







 本文介绍了Scrapy爬虫框架,强调其高效、组件丰富及异步架构。主要部分涵盖了ScrapyEngine、Scheduler、Downloader、Spiders、ItemPipeline和中间件的作用。Scrapy不仅限于网络爬虫,还适用于数据挖掘和自动化测试。
本文介绍了Scrapy爬虫框架,强调其高效、组件丰富及异步架构。主要部分涵盖了ScrapyEngine、Scheduler、Downloader、Spiders、ItemPipeline和中间件的作用。Scrapy不仅限于网络爬虫,还适用于数据挖掘和自动化测试。
第十七章 Scrapy爬虫框架
17.1 了解Scrapy
使用Requests与其他HTML解析库所实现的爬虫程序,只是满足了爬取数据的需求。如果想要更加规范地爬取数据,则需要使用爬虫框架。爬虫框架有很多种,例如PySpider、Crawley等。而Scrapy爬虫框架则是一个爬取效率高、相关扩展组件多、可以让程序员将精力全部投入抓取规则以及处理数据上的一款优秀框架。Scrapy是一个可以爬取网站数据、提取结构性数据而编写的开源框架。Scrapy的用途非常广泛,不仅可以应用到网络爬虫,还可以用于数据挖掘、数据监测以及自动化测试等。Scrapy是基于Twisted的异步处理框架,架构清晰、可扩展性强,可以灵活地完成各种需求。
Scrapy的工作框架如下:
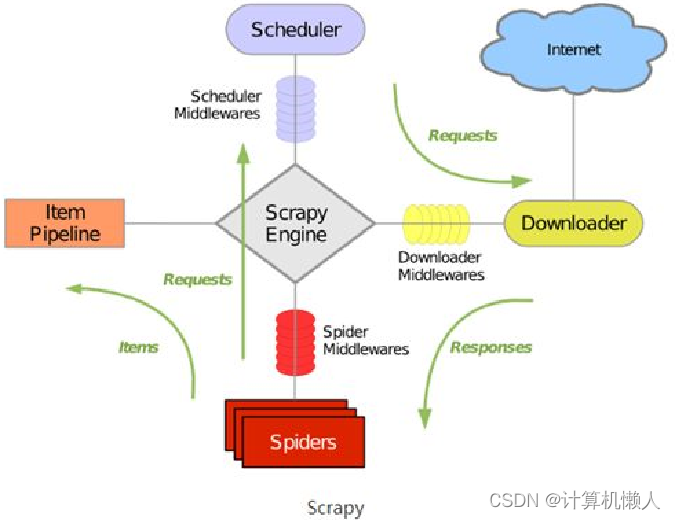
图片关系复杂,简要的概括为以下几个主要内容:
Scrapy Engine(框架的引擎):用于处理整个系统的数据流,触发各种事件,是整个框架的核心。
Scheduler(调度器):用于接受引擎发过来的请求,将之添加至队列中,并在引擎再次请求时将请求返回给引擎。可以理解为从URL队列中取出一个请求地址,同时去除重复的请求地址。
Downloader(下载器):用于从网络下载Web资源。
Spiders(网络爬虫):从指定网页中爬取需要的信息。
Item Pipeline(项目管道):用于实现处理爬取后的数据,例如数据的清洗、验证以及保存。
Downloader Middlewares(下载器中间件):位于Scrapy引擎和下载器之间,主要用于处理引擎与下载器之间的网络请求与响应。
Spider Middlewares(爬虫中间件):位于爬虫与引擎之间,主要用于处理爬虫的响应输入和请求输出。
Scheduler Middewares(调度中间件):位于引擎和调度之间,主要用于处理从引擎发送到调度的请求和响应。
(注:Scrapy框架搭建省略。)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











