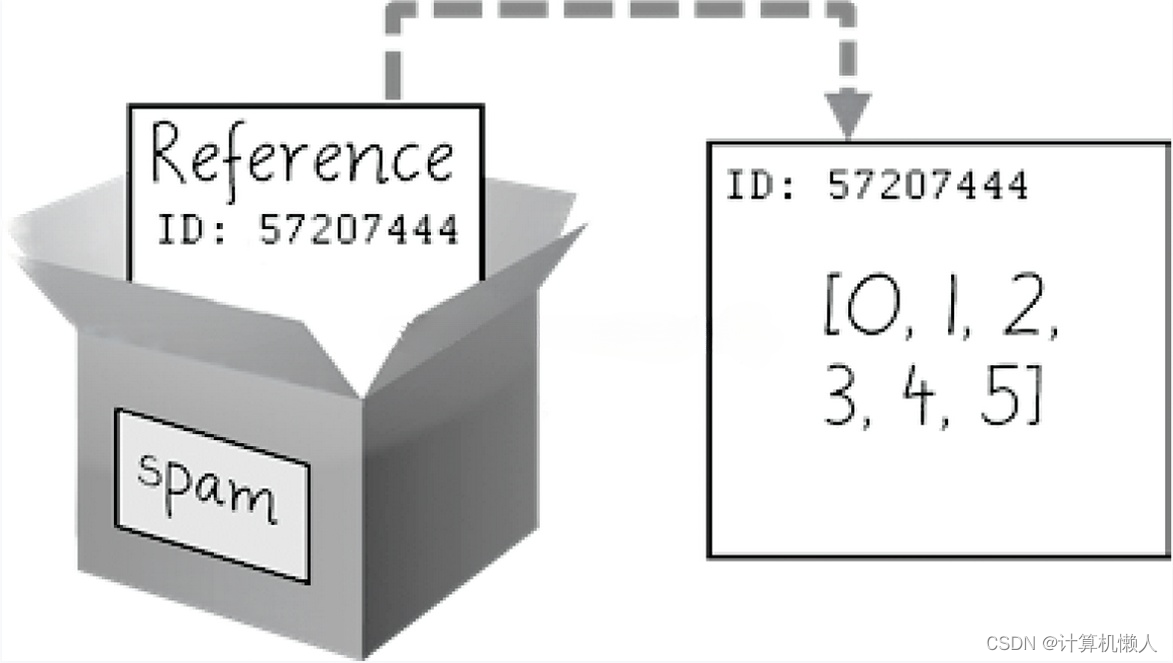
可以看出,spam变量中类似保存了一个号码,而这个号码就像是一个链接,连接到数据。而这就是引用,spam变量指向一个列表,即引用列表。后面代码同理。
4.7.1 标识和id()函数
id()函数是用来返回目标的标识,所谓标识,可以理解为储存目标的地址。而在python中,每一个值都对应一个唯一的标识。如下:
>>> bacon = 'Hello'
>>> id(bacon)
44491136
>>> bacon += ' world!' # A new string is made from 'Hello' and 'world!'.
>>> id(bacon) # bacon now refers to a completely different string.
44609712
由此,两次输出都是bacon变量,但是它们的标识并不一样,说明它们已经是两个不同的了。系统会根据字符串的长度来决定,将字符串储存在哪个地方。而列表却不一样,如下:
>>> eggs = ['cat', 'dog'] # This creates a new list.
>>> id(eggs)
35152584
>>> eggs.append('moose') # append() modifies the list "in place".
>>> id(eggs) # eggs still refers to the same list as before.
35152584
>>> eggs = ['bat', 'rat', 'cow'] # This creates a new list, which has a new identity.
>>> id(eggs) # eggs now refers to a completely different list.
44409800
我们知道,列表在变量之间存在引用关系,而引用关系代表不会存在第二个列表,而是同一个列表。所以用append()方法等对列表进行改变时,都是对同一个列表进行“原地”改动,所以前后的地址是一样的。
4.7.2 传递引用
如下代码:
def eggs(someParameter):
someParameter.append('Hello')
spam = [1, 2, 3]
eggs(spam)
print(spam)运行结果则是,[1,2,3,hello]。在def定义语句中,存在someParameter变元,而在主函数中,spam变量代表一个列表,同时也表示spam引用了列表。而变元,则是引用的复制。虽然两个变量是不同的引用,但是二者同样都代表了一个列表。所以对其中一个变量进行操作时,另一个变量也会被同时改变。
4.7.3 copy模块的相关函数
介绍了传递引用,但是有的时候不希望改变一个变量时,也影响另一个变量,这该如何?
运行copy模块的copy函数即可。
>>> import copy
>>> spam = ['A', 'B', 'C', 'D']
>>> id(spam)
44684232
>>> cheese = copy.copy(spam)
>>> id(cheese) # cheese is a different list with different identity.
44685832
>>> cheese[1] = 42
>>> spam
['A', 'B', 'C', 'D']
>>> cheese
['A', 42, 'C', 'D']对两个变量进行id()函数运行后,得到两个变量的地址信息,可以看出这两个变量的地址并不一样,说明这两个变量不是相同的。但是我们了解,列表只有一个,并且没有进行改变,为何地址会有两种?显而易见,是copy.copy函数对spam变量进行了复制,将一个可变量复制成了cheese变量。再对cheese变量进行操作,发现仅仅是cheese变量的列表发生了改变,spam列表没有改变,这就说明,已经从一个列表,变成了两个相同但无关的列表,对cheese变量的操作,不会影响到spam变量,完成目标要求。
当然,如果原列表是一个复合列表,即列表中包含列表,则可以使用copy.deepcopy()函数。
4.8 康威生命游戏
康威生命游戏,是英国数学家约翰·何顿·康威于1970年提出的一种计算机程序。下面则简单介绍康威生命游戏的主要内容:
开始时,每个细胞随机地设定为“生”或“死”之一的某个状态。然后,根据某种规则,计算出下一代每个细胞的状态,画出下一代细胞的生死分布图。
为简单起见,最基本的考虑是假设每一个细胞都遵循完全一样的生存定律;再进一步,把细胞之间的相互影响只限制在最靠近该细胞的8个邻居中。也就是说,每个细胞迭代后的状态由该细胞及周围8个细胞状态所决定。在康威的生命游戏中,规定了如下生存定律:
1.当前细胞为死亡状态时,当周围正好有3个存活细胞时,则迭代后该细胞变成存活状态;若原先为生,则保持不变。
2.当前细胞为存活状态时,当周围的邻居细胞小于等于1个存活时,该细胞变成死亡状态。
3.当前细胞为存活状态时,当周围有2个或3个存活细胞时,该细胞保持原样。
4.当前细胞为存活状态时,当周围有3个以上的存活细胞时,该细胞变成死亡状态。
可以把最初的细胞结构定义为种子,当所有种子细胞按以上规则处理后,可以得到第1代细胞图。按规则继续处理当前的细胞图,可以得到下一代的细胞图,周而复始。
如下图,就是康威生命游戏的简单迭代:
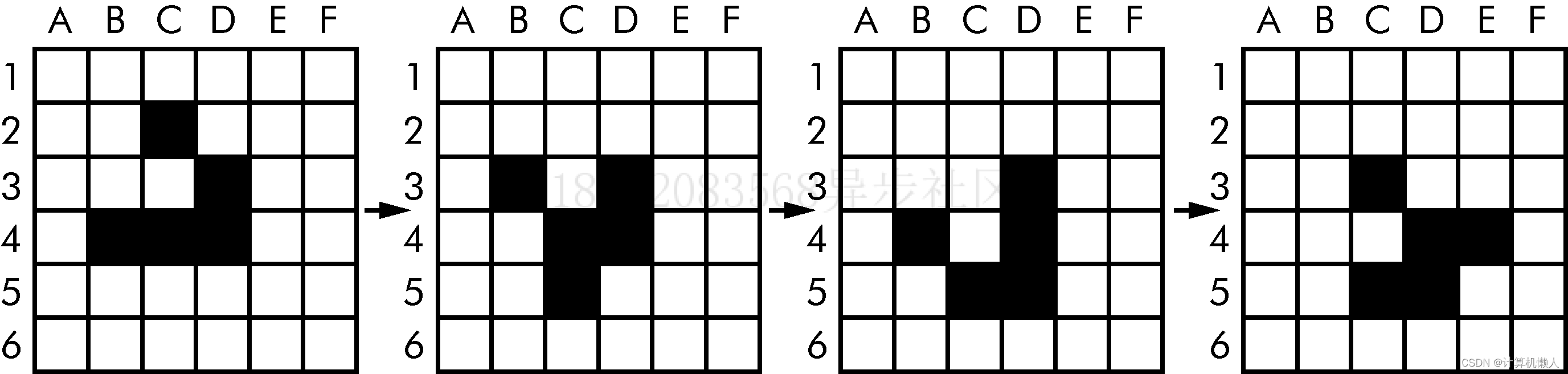
先来对第一代细胞图进行分析:
1.1行中,每个死细胞最多只与一个活细胞相邻,所以细胞维持死亡状态。
2.2C,它的周围只有右下角存在活细胞,所以下一阶段转变死细胞。
3.在2行中,2B,2E与一个活细胞相邻,2D是两个活细胞相邻,皆不符合转变条件。
4.3A是1个相邻,3B是3个,3C是5个,3E是2个,3F是0个。由此看出只有3B符合条件,转变成活细胞;3D是3个相邻,保持活性。
5.4A,4E是1个,4F是0个,都不符合,维持死亡;4B是1个,4C是3个,4D是2个,所以4B要转变死亡,其他维持活性。
6.5行全是死细胞,且只有5C有3个活细胞相邻,则5C转变活细胞,其他维持死亡。
7.6行,没有与活细胞相邻,全部维持死亡。
而第二代细胞图也是如此,根据规则转变。下面,将对此规则用代码展示,如下:
import random, time, copy
WIDTH = 60
HEIGHT = 20
# Create a list of list for the cells:
nextCells = []
for x in range(WIDTH):
column = [] # Create a new column.
for y in range(HEIGHT):
if random.randint(0, 1) == 0:
column.append('#') # Add a living cell.
else:
column.append(' ') # Add a dead cell.
nextCells.append(column) # nextCells is a list of column lists.
while True: # Main program loop.
print('\n\n\n\n\n') # Separate each step with newlines.
currentCells = copy.deepcopy(nextCells)
# Print currentCells on the screen:
for y in range(HEIGHT):
for x in range(WIDTH):
print(currentCells[x][y], end='') # Print the # or space.
print() # Print a newline at the end of the row.
# Calculate the next step's cells based on current step's cells:
for x in range(WIDTH):
for y in range(HEIGHT):
# Get neighboring coordinates:
# `% WIDTH` ensures leftCoord is always between 0 and WIDTH - 1
leftCoord = (x - 1) % WIDTH
rightCoord = (x + 1) % WIDTH
aboveCoord = (y - 1) % HEIGHT
belowCoord = (y + 1) % HEIGHT
# Count number of living neighbors:
numNeighbors = 0
if currentCells[leftCoord][aboveCoord] == '#':
numNeighbors += 1 # Top-left neighbor is alive.
if currentCells[x][aboveCoord] == '#':
numNeighbors += 1 # Top neighbor is alive.
if currentCells[rightCoord][aboveCoord] == '#':
numNeighbors += 1 # Top-right neighbor is alive.
if currentCells[leftCoord][y] == '#':
numNeighbors += 1 # Left neighbor is alive.
if currentCells[rightCoord][y] == '#':
numNeighbors += 1 # Right neighbor is alive.
if currentCells[leftCoord][belowCoord] == '#':
numNeighbors += 1 # Bottom-left neighbor is alive.
if currentCells[x][belowCoord] == '#':
numNeighbors += 1 # Bottom neighbor is alive.
if currentCells[rightCoord][belowCoord] == '#':
numNeighbors += 1 # Bottom-right neighbor is alive.
# Set cell based on Conway's Game of Life rules:
if currentCells[x][y] == '#' and (numNeighbors == 2 or numNeighbors == 3):
# Living cells with 2 or 3 neighbors stay alive:
nextCells[x][y] = '#'
elif currentCells[x][y] == ' ' and numNeighbors == 3:
# Dead cells with 3 neighbors become alive:
nextCells[x][y] = '#'
else:
# Everything else dies or stays dead:
nextCells[x][y] = ' '
time.sleep(1) # Add a 1 second pause to reduce flickering.
下面将用代码进行分析:
首先是引入模块,当然,在没写程序的时候不知道要用到什么模块函数,所以可以在编写函数时,在第一行import后,将用到函数所属的模块添加。接下来,定义细初始化胞图的宽和高,width和height。
下面,定义一个大列表nextCells,它是一个完整的细胞图,表示20行,60列的分布图。由于第一代细胞图的来源细胞图是随机生成的,所以使用random.randint()函数随机生成。对于初始细胞图,我们使用两层循环以此定位细胞图中每个细胞的位置,对每个细胞进行“生死”初始化。而“生死”由随机函数确定:在0,1中随机选择并判断与目标数字(0或1任选)是否一致,得出布尔值,进而if语句判断,将“生死”转化为符号。利用append()方法,对符号进行插入小列表,此时的小列表储存的是第一列(一共60列)的细胞存活状态,将小列表以此再插入大列表,此时的大列表储存的是整个细胞图的存活状态。
接下来就要设定一个循环,以True为条件进行无限循环,由初始到第一代,由第一代到第二代,依次继续。在这个循环中,首先利用copy模块中的deepcopy函数对nextCells进行复制,因为不能对初始细胞图进行修改,所以要重新复制一个一样的列表,对这个列表进行修改。在修改之前,先输出细胞图,写出print函数。
下面就要进行条件的判定了,由于每个细胞的存活都由旁边的8个细胞决定,所以我们需要知道8给细胞的存活情况,而8个细胞的索引就是第一步。
for x in range(WIDTH):
for y in range(HEIGHT):
# Get neighboring coordinates:
# '% WIDTH' ensures leftCoord is always between 0 and WIDTH - 1
leftCoord = (x - 1) % WIDTH
rightCoord = (x + 1) % WIDTH
aboveCoord = (y - 1) % HEIGHT
belowCoord = (y + 1) % HEIGHT将代码单独拿出来看,因为是二维列表,所以查找索引需要两个循环。8个方位,需要4个大方向变量(上下左右)。而%width是为了环绕,因为第一行的细胞还需要参照最后一行的细胞,第一列的洗白还要参照最后一列的细胞,所以使用%求余,形成一个环形。
8个细胞位置确定,即可提取存活情况,对8个中存活细胞进行计数:通过if语句,与存活标记(“#”)对比,如果是活细胞,则加1。最后计数的活细胞数量,与迭代条件比对,即可得到一个细胞的下代情况,以此类推,即可得到下代细胞图。
在所有细胞迭代完后,进入sleep函数,暂停1秒,再次进行重复操作。
4.9 小结
列表在python运用中,有着非常大的作用,它和C++中的数组是同一个概念。列表和元组相似,但列表可以被改变,元组不行。当然,如果你不想原来的列表被改变,拿可以使用copy()函数等,复制一个新的列表。
4.10 课后习题选讲
4.10.1

答:spam[2] = ‘hello’。
4.10.2

答:‘d’ ;‘d’ ;[‘a‘,’b‘]。(内容见4.1)
4.10.3

答:1;[3.14, 'cat', 11, 'cat', True, 99];[3.14, 11, 'cat', True]
注:remove()方法在删除表项时,若目标对象在列表中有另外相同项,则删除索引最前的项。(其他请看4.4)
4.10.4

答:append()方法只会将值添加在列表末尾,而 insert()方法可以将值添加在列表的任何位置。
4.10.5

答:1.列表和字符串都可以传入 len()函数,都有索引和切片,用于 for 循环、连接或复制, 并可与 in 和 not in 操作符一起使用。2.列表是可以修改的,它们可以添加值、删除值和修改值。元组是不可修改的,它们根本不能改变。而且,元组使用的是括号(和),而列表使用的是方括号 [和]。
4.10.6

答:(42,)
注:逗号是关键,如果不加就会变成字符串。
4.11 实践活动
4.11.1 逗号代码

参考代码:
def douhao(spam):
a = ''
for i in range(0,len(spam)):
if i == len(spam)-2 :
a += spam[i] + ', and '
elif i < len(spam)-2 :
a += spam[i] + ', '
else:
a += spam[i] + ''
return a
spam = ['a','s','d','f','g']
i = douhao(spam)
print(i)4.11.2 掷硬币的连胜
参考代码(有疑虑):
import random
numberOfStreaks = 0
spam = []
for experimentNumber in range(10000):
for i in range(100):
a = random.randint(0,1)
spam.append(a)
for j in range(94):
if spam[j] == spam[j+1] == spam[j+2] == spam[j+3] == spam[j+4] == spam[j+5]:
numberOfStreaks += 1
print('Chance of streak : %s%%' % (numberOfStreaks / 10000 /100 ))
4.11.3 字符图网格
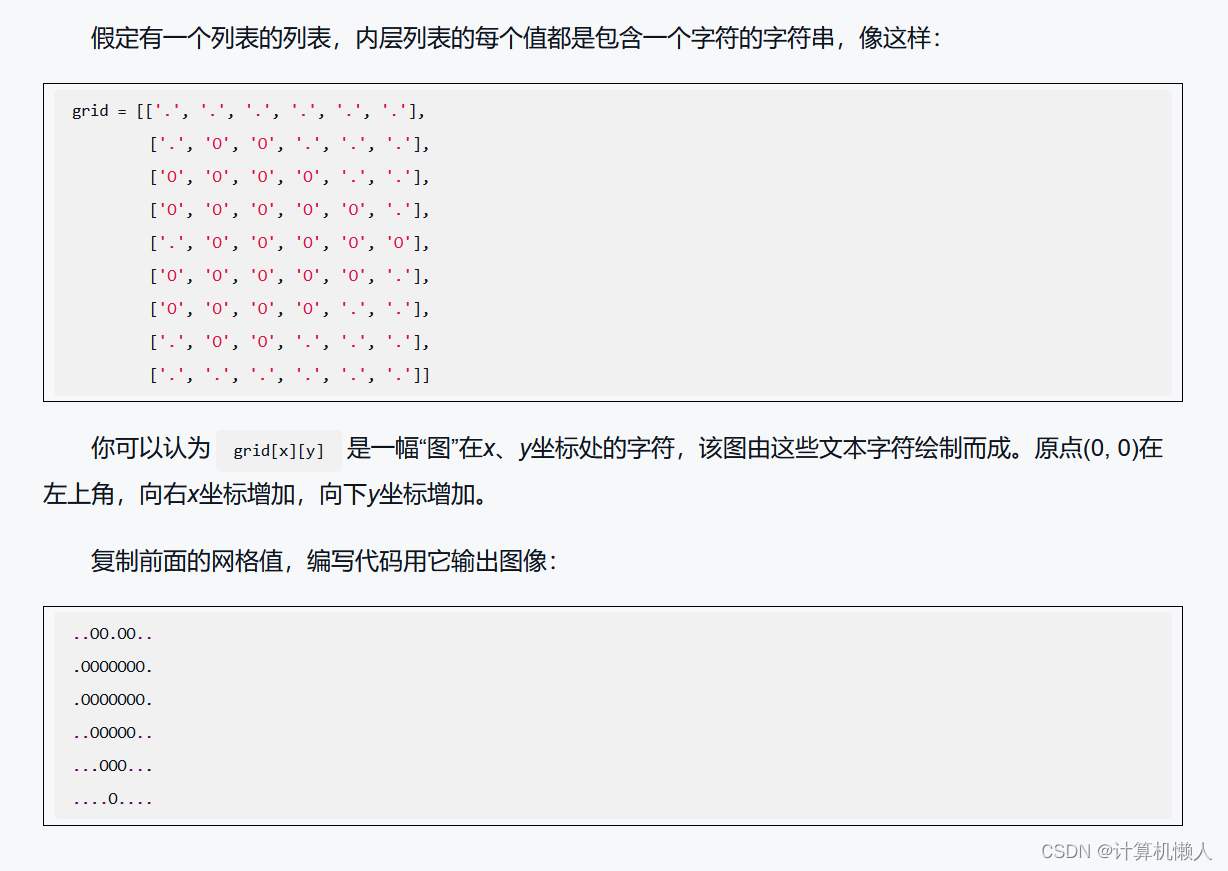
参考代码:
# 假设列表为gril
grid = [
['.', '.', '.', '.', '.', '.'],
['.', '0', '0', '.', '.', '.'],
['0', '0', '0', '0', '.', '.'],
['0', '0', '0', '0', '0', '.'],
['.', '0', '0', '0', '0', '0'],
['0', '0', '0', '0', '0', '.'],
['0', '0', '0', '0', '.', '.'],
['.', '0', '0', '.', '.', '.'],
['.', '.', '.', '.', '.', '.']
]
for i in range(6):
for j in range(9):
print(grid[j][i], end="")
print()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











